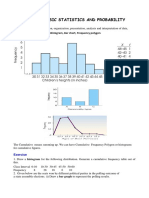
Download as pdf or txt
You might also like
- KS3 Maths Progress Delta 1 Unit 2 PDFDocument14 pagesKS3 Maths Progress Delta 1 Unit 2 PDFMuhammad AmmarNo ratings yet
- Mock ThetaDocument10 pagesMock ThetaRina VarmaNo ratings yet
- Lesson Plan Grouped-Percentile RankDocument5 pagesLesson Plan Grouped-Percentile RankSherra Mae BagoodNo ratings yet
- Utilization of Assessment DataDocument50 pagesUtilization of Assessment DataIvy Claris Ba-awa Iquin100% (3)
- Measures of Central Tendency and Other Positional MeasuresDocument13 pagesMeasures of Central Tendency and Other Positional Measuresbv123bvNo ratings yet
- ch10 Project Monitoring & ControlDocument29 pagesch10 Project Monitoring & ControlLucky Luke100% (1)
- AL1 Week 9Document4 pagesAL1 Week 9Reynante Louis DedaceNo ratings yet
- Chapter 5Document143 pagesChapter 5Adrian EcojedoNo ratings yet
- Educ 4 Part 3 Utilization of Assessment Data: CB - CBDocument6 pagesEduc 4 Part 3 Utilization of Assessment Data: CB - CBKhemme Lapor Chu UbialNo ratings yet
- Chapter 11 Measures of Central TendencyDocument26 pagesChapter 11 Measures of Central TendencyJAMES DERESANo ratings yet
- Steps in Constructing Frequency Distribution: R Desired Number of Classes R KDocument6 pagesSteps in Constructing Frequency Distribution: R Desired Number of Classes R KJoshua Kevin SolamoNo ratings yet
- Stat & ProbabilityDocument67 pagesStat & Probabilityanna luna berryNo ratings yet
- Chapter 5Document29 pagesChapter 5Sherbeth DorojaNo ratings yet
- Graphical Representation of DataDocument46 pagesGraphical Representation of DataRenz Daniel R. ElmidoNo ratings yet
- Unit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonDocument6 pagesUnit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonVenkatesh WaranNo ratings yet
- Lal Muhammad Elementary Statistics Week 3 Lecture 5Document27 pagesLal Muhammad Elementary Statistics Week 3 Lecture 5Muhammad BilalNo ratings yet
- Technical Terms Used in Formulation Frequency DistributionDocument22 pagesTechnical Terms Used in Formulation Frequency DistributionSenelwa Anaya100% (1)
- MODULE 3statistics1Document13 pagesMODULE 3statistics1mart arvyNo ratings yet
- Module5 Measures of Central Tendency Grouped Data Business 1Document13 pagesModule5 Measures of Central Tendency Grouped Data Business 1Donna Mia CanlomNo ratings yet
- Module5 Measures of Central Tendency Grouped Data Business 1Document13 pagesModule5 Measures of Central Tendency Grouped Data Business 1Donna Mia CanlomNo ratings yet
- Frequency DistributionDocument35 pagesFrequency DistributionRay Amiscaray MarrymathNo ratings yet
- Statistics, mg4Document58 pagesStatistics, mg4Himanshu ChawlaNo ratings yet
- 3-Statistical Description of Data (Compatibility Mode)Document20 pages3-Statistical Description of Data (Compatibility Mode)cresjohnNo ratings yet
- Frequency Distribution TableDocument17 pagesFrequency Distribution TableMae CanceranNo ratings yet
- Methods of Data PresntationDocument53 pagesMethods of Data PresntationWondmageneUrgessaNo ratings yet
- Documents - Pub Statistics Math Project Class 10thDocument29 pagesDocuments - Pub Statistics Math Project Class 10thNabaNo ratings yet
- Adv Stat Data PresentationDocument57 pagesAdv Stat Data Presentationjhoana patunganNo ratings yet
- Stat Lecture 2Document5 pagesStat Lecture 2bayabaohalim8No ratings yet
