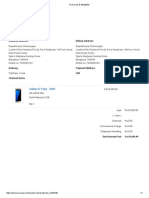
Download as pdf or txt
You might also like
- Bohemian Grove Full Member List LEAK 2023Document13 pagesBohemian Grove Full Member List LEAK 2023twisteddick100% (1)
- Question 1 (1 Point)Document44 pagesQuestion 1 (1 Point)milanchabhadiya288No ratings yet
- Fiat Doblo Cargo Workshop Manual PDFDocument2 pagesFiat Doblo Cargo Workshop Manual PDFsalih pişkin0% (9)
- PEP-8 Tutorial - Code Standards in Python PDFDocument20 pagesPEP-8 Tutorial - Code Standards in Python PDFPavankumar KaredlaNo ratings yet
- Calling Functions in The InterpreterDocument3 pagesCalling Functions in The Interpretermark karlNo ratings yet
- Module 1 Important Questions With AnswersDocument8 pagesModule 1 Important Questions With Answers21S0552 NavyashriNo ratings yet
- ElnurDocument4 pagesElnurIrelia LoverNo ratings yet
- Krishna Priya April 19, 2011 C-DAC, HyderabadDocument28 pagesKrishna Priya April 19, 2011 C-DAC, Hyderabadhappy dobhalNo ratings yet
- Post 64Document15 pagesPost 64khanmusfera32No ratings yet
- Midterm 2 ReviewDocument3 pagesMidterm 2 Reviewtravel.earth.wloveNo ratings yet
- C++ Project InfoDocument3 pagesC++ Project InfoD.BalaganeshNo ratings yet
- C Programming Viva Questions and Answers: 1. What Is A Pointer On Pointer?Document9 pagesC Programming Viva Questions and Answers: 1. What Is A Pointer On Pointer?Smart IrrigationNo ratings yet
- Apple Script Language GuideDocument315 pagesApple Script Language GuidecoderamaNo ratings yet
- Lab-01-Introduction To Python (133-20-0005)Document9 pagesLab-01-Introduction To Python (133-20-0005)Kashaf Ali Haroon Yousaf HaroonNo ratings yet
- BNK464 Sept 20 CW BriefDocument8 pagesBNK464 Sept 20 CW BriefsadNo ratings yet
- BNK464 Sept 20 CW BriefDocument8 pagesBNK464 Sept 20 CW BriefsadNo ratings yet
- To TT Change Detector TestsDocument1 pageTo TT Change Detector TestsAlan WolfeNo ratings yet
- Lec 4 - FunctionsDocument35 pagesLec 4 - FunctionsZane TechNo ratings yet
- P 1Document4 pagesP 1Anonymous UrzdtCB0INo ratings yet
- En - Subject.04 CPP Mod06 7Document9 pagesEn - Subject.04 CPP Mod06 7jmolfigueiraNo ratings yet
- Test-Driven APIs With Laravel and Pest Sample ChapterDocument32 pagesTest-Driven APIs With Laravel and Pest Sample ChapterJendela KayuNo ratings yet
- PHP Coding Standard StandardsDocument6 pagesPHP Coding Standard StandardskvsubinNo ratings yet
- Lab - 01 - CS171Document10 pagesLab - 01 - CS171Sai MusunuriNo ratings yet
- PP manualDocument35 pagesPP manualmeripubgid1No ratings yet
- SAU TERM 1 3 1variantDocument3 pagesSAU TERM 1 3 1variantIrelia LoverNo ratings yet
- 4 - Comments and AssignmentDocument3 pages4 - Comments and AssignmentAlamin sarkerNo ratings yet
- Advance Web TechnologyDocument32 pagesAdvance Web TechnologySujith N100% (3)
- Group 11 Presentation 1Document53 pagesGroup 11 Presentation 1camilabinas4No ratings yet
- Assembly Language Fundamentals: Javeria AminDocument42 pagesAssembly Language Fundamentals: Javeria AminAtiqa SafdarNo ratings yet
- Assignment 5: Raw Memory: Bits and BytesDocument6 pagesAssignment 5: Raw Memory: Bits and BytesnikNo ratings yet
