
Statystyka
Statystyka
You might also like
- Statystyka Opisowa W Zadaniach PDFDocument159 pagesStatystyka Opisowa W Zadaniach PDFKasia KulkaNo ratings yet
- Statystyka - NotatkiDocument6 pagesStatystyka - NotatkiIza GrzebakNo ratings yet
- Statystyka Wykłady OpisDocument13 pagesStatystyka Wykłady OpisAnna KośmiderNo ratings yet
- Wyk. - Wprowadzenie Do Analizy Danych SpołecznychDocument5 pagesWyk. - Wprowadzenie Do Analizy Danych SpołecznychMarta KramerNo ratings yet
- Jermakowicz 24032024144219 Statystyka 2Document41 pagesJermakowicz 24032024144219 Statystyka 2ewa kedzioraNo ratings yet
- Pojęcia Statystyczne1Document9 pagesPojęcia Statystyczne1Anna KośmiderNo ratings yet
- METODA REPREZENTACYJNA DrukDocument5 pagesMETODA REPREZENTACYJNA DrukOla GorskaNo ratings yet
- Laboratorium 4 Statystyka StatisticaDocument16 pagesLaboratorium 4 Statystyka StatisticaPipek PipekejNo ratings yet
- Statystyka WykładyDocument17 pagesStatystyka WykładyAnna KośmiderNo ratings yet
- Zasoby Wykład 1Document15 pagesZasoby Wykład 1OlaNo ratings yet
- Statystyka Opisowa 1Document47 pagesStatystyka Opisowa 1Marcelina ŁobodaNo ratings yet
- Wykład 1Document114 pagesWykład 1FilipNo ratings yet
- STAT - Wprowadzanie Danych - 2Document24 pagesSTAT - Wprowadzanie Danych - 2Natalia WróbelNo ratings yet
- Teoria-Statystyka MatematycznaDocument19 pagesTeoria-Statystyka Matematycznakrzysiu101No ratings yet
- Jermakowicz 05042024110036 Statystyka 4Document41 pagesJermakowicz 05042024110036 Statystyka 4ewa kedzioraNo ratings yet
- Analiza DyskryminacyjnaDocument13 pagesAnaliza DyskryminacyjnaBobiOneeNo ratings yet
- Problem BadawczyDocument9 pagesProblem BadawczyJulia DrosińskaNo ratings yet
- Statystyka 2Document6 pagesStatystyka 2maciej-onuchowskiNo ratings yet
- Skrypt Podręcznik MetodyDocument59 pagesSkrypt Podręcznik Metodyklaudiunia2215No ratings yet
- Final Boss StatystykaDocument18 pagesFinal Boss Statystykakncfzz4rcjNo ratings yet
- Statystyka WykładDocument21 pagesStatystyka Wykładweronika.latala59No ratings yet
- 2023 01 Statystyki Opisowe I Normalnosc RozkladuDocument3 pages2023 01 Statystyki Opisowe I Normalnosc RozkladuJustyna WcisłoNo ratings yet
- Estymacja - Materiały Do ĆwiczeńDocument6 pagesEstymacja - Materiały Do ĆwiczeńFilipNo ratings yet
- SPSS - Opis Zadań GWSH Psychologia ĆW 3 Zad.2 OpisDocument21 pagesSPSS - Opis Zadań GWSH Psychologia ĆW 3 Zad.2 OpismaciekbokuNo ratings yet
- Statystyczne Opracowanie Danych PomiarowychDocument16 pagesStatystyczne Opracowanie Danych Pomiarowychnotatki.chemiakNo ratings yet
- MetodologiaDocument3 pagesMetodologiaWiktoria GawlikNo ratings yet
- Wyklad 10 Elementy Statysytki OpisowejDocument18 pagesWyklad 10 Elementy Statysytki OpisowejAneta WróblewskaNo ratings yet
- CentylDocument18 pagesCentyljustynaturowska57No ratings yet
- Notatki NaDocument10 pagesNotatki NaMadleneNo ratings yet
- Statystyka PodstawyDocument27 pagesStatystyka PodstawyDawid PękałaNo ratings yet
- EstymacjaDocument32 pagesEstymacjaNadia DanylickaNo ratings yet
- Porównanie Dwóch GrupDocument5 pagesPorównanie Dwóch Grupartem4907No ratings yet
