Download as pdf or txt
You might also like
- Livi - Politi-Nonequilibrium Statistical Physics PDFDocument438 pagesLivi - Politi-Nonequilibrium Statistical Physics PDFAvijit DasNo ratings yet
- SolutionsShumway PDFDocument82 pagesSolutionsShumway PDFjuve A.No ratings yet
- Q P P P P P P P P P P: Fall 2003 Society of Actuaries Course 3 Solutions Question #1 Key: EDocument40 pagesQ P P P P P P P P P P: Fall 2003 Society of Actuaries Course 3 Solutions Question #1 Key: EHông HoaNo ratings yet
- Engineering Dynamics: Solutions To Chapter 2Document63 pagesEngineering Dynamics: Solutions To Chapter 2Karim TouqanNo ratings yet
- AP Physics B Equation Reference SheetDocument7 pagesAP Physics B Equation Reference SheetKevin JiempreechaNo ratings yet
- Ilya Prigogine-From Being To Becoming - Time and Complexity in The Physical SciencesDocument293 pagesIlya Prigogine-From Being To Becoming - Time and Complexity in The Physical SciencesLuis Graillet100% (1)
- Lecture NotesDocument80 pagesLecture Notes8ienneNo ratings yet
- Jan 2015 - Mock Paper - Solution Q3-5Document5 pagesJan 2015 - Mock Paper - Solution Q3-5jimmychillsNo ratings yet
- Paso 1: X y X y X Nudo 01 Nudo2Document25 pagesPaso 1: X y X y X Nudo 01 Nudo2Czar PajaresNo ratings yet
- 111-2 Data Analysis Assignment: I-cos2θ圖Document2 pages111-2 Data Analysis Assignment: I-cos2θ圖陳泓睿No ratings yet
- TB SP All SolutionsDocument14 pagesTB SP All SolutionsexplorationeverywhereNo ratings yet
- Avance BDocument8 pagesAvance BarnoldNo ratings yet
- Computer Assignment No 04: Matlab/Pspice SimulationDocument35 pagesComputer Assignment No 04: Matlab/Pspice SimulationAhmad RaheelNo ratings yet
- 'Cart (X) ' 'Pendulum (Phi) ' 'Time (Sec) 'Document3 pages'Cart (X) ' 'Pendulum (Phi) ' 'Time (Sec) 'vayaloNo ratings yet
- Impulse Response of A LTI SystemDocument7 pagesImpulse Response of A LTI SystemEysha qureshiNo ratings yet
- Least Square FilterDocument5 pagesLeast Square Filterduc2711No ratings yet
- T (X, Y) + T (X, Y) 0: Deriva DerivaDocument1 pageT (X, Y) + T (X, Y) 0: Deriva DerivaValaur Ekbalam M BNo ratings yet
- Group 5 Report Lab2 1Document10 pagesGroup 5 Report Lab2 1Đức TrọngNo ratings yet
- Analisa Numerik MID UASDocument17 pagesAnalisa Numerik MID UASSafriNo ratings yet
- hw10 2021solsDocument28 pageshw10 2021solsluigui123No ratings yet
- 8 Simulation ModelingDocument6 pages8 Simulation Modelingtristan.ray.mateoNo ratings yet
- MarkovDocument61 pagesMarkovblahblah435No ratings yet
- Projektni Zadatak: Univerzitet U Zenici Mašinski Fakultet U ZeniciDocument11 pagesProjektni Zadatak: Univerzitet U Zenici Mašinski Fakultet U ZeniciElmedin SabicNo ratings yet
- Solution MatlabDocument46 pagesSolution MatlabFreddy Mendoza CoronelNo ratings yet
- Tarea5 Garcia VelazquezDocument3 pagesTarea5 Garcia VelazquezChrisNo ratings yet
- Act.4 U2Document15 pagesAct.4 U2Héctor Rodríguez MartínezNo ratings yet
- Lab Title: Objectives: Material Required:: Sinusoidal Steady StateDocument11 pagesLab Title: Objectives: Material Required:: Sinusoidal Steady Stateahmed shahNo ratings yet
- Problem Set 1 - CH148Document11 pagesProblem Set 1 - CH148Allyssa BadilloNo ratings yet
- Examen LC2 2021 Solutions Avec BarèmeDocument6 pagesExamen LC2 2021 Solutions Avec Barèmedavid AbotsitseNo ratings yet
- 5 ChapterDocument5 pages5 ChapterTenMinutesNo ratings yet
- HW3 Ee433Document9 pagesHW3 Ee433Ahmed Al-SarawiNo ratings yet
- Newtons 160510102559 PDFDocument10 pagesNewtons 160510102559 PDFYumi koshaNo ratings yet
- Act Assignment PDFDocument14 pagesAct Assignment PDFchan hkNo ratings yet
- Facultad de Ingeniería Escuela Académico Profesional de Ingeniería CivilDocument10 pagesFacultad de Ingeniería Escuela Académico Profesional de Ingeniería CivilAntony Huaracha AbantoNo ratings yet