- Chapter 2: Frequency Distribution and Measures of Central Tendency 2.1 A FREQUENCY DISTRIBUTION Is A Tabular Arrangement of Data Whereby The Data Is GroupedDocument9 pagesChapter 2: Frequency Distribution and Measures of Central Tendency 2.1 A FREQUENCY DISTRIBUTION Is A Tabular Arrangement of Data Whereby The Data Is GroupedDaille Wroble GrayNo ratings yet
- 2 Measures of Central TendencyDocument21 pages2 Measures of Central TendencyBroccoli ChanNo ratings yet
- MEDIAN and The QuartilesDocument6 pagesMEDIAN and The QuartilesWaqasMahmoodNo ratings yet
- ReportDocument13 pagesReportAlyanna Clarisse Padilla CamposNo ratings yet
- Chapter 2: Frequency Distribution: Week 5 - 6Document12 pagesChapter 2: Frequency Distribution: Week 5 - 6Niema Tejano FloroNo ratings yet
- Frequency Distribution: Education DepartmentDocument9 pagesFrequency Distribution: Education DepartmentLeo Cordel Jr.No ratings yet
- GROUPED DATA - Measures of Central Tendency - Mean Median ModeDocument21 pagesGROUPED DATA - Measures of Central Tendency - Mean Median ModeJohann AlegreNo ratings yet
- Descriptive Statistics: Definition 10.2.1Document16 pagesDescriptive Statistics: Definition 10.2.1anipa mwaleNo ratings yet
- MEDIAN and The QuartilesDocument6 pagesMEDIAN and The QuartilesameetNo ratings yet
- Measure of Central Tendency (Ungrouped and Grouped Data)Document40 pagesMeasure of Central Tendency (Ungrouped and Grouped Data)Ahlan Marciano Emmanuel De Silva100% (1)
- Frequency Distribution PDFDocument36 pagesFrequency Distribution PDFMj DacapioNo ratings yet
- C3 Measures of Central TendencyDocument48 pagesC3 Measures of Central TendencyTeresa Mae Abuzo Vallejos-BucagNo ratings yet
- Learning Sheet No. 7Document6 pagesLearning Sheet No. 7Alex Cañizo Gabilan Jr.No ratings yet
- Frequency DistributionDocument16 pagesFrequency DistributionBpNo ratings yet
- Lecture#2Document28 pagesLecture#2Shereen KafayatNo ratings yet
- Elementary StatisticsDocument73 pagesElementary StatisticsDeepak GoyalNo ratings yet
- Lesson Plan grouped-PERCENTILEDocument6 pagesLesson Plan grouped-PERCENTILESherra Mae BagoodNo ratings yet
- Angelica 160130011729Document343 pagesAngelica 160130011729HaroldM.MagallanesNo ratings yet
- Chapter 3 StatDocument26 pagesChapter 3 StatAndres BrutasNo ratings yet
- Slides - B. Stat - I, Lecture 6 - Chap 3, Session 2, Median, ModeDocument22 pagesSlides - B. Stat - I, Lecture 6 - Chap 3, Session 2, Median, ModeKim NamjoonneNo ratings yet
- Local Media3736459280450109840Document64 pagesLocal Media3736459280450109840Ej DulatreNo ratings yet
- LEC03Document16 pagesLEC03Uzair TariqNo ratings yet
- Properties of Median in StatisticsDocument6 pagesProperties of Median in StatisticsElijah IbsaNo ratings yet
- Module 4Document27 pagesModule 4Justine Joy SabalboroNo ratings yet
- Lesson 5Document20 pagesLesson 5RM April AlonNo ratings yet
- Frequency DistributionDocument4 pagesFrequency DistributionMD. JOBAYEDNo ratings yet
- Preparing A Frequency DistributionDocument5 pagesPreparing A Frequency DistributionAngelica FloraNo ratings yet
- Frequency Distribution TableDocument14 pagesFrequency Distribution TableLizlette Ianne100% (2)
- Quartile For Grouped DataDocument7 pagesQuartile For Grouped DataCei-Cei100% (2)
- Educ 98 - MEASURES OF CENTRAL TENDENCYDocument24 pagesEduc 98 - MEASURES OF CENTRAL TENDENCYMARYKNOL J. ALVAREZNo ratings yet
- Engineering Prob & Stat Lecture Notes 3Document9 pagesEngineering Prob & Stat Lecture Notes 3EICQ/00154/2020 SAMUEL MWANGI RUKWARONo ratings yet
- Data Presentation and OrganizationDocument40 pagesData Presentation and OrganizationGina Mangco-SantosNo ratings yet
- SS 1D - ReportingDocument13 pagesSS 1D - ReportingGerald GuiwaNo ratings yet