- StatystykaDocument38 pagesStatystykaWiktoriaNo ratings yet
- Psychometria NotatkiDocument41 pagesPsychometria NotatkiNate XxxNo ratings yet
- Metody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Document26 pagesMetody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Ewa ZalewskaNo ratings yet
- Rozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieDocument9 pagesRozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieOlaNo ratings yet
- SPSSDocument37 pagesSPSSlizaNo ratings yet
- Statytyka MateriałyDocument29 pagesStatytyka Materiałyjuliakunaszyk44No ratings yet
- Statystyka PracaDocument26 pagesStatystyka PracaDagmara OwocNo ratings yet
- Lab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychDocument10 pagesLab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychYehor MalakhovNo ratings yet
- StatystykaDocument17 pagesStatystykaskubis.juliannaNo ratings yet
- Combining ClassifiersDocument22 pagesCombining ClassifiersMichal SiemaszkiewiczNo ratings yet
- StatystykaDocument4 pagesStatystykalescopainsdeoufNo ratings yet
- Analiza Statystyczna Dla Psychologów (Wykład)Document5 pagesAnaliza Statystyczna Dla Psychologów (Wykład)xxxmxx xNo ratings yet
- Statystyka Matematyczna 2023 2024Document56 pagesStatystyka Matematyczna 2023 2024dziarczykowskaNo ratings yet
- Jakosc ZyciaDocument20 pagesJakosc ZyciaKNo ratings yet
- Statystyka Opisowa Można Doczytać 1Document3 pagesStatystyka Opisowa Można Doczytać 1artem4907No ratings yet
- Wykład 6.11Document1 pageWykład 6.11cthulhu1998188No ratings yet
- Statystyka WDocument20 pagesStatystyka WEmilia Kolanowska100% (1)
- Mateusz Zięba - Biostatyka Temat 2Document18 pagesMateusz Zięba - Biostatyka Temat 2Mateusz ZiębaNo ratings yet
- III Miary RozproszeniaDocument8 pagesIII Miary RozproszeniaKAROLINANo ratings yet
- 1.podstawowe Pojęcia StatystyczneDocument56 pages1.podstawowe Pojęcia StatystycznenicolemayvevoNo ratings yet
- SPSS StatisticsDocument2 pagesSPSS StatisticsBlanka RomanowskaNo ratings yet
- Zielinski Wyklady Stat PDFDocument132 pagesZielinski Wyklady Stat PDFdNo ratings yet
- Kurs IBM SPSS Statistics - Krzysztof JurekDocument84 pagesKurs IBM SPSS Statistics - Krzysztof JurekmaciekbokuNo ratings yet
- Nieparametryczne Odpowiedniki Testów StatystycznychDocument4 pagesNieparametryczne Odpowiedniki Testów StatystycznychMaciek GrzegorczykNo ratings yet
- Cresswell ProceduryDocument6 pagesCresswell ProceduryMadleneNo ratings yet
- Wykład 1 - Podstawowe Wiadomości: Co To Jest Psychologia?Document11 pagesWykład 1 - Podstawowe Wiadomości: Co To Jest Psychologia?Wiktor ChmieleskiNo ratings yet
- Przykład Rozwiązania Ramy MESDocument5 pagesPrzykład Rozwiązania Ramy MESŁukasz GołębiowskiNo ratings yet
- Ćwicz 10Document35 pagesĆwicz 10Jakub WitkowskiNo ratings yet
- CNT SVX14C PL - 0910Document16 pagesCNT SVX14C PL - 0910Tomasz PliszkaNo ratings yet
- Termography Book PL FINALNY2 PDFDocument66 pagesTermography Book PL FINALNY2 PDFpolNo ratings yet







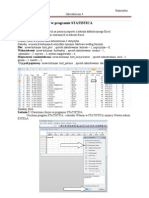





