- Quality Management Control Chart 2 - Attribute Control ChartDocument6 pagesQuality Management Control Chart 2 - Attribute Control ChartLê Nhật TiếnNo ratings yet
- Calculos Informe4 MECANICA DE FLUIDOSDocument8 pagesCalculos Informe4 MECANICA DE FLUIDOSCinthya IríasNo ratings yet
- Analisis Estructural IiDocument12 pagesAnalisis Estructural IiKEVIN JORDAN GUERRERO SANTISTEBANNo ratings yet
- Experiment 3Document13 pagesExperiment 3wallace kito0% (1)
- Problem 2.16 PDFDocument2 pagesProblem 2.16 PDFKauê BrittoNo ratings yet
- Tutorial - 1 SolutionsDocument6 pagesTutorial - 1 Solutionssedobi1512No ratings yet
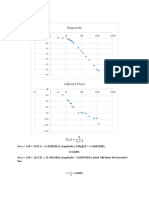
- Magnitude: Mystery 1Document5 pagesMagnitude: Mystery 1aero3153No ratings yet
- Answers Lesson 6Document2 pagesAnswers Lesson 6Octav PaloaieNo ratings yet
- Chart Title Chart Title: ΔP (Pa) µ ᴓ (cm) L (cm) W (cm /s)Document4 pagesChart Title Chart Title: ΔP (Pa) µ ᴓ (cm) L (cm) W (cm /s)Jaider Santiago PastranaNo ratings yet
- Ce-408 At-2.1 BuenconsejoDocument53 pagesCe-408 At-2.1 BuenconsejoqrgdelossantosNo ratings yet
- Result Chm520 Exp 5Document11 pagesResult Chm520 Exp 5Eva Lizwina MatinNo ratings yet
- EC-1 Assignment 1 (22-S1) - Solution Walkthro (27 Aug 2022)Document5 pagesEC-1 Assignment 1 (22-S1) - Solution Walkthro (27 Aug 2022)Vipul PatilNo ratings yet
- Lab2 Group1Document7 pagesLab2 Group1khatran040205No ratings yet
- Tugas Mekrek DEFRI S APUTRA 2017210064Document12 pagesTugas Mekrek DEFRI S APUTRA 2017210064Andrian PutraNo ratings yet
- Edu 2012 Spring MLC SolutionsDocument152 pagesEdu 2012 Spring MLC Solutionstmaster11235No ratings yet
- Experiment No.-1A Aim-To Implement Algorithm Using Array As A Data Structure and Analyse Its Time Complexity Selection Sort AlgorithmDocument36 pagesExperiment No.-1A Aim-To Implement Algorithm Using Array As A Data Structure and Analyse Its Time Complexity Selection Sort AlgorithmVikas KumarNo ratings yet
- Laplace AnaliticaDocument2 pagesLaplace AnaliticaValaur Ekbalam M BNo ratings yet
- 4-RC DC Circuit Sohaila REportDocument5 pages4-RC DC Circuit Sohaila REportsohaila gaberNo ratings yet
- Taller 1 Zapata AisladaDocument4 pagesTaller 1 Zapata AisladaLuis CarpioNo ratings yet
- Solución Examen Parcial FZ1 A 2019 - IDocument2 pagesSolución Examen Parcial FZ1 A 2019 - IDaniela CastilloNo ratings yet
- Quantity Surveying & Cost Estimation CE-372 XEN Shahid HussainDocument4 pagesQuantity Surveying & Cost Estimation CE-372 XEN Shahid HussainAli TariqNo ratings yet
- Introduc) On To MATLAB For Control Engineers: EE 447 Autumn 2008 Eric KlavinsDocument30 pagesIntroduc) On To MATLAB For Control Engineers: EE 447 Autumn 2008 Eric KlavinsChristina HillNo ratings yet
- Columna 1 Columna 2: 0.30m 0.70m 0.90m 0.30mDocument7 pagesColumna 1 Columna 2: 0.30m 0.70m 0.90m 0.30mGIOVANNI JESUS CUTIPA LEGUANo ratings yet
- ChoppiDocument12 pagesChoppiSarah Sanchez100% (1)
- Nonnewtonian Problem 3-C - Jupyter NotebookDocument8 pagesNonnewtonian Problem 3-C - Jupyter NotebookPatel AnjaliNo ratings yet
- Ihsan GhaniDocument14 pagesIhsan Ghaniihsanghani7676No ratings yet
- UBC-97 Seismic LoadDocument1 pageUBC-97 Seismic LoaddantevariasNo ratings yet
- Solution To Probability Lecture-IDocument17 pagesSolution To Probability Lecture-Ishidupk5 pkNo ratings yet
- Kinetika Reaksi RedoksDocument5 pagesKinetika Reaksi RedoksalyaaNo ratings yet
- A Mother's Guide to Addition & SubtractionFrom EverandA Mother's Guide to Addition & SubtractionRating: 5 out of 5 stars5/5 (1)
- Stat513 l10Document27 pagesStat513 l10hea4152No ratings yet