- Mean, Median and Mode of Grouped DataDocument6 pagesMean, Median and Mode of Grouped DataGerald GuiwaNo ratings yet
- Envisci ReviewerDocument8 pagesEnvisci ReviewerGerald GuiwaNo ratings yet
- El 108 Week 4Document35 pagesEl 108 Week 4Gerald GuiwaNo ratings yet
- Eed Eng Week 1Document10 pagesEed Eng Week 1Gerald GuiwaNo ratings yet
- QUIZDocument1 pageQUIZGerald GuiwaNo ratings yet
- Asian RegionalismDocument20 pagesAsian RegionalismGerald GuiwaNo ratings yet
- Min/Max Problems and InequalitiesDocument3 pagesMin/Max Problems and InequalitiesOtávio José Dezem Bertozzi Jr.No ratings yet
- Full NotesDocument114 pagesFull NotesManu Ssvm25% (4)
- Design Example 2-Way SlabDocument41 pagesDesign Example 2-Way SlabjimmydomingojrNo ratings yet
- Dynamic-Programming Algorithms For Shortest Path Prob - LemsDocument4 pagesDynamic-Programming Algorithms For Shortest Path Prob - LemsYannis FertakisNo ratings yet
- Maths Olympiad SolutionDocument13 pagesMaths Olympiad Solutioncommandodhruv123No ratings yet
- y75XyadLS3uMzHi6bEyk - Scheme of Work For Nursery and Primary School in Nigeria PDFPDFDocument21 pagesy75XyadLS3uMzHi6bEyk - Scheme of Work For Nursery and Primary School in Nigeria PDFPDFaaishaharikeNo ratings yet
- Matrix Algebra: Introduction On Matrices and VectorsDocument7 pagesMatrix Algebra: Introduction On Matrices and VectorsHussam AliraqiNo ratings yet
- Department of Mechanical Engineering: Experiment No. 12Document7 pagesDepartment of Mechanical Engineering: Experiment No. 12zakibrant23No ratings yet
- Design and Analysis of Experiments - Das, GiriDocument312 pagesDesign and Analysis of Experiments - Das, Giriranaadhya100No ratings yet
- 2015-02-10 MBM Tutorial Combined DiversityDocument60 pages2015-02-10 MBM Tutorial Combined DiversityaaaaaNo ratings yet
- InterpretationDocument171 pagesInterpretationDeepak KumarNo ratings yet
- Spectre-Monte Carlo - Tutorial For Cadence 4.4.3 Using SpectresDocument7 pagesSpectre-Monte Carlo - Tutorial For Cadence 4.4.3 Using SpectresAlex WongNo ratings yet
- Praxis 2 Math Practice TestDocument23 pagesPraxis 2 Math Practice Testrin ros100% (2)
- Ge-Mmw Midterm NotesDocument6 pagesGe-Mmw Midterm NotesJamaica Jane100% (1)
- Boolean Algebra: Presented By: ROSE ANN M. ELLORENDocument15 pagesBoolean Algebra: Presented By: ROSE ANN M. ELLORENAnnie Rose MahinayNo ratings yet
- 2 - ProcessesDocument36 pages2 - ProcessesAljohn Mark ReyesNo ratings yet
- Math 8 Second Quarter Test18Document3 pagesMath 8 Second Quarter Test18leojackanthony cabido100% (2)
- Multivariable: CalculusDocument453 pagesMultivariable: CalculusNitro Gamer23No ratings yet
- Bhattacharyya - Magnetic Anomalies Due To Prism Shaped Bodies With Arbitrary PolarizationDocument15 pagesBhattacharyya - Magnetic Anomalies Due To Prism Shaped Bodies With Arbitrary Polarizationnorbi34No ratings yet
- Illustrative Problems ADocument2 pagesIllustrative Problems Aquynhtran_2208No ratings yet
- Lesson Plan RudimentsDocument4 pagesLesson Plan RudimentsDaniel Vicencio100% (1)
- A. Probability Sampling MethodsDocument6 pagesA. Probability Sampling MethodsYmon TuallaNo ratings yet
- Quiz 1Document5 pagesQuiz 1shwetajunejaNo ratings yet
- Course Plan DLD-2020Document16 pagesCourse Plan DLD-2020Muhammad AsadNo ratings yet
- Bartleby Portal111Document4 pagesBartleby Portal111Gopal SinhaNo ratings yet
- Sigma Level Calculator v7Document115 pagesSigma Level Calculator v7Ramji RamakrishnanNo ratings yet
- Excitation Loss Module: SpecificationDocument2 pagesExcitation Loss Module: SpecificationKenNaNo ratings yet