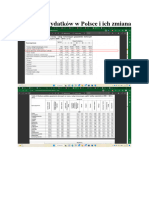
















Download as pdf or txt
You might also like
- Statystyka Opisowa W Zadaniach PDFDocument159 pagesStatystyka Opisowa W Zadaniach PDFKasia KulkaNo ratings yet
- Statystyka - NotatkiDocument6 pagesStatystyka - NotatkiIza GrzebakNo ratings yet
- Statystyka Wykłady OpisDocument13 pagesStatystyka Wykłady OpisAnna KośmiderNo ratings yet
- Wyk. - Wprowadzenie Do Analizy Danych SpołecznychDocument5 pagesWyk. - Wprowadzenie Do Analizy Danych SpołecznychMarta KramerNo ratings yet
- Jermakowicz 24032024144219 Statystyka 2Document41 pagesJermakowicz 24032024144219 Statystyka 2ewa kedzioraNo ratings yet
- Pojęcia Statystyczne1Document9 pagesPojęcia Statystyczne1Anna KośmiderNo ratings yet
- METODA REPREZENTACYJNA DrukDocument5 pagesMETODA REPREZENTACYJNA DrukOla GorskaNo ratings yet
- Laboratorium 4 Statystyka StatisticaDocument16 pagesLaboratorium 4 Statystyka StatisticaPipek PipekejNo ratings yet
- Statystyka WykładyDocument17 pagesStatystyka WykładyAnna KośmiderNo ratings yet
- Zasoby Wykład 1Document15 pagesZasoby Wykład 1OlaNo ratings yet
- Statystyka Opisowa 1Document47 pagesStatystyka Opisowa 1Marcelina ŁobodaNo ratings yet
- Wykład 1Document114 pagesWykład 1FilipNo ratings yet
- STAT - Wprowadzanie Danych - 2Document24 pagesSTAT - Wprowadzanie Danych - 2Natalia WróbelNo ratings yet
- Teoria-Statystyka MatematycznaDocument19 pagesTeoria-Statystyka Matematycznakrzysiu101No ratings yet
- Jermakowicz 05042024110036 Statystyka 4Document41 pagesJermakowicz 05042024110036 Statystyka 4ewa kedzioraNo ratings yet
- Analiza DyskryminacyjnaDocument13 pagesAnaliza DyskryminacyjnaBobiOneeNo ratings yet
- Problem BadawczyDocument9 pagesProblem BadawczyJulia DrosińskaNo ratings yet
- Statystyka 2Document6 pagesStatystyka 2maciej-onuchowskiNo ratings yet
- Skrypt Podręcznik MetodyDocument59 pagesSkrypt Podręcznik Metodyklaudiunia2215No ratings yet
- Final Boss StatystykaDocument18 pagesFinal Boss Statystykakncfzz4rcjNo ratings yet
- Statystyka WykładDocument21 pagesStatystyka Wykładweronika.latala59No ratings yet
- 2023 01 Statystyki Opisowe I Normalnosc RozkladuDocument3 pages2023 01 Statystyki Opisowe I Normalnosc RozkladuJustyna WcisłoNo ratings yet
- Estymacja - Materiały Do ĆwiczeńDocument6 pagesEstymacja - Materiały Do ĆwiczeńFilipNo ratings yet
- SPSS - Opis Zadań GWSH Psychologia ĆW 3 Zad.2 OpisDocument21 pagesSPSS - Opis Zadań GWSH Psychologia ĆW 3 Zad.2 OpismaciekbokuNo ratings yet
- Statystyczne Opracowanie Danych PomiarowychDocument16 pagesStatystyczne Opracowanie Danych Pomiarowychnotatki.chemiakNo ratings yet
- MetodologiaDocument3 pagesMetodologiaWiktoria GawlikNo ratings yet
- Wyklad 10 Elementy Statysytki OpisowejDocument18 pagesWyklad 10 Elementy Statysytki OpisowejAneta WróblewskaNo ratings yet
- CentylDocument18 pagesCentyljustynaturowska57No ratings yet
- Notatki NaDocument10 pagesNotatki NaMadleneNo ratings yet
- Statystyka PodstawyDocument27 pagesStatystyka PodstawyDawid PękałaNo ratings yet
- EstymacjaDocument32 pagesEstymacjaNadia DanylickaNo ratings yet