- lesson2-pythonDocument18 pageslesson2-pythonmoamenadel199No ratings yet
- Assignment 5 New-2018Document5 pagesAssignment 5 New-2018Ali HassanNo ratings yet
- PHP 1Document12 pagesPHP 1learningNo ratings yet
- Top 100 + C Programming Interview Questions & AnswersDocument23 pagesTop 100 + C Programming Interview Questions & AnswersPrasanna kumar MsNo ratings yet
- Assignment 1: COMP202, Winter 2021 Due: Friday, Feb. 12, 11:59pmDocument12 pagesAssignment 1: COMP202, Winter 2021 Due: Friday, Feb. 12, 11:59pmSachinthaNo ratings yet
- Linux Commands PracticalDocument26 pagesLinux Commands PracticalRavi VermaNo ratings yet
- Chapter 01 To 06Document7 pagesChapter 01 To 06Mosharaf HossainNo ratings yet
- AWP Module2 PHPDocument26 pagesAWP Module2 PHPpoojaNo ratings yet
- Salesforce JavaScript Developer 1 - Practice Tests + Explns - 1Document137 pagesSalesforce JavaScript Developer 1 - Practice Tests + Explns - 1juzenyoliveiramontNo ratings yet
- Java NotesDocument20 pagesJava NotesgokuNo ratings yet
- Model Question Papers SolutionDocument39 pagesModel Question Papers SolutionVinayaka Gombi100% (3)
- Python DebuggingDocument32 pagesPython Debuggingbewosi4132No ratings yet
- QuestionsDocument12 pagesQuestionsVenkatramana ReddicherlaNo ratings yet
- UNIX Shell ScriptDocument32 pagesUNIX Shell Scriptpooja112846349100% (1)
- Chapter 2 - Functions in Python NEWDocument58 pagesChapter 2 - Functions in Python NEWkratika GargNo ratings yet
- DSD AssignmentsDocument1 pageDSD AssignmentsCREC HODNo ratings yet
- Arithmetic OperatorsDocument12 pagesArithmetic Operatorsareejamir.23.4.2008No ratings yet
- Python Unit-1Document27 pagesPython Unit-1hollowpurple156No ratings yet
- Session11 06april2023 ClassDocument49 pagesSession11 06april2023 ClassMuskan AnejaNo ratings yet
- Intro To Python SIMP - Simp QBDocument3 pagesIntro To Python SIMP - Simp QBShalem JeldiNo ratings yet
- Compiler Design Notes.Document22 pagesCompiler Design Notes.Debasish DebnathNo ratings yet
- Memory GuideDocument317 pagesMemory GuideIgnacio OronáNo ratings yet
- CS111 Lab Test 1 (5%)Document3 pagesCS111 Lab Test 1 (5%)Rahul NarayanNo ratings yet
- I. Interactive Mode Versus Script ModeDocument8 pagesI. Interactive Mode Versus Script ModeReedNo ratings yet
- Tutorial 4: Ppe 309L-Process Engineering Computing Lab Fall-2020-5Th SemesterDocument6 pagesTutorial 4: Ppe 309L-Process Engineering Computing Lab Fall-2020-5Th SemesterAli HassanNo ratings yet
- Computer JavaDocument3 pagesComputer JavaShaurya SawantNo ratings yet
- PHP Tutorial From Beginner To MasterDocument28 pagesPHP Tutorial From Beginner To MasterRubal BhatiaNo ratings yet
- Python Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreFrom EverandPython Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreNo ratings yet
- Python programming for beginners: Python programming for beginners by Tanjimul Islam TareqFrom EverandPython programming for beginners: Python programming for beginners by Tanjimul Islam TareqNo ratings yet
- ORACLE PL/SQL Interview Questions You'll Most Likely Be AskedFrom EverandORACLE PL/SQL Interview Questions You'll Most Likely Be AskedRating: 5 out of 5 stars5/5 (1)