- MBS3212 EngMaths For BS Chapter 2 VectorDocument72 pagesMBS3212 EngMaths For BS Chapter 2 Vectorhea4152No ratings yet
- MBS3212 EngMaths For BS Chapter 1 ComplexNumberDocument60 pagesMBS3212 EngMaths For BS Chapter 1 ComplexNumberhea4152No ratings yet
- MBS3212 EngMaths For BS Chapter 3 Differential CalculusDocument78 pagesMBS3212 EngMaths For BS Chapter 3 Differential Calculushea4152No ratings yet
- MBS3212 EngMaths For BS Chapter 4 Integral CalculusDocument60 pagesMBS3212 EngMaths For BS Chapter 4 Integral Calculushea4152No ratings yet
- 1976 - (Isham) An Introduction To Quantum GravityDocument71 pages1976 - (Isham) An Introduction To Quantum Gravityfaudzi5505No ratings yet
- PassYear - JJ207 Thermodynamic - SesiJun2012Document7 pagesPassYear - JJ207 Thermodynamic - SesiJun2012Ah TiangNo ratings yet
- 10 Non-Exact EquationsDocument20 pages10 Non-Exact EquationsKaye EvangelistaNo ratings yet
- MEK451-Chapter - 2 - First - Law - of - Thermodynamics - M2Document68 pagesMEK451-Chapter - 2 - First - Law - of - Thermodynamics - M2MUHAMMAD DANISH HAZIQ AMIRULL FAKARUDDINNo ratings yet
- Department of Education: Learning Activity SheetDocument2 pagesDepartment of Education: Learning Activity SheetKaren May UrlandaNo ratings yet
- CorrectionDocument3 pagesCorrectionAmanifadia GarroudjiNo ratings yet
- MEHB323 Tutorial Assignment 2Document3 pagesMEHB323 Tutorial Assignment 2Amzar Aizad100% (1)
- L2 (Energy Analysis)Document31 pagesL2 (Energy Analysis)Kavin KabilanNo ratings yet
- Lecture Thermodynamic Basics of Physical ChemistryDocument26 pagesLecture Thermodynamic Basics of Physical ChemistryAshish RajNo ratings yet
- Field Theory Roman PDFDocument2 pagesField Theory Roman PDFEducatedNo ratings yet
- Functional Determinants: Consider A Theory of A Complex Scalar FieldDocument8 pagesFunctional Determinants: Consider A Theory of A Complex Scalar Fielddmp130No ratings yet
- Heat Transfer T1 Formula SheetDocument5 pagesHeat Transfer T1 Formula SheetJosh PageNo ratings yet
- List of Textbooks in ElectromagnetismDocument2 pagesList of Textbooks in ElectromagnetismsddsNo ratings yet
- Absolute Zero PDFDocument2 pagesAbsolute Zero PDFFeroz AkhtarNo ratings yet
- 15 Atom HidrogenDocument42 pages15 Atom HidrogenRahajengNo ratings yet
- Assumptions 1 Argon Is An Ideal Gas Since It Is at A High Temperature and Low Pressure Relative To Its CriticalDocument2 pagesAssumptions 1 Argon Is An Ideal Gas Since It Is at A High Temperature and Low Pressure Relative To Its CriticalMonta de TorosNo ratings yet
- Ashraf 2023 Phys. Scr. 98 035027Document20 pagesAshraf 2023 Phys. Scr. 98 035027Piyali BharNo ratings yet
- Gen Bio Part 2 ReportingDocument10 pagesGen Bio Part 2 ReportingMj DeguzmanNo ratings yet
- CET I 3.PVT Relationship 2021 Part 2Document47 pagesCET I 3.PVT Relationship 2021 Part 2Dhruv AgarwalNo ratings yet
- Ecs416 - Topic Summary - 20202Document28 pagesEcs416 - Topic Summary - 20202IRDINA ZAKIRAH IZUDINNo ratings yet
- Thermodynamic Cycle, Gas Turbine, Turbo-Super ChargerDocument30 pagesThermodynamic Cycle, Gas Turbine, Turbo-Super ChargerTamim Islam JoyNo ratings yet
- UNIT 5 Solid GeometryDocument4 pagesUNIT 5 Solid GeometrysirfentertertainmenthaiNo ratings yet
- LecturesDocument701 pagesLecturesAlanJohnHNo ratings yet
- Johor Matriculation College Chemistry Unit Practical ReportDocument8 pagesJohor Matriculation College Chemistry Unit Practical ReportVeshal RameshNo ratings yet
- Rep. Prog. Phys., Vol. 41, 1978. Printed in Great BritainDocument43 pagesRep. Prog. Phys., Vol. 41, 1978. Printed in Great BritainDeepak PatelNo ratings yet
- Camarines Norte State CollegeDocument3 pagesCamarines Norte State CollegeEvan BoaloyNo ratings yet