- Porównanie Dwóch GrupDocument5 pagesPorównanie Dwóch Grupartem4907No ratings yet
- StatystykaDocument38 pagesStatystykaWiktoriaNo ratings yet
- Psychometria NotatkiDocument41 pagesPsychometria NotatkiNate XxxNo ratings yet
- Metody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Document26 pagesMetody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Ewa ZalewskaNo ratings yet
- Rozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieDocument9 pagesRozdział 12 Przykład Zastosowania Metod Wap Do Analizy Procesów Gospodarowania Zasobami Ludzkimi W PrzedsiębiorstwieOlaNo ratings yet
- SPSSDocument37 pagesSPSSlizaNo ratings yet
- Statytyka MateriałyDocument29 pagesStatytyka Materiałyjuliakunaszyk44No ratings yet
- Statystyka PracaDocument26 pagesStatystyka PracaDagmara OwocNo ratings yet
- Lab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychDocument10 pagesLab. 5 - Badania Porównawcze Właściwości Metrologicznych Przyrządów PomiarowychYehor MalakhovNo ratings yet
- StatystykaDocument17 pagesStatystykaskubis.juliannaNo ratings yet
- Combining ClassifiersDocument22 pagesCombining ClassifiersMichal SiemaszkiewiczNo ratings yet
- StatystykaDocument4 pagesStatystykalescopainsdeoufNo ratings yet
- Analiza Statystyczna Dla Psychologów (Wykład)Document5 pagesAnaliza Statystyczna Dla Psychologów (Wykład)xxxmxx xNo ratings yet
- Statystyka Matematyczna 2023 2024Document56 pagesStatystyka Matematyczna 2023 2024dziarczykowskaNo ratings yet
- Jakosc ZyciaDocument20 pagesJakosc ZyciaKNo ratings yet
- Statystyka Opisowa Można Doczytać 1Document3 pagesStatystyka Opisowa Można Doczytać 1artem4907No ratings yet
- Wykład 6.11Document1 pageWykład 6.11cthulhu1998188No ratings yet
- Statystyka WDocument20 pagesStatystyka WEmilia Kolanowska100% (1)
- Mateusz Zięba - Biostatyka Temat 2Document18 pagesMateusz Zięba - Biostatyka Temat 2Mateusz ZiębaNo ratings yet
- III Miary RozproszeniaDocument8 pagesIII Miary RozproszeniaKAROLINANo ratings yet
- 1.podstawowe Pojęcia StatystyczneDocument56 pages1.podstawowe Pojęcia StatystycznenicolemayvevoNo ratings yet
- SPSS StatisticsDocument2 pagesSPSS StatisticsBlanka RomanowskaNo ratings yet
- Zielinski Wyklady Stat PDFDocument132 pagesZielinski Wyklady Stat PDFdNo ratings yet
- Kurs IBM SPSS Statistics - Krzysztof JurekDocument84 pagesKurs IBM SPSS Statistics - Krzysztof JurekmaciekbokuNo ratings yet
- Nieparametryczne Odpowiedniki Testów StatystycznychDocument4 pagesNieparametryczne Odpowiedniki Testów StatystycznychMaciek GrzegorczykNo ratings yet
- Cresswell ProceduryDocument6 pagesCresswell ProceduryMadleneNo ratings yet
- Wykład 1 - Podstawowe Wiadomości: Co To Jest Psychologia?Document11 pagesWykład 1 - Podstawowe Wiadomości: Co To Jest Psychologia?Wiktor ChmieleskiNo ratings yet
- Przykład Rozwiązania Ramy MESDocument5 pagesPrzykład Rozwiązania Ramy MESŁukasz GołębiowskiNo ratings yet
- Ćwicz 10Document35 pagesĆwicz 10Jakub WitkowskiNo ratings yet
- CNT SVX14C PL - 0910Document16 pagesCNT SVX14C PL - 0910Tomasz PliszkaNo ratings yet
- Termography Book PL FINALNY2 PDFDocument66 pagesTermography Book PL FINALNY2 PDFpolNo ratings yet