- Hospitals Emails PKDocument4 pagesHospitals Emails PKEngr Hamid AliNo ratings yet
- Catalog MotoreductoareDocument20 pagesCatalog MotoreductoareNitzu Holhorea CornelNo ratings yet
- Water Tank Design CalcDocument5 pagesWater Tank Design CalcUttam Kumar Ghosh100% (1)
- Contoh PPT Seminar Proposal PbiDocument35 pagesContoh PPT Seminar Proposal Pbidinda mawaddahNo ratings yet
- District Profile ThattaDocument52 pagesDistrict Profile ThattaUrooj Fatima100% (1)
- Somatoform Disorders in DSM SoalDocument6 pagesSomatoform Disorders in DSM SoalNurlita trianiNo ratings yet
- Specifications For Lime Slurry Injection For Ground ImprovementDocument5 pagesSpecifications For Lime Slurry Injection For Ground ImprovementSrini BaskaranNo ratings yet
- A Case Study of Exploiting Data Mining TechniquesDocument8 pagesA Case Study of Exploiting Data Mining TechniquesAdam GraphiandanaNo ratings yet
- P To P CycleDocument5 pagesP To P CycleJaved AhmadNo ratings yet
- Acs42 Config GuideDocument214 pagesAcs42 Config GuideOtia ObaNo ratings yet
- S7 Edge Invoice PDFDocument1 pageS7 Edge Invoice PDFRajesh KumarNo ratings yet
- Training Staff IDDocument14 pagesTraining Staff IDRS DulayNo ratings yet
- Fire Awareness PresentationDocument37 pagesFire Awareness Presentationshailu178No ratings yet
- Soft Drinks Industry ProfileDocument8 pagesSoft Drinks Industry ProfileAnukrishnaNo ratings yet
- Electromagnetic Shielding Salvatore Celozzi Full ChapterDocument56 pagesElectromagnetic Shielding Salvatore Celozzi Full Chapternorma.catron566100% (10)
- Business Card Dungeon DelveDocument2 pagesBusiness Card Dungeon DelveTomás Heurtley0% (1)
- Ex-Probation Chief Takes Stand To Defend Child Porn: Ppoossttaall PprroobblleemmDocument28 pagesEx-Probation Chief Takes Stand To Defend Child Porn: Ppoossttaall PprroobblleemmSan Mateo Daily JournalNo ratings yet
- Why Business Models MatterDocument7 pagesWhy Business Models MatterdaliyaNo ratings yet
- (Guide) (How To Port Roms) (Snapdragon) (Window - Android Development and HackingDocument1 page(Guide) (How To Port Roms) (Snapdragon) (Window - Android Development and HackingJus RajNo ratings yet
- Mansi Mba Sip Report PDFDocument85 pagesMansi Mba Sip Report PDFAmul PatelNo ratings yet
- Java Practical FileDocument84 pagesJava Practical FileDivyangnaNo ratings yet
- VIT Wow - CFD - AssignementDocument4 pagesVIT Wow - CFD - AssignementShashank AminNo ratings yet
- Kyma Ship Performance: Trial Report: Vessel: Voyage: Report Period ToDocument3 pagesKyma Ship Performance: Trial Report: Vessel: Voyage: Report Period TosaeshwaranNo ratings yet
- Stay Where You Are' For 21 Days: Modi Puts India Under LockdownDocument8 pagesStay Where You Are' For 21 Days: Modi Puts India Under LockdownshivendrakumarNo ratings yet
- Sampling PDFDocument45 pagesSampling PDFYousuf AdamNo ratings yet
- Tefal Kitchen Machine Users ManualDocument18 pagesTefal Kitchen Machine Users ManualMartinaNo ratings yet
- Circular Functions PDFDocument2 pagesCircular Functions PDFShane RajapakshaNo ratings yet