Download as pdf or txt
You might also like
- AWS Sso UgDocument146 pagesAWS Sso UgTanayaNo ratings yet
- 0.1 Guilherme Marthe - Boston House Pricing ChallengeDocument15 pages0.1 Guilherme Marthe - Boston House Pricing ChallengeGuilherme Marthe100% (1)
- A. M. Lister (Auth.) - Fundamentals of Operating Systems-Springer-Verlag New York (1984) PDFDocument172 pagesA. M. Lister (Auth.) - Fundamentals of Operating Systems-Springer-Verlag New York (1984) PDFSelva100% (2)
- Machine Learning Lab Manual 7Document8 pagesMachine Learning Lab Manual 7Raheel Aslam100% (1)
- Machine Learning With The Arduino Air Quality PredDocument10 pagesMachine Learning With The Arduino Air Quality PredGirmit GirmitNo ratings yet
- 4.2.2.6 Lab - Evaluating Fit Errors in Linear RegressionDocument4 pages4.2.2.6 Lab - Evaluating Fit Errors in Linear RegressionNurul Fadillah JannahNo ratings yet
- AI ManualDocument36 pagesAI ManualDev SejvaniNo ratings yet
- 11 Different Ways For Outlier Detection in PythonDocument11 pages11 Different Ways For Outlier Detection in PythonNeethu Merlin AlanNo ratings yet
- 4.3.1.4 Lab - Internet Traffic Data Linear RegressionDocument14 pages4.3.1.4 Lab - Internet Traffic Data Linear RegressionNurul Fadillah JannahNo ratings yet
- 17IT8029Document7 pages17IT8029AlexNo ratings yet
- Review-3 Topic-: ITE2013 - BIG DATA AnalyticsDocument19 pagesReview-3 Topic-: ITE2013 - BIG DATA AnalyticsAman KushwahaNo ratings yet
- Big Data AnalysisDocument38 pagesBig Data Analysisrathodrohit2121No ratings yet
- ML Lab 11 Manual - Neural Networks (Ver4)Document8 pagesML Lab 11 Manual - Neural Networks (Ver4)dodela6303No ratings yet
- Assignment1 FNDocument8 pagesAssignment1 FNVân Anh NguyễnNo ratings yet
- Spam Email Detection Using Neural Networks TrainingDocument7 pagesSpam Email Detection Using Neural Networks TrainingDiana BeltranNo ratings yet
- ProjectReport KanwarpalDocument17 pagesProjectReport KanwarpalKanwarpal SinghNo ratings yet
- Implementation of Time Series ForecastingDocument12 pagesImplementation of Time Series ForecastingSoba CNo ratings yet
- Neural NetworksDocument37 pagesNeural NetworksNAIMUL HASAN NAIMNo ratings yet
- Scikit LearnDocument17 pagesScikit LearnRRNo ratings yet
- Chap 6 EmbeddingDocument44 pagesChap 6 EmbeddingHRITWIK GHOSHNo ratings yet
- What Is AlgorithmDocument64 pagesWhat Is AlgorithmKuljeet KaurNo ratings yet
- Maxbox Starter60 Machine LearningDocument8 pagesMaxbox Starter60 Machine LearningMax KleinerNo ratings yet
- Deep LearningDocument25 pagesDeep Learningdevansh misraNo ratings yet
- Jupyter LabDocument42 pagesJupyter LabPaul ShaafNo ratings yet
- Character Recognition Using Neural Networks: Rókus Arnold, Póth MiklósDocument4 pagesCharacter Recognition Using Neural Networks: Rókus Arnold, Póth MiklósSharath JagannathanNo ratings yet
- 09 ParallelizationRecap PDFDocument62 pages09 ParallelizationRecap PDFgiordano manciniNo ratings yet
- LP1 1Document129 pagesLP1 1Sagar KhodeNo ratings yet
- JDSE18 M.OutaharDocument6 pagesJDSE18 M.OutaharDjaouida MansouriNo ratings yet
- 1 Hanoi University of Science and Technology: School of Electrical Engineering, 03 July 2022Document7 pages1 Hanoi University of Science and Technology: School of Electrical Engineering, 03 July 2022Nhật TânNo ratings yet
- Safety For Drivers Using OpenCV in PythonDocument8 pagesSafety For Drivers Using OpenCV in PythonIJRASETPublicationsNo ratings yet
- 20MEMECH Part 6 - NN Vol - 1Document34 pages20MEMECH Part 6 - NN Vol - 1sali5312572No ratings yet
- Lecture 2: Introduction To PytorchDocument7 pagesLecture 2: Introduction To PytorchNilesh ChaudharyNo ratings yet
- Fundamentals of Machine Learning Support Vector Machines, Practical SessionDocument4 pagesFundamentals of Machine Learning Support Vector Machines, Practical SessionvothiquynhyenNo ratings yet
- 2324 BigData Lab3Document6 pages2324 BigData Lab3Elie Al HowayekNo ratings yet
- BackpropagationDocument12 pagesBackpropagationali.nabeel246230No ratings yet
- Tutorial 1 - RegressionDocument6 pagesTutorial 1 - RegressionAnwar ZainuddinNo ratings yet
- Department of Computing: CS 212: Object Oriented ProgrammingDocument6 pagesDepartment of Computing: CS 212: Object Oriented ProgrammingMuneeb AsifNo ratings yet
- DIP Lab Manual No 02Document24 pagesDIP Lab Manual No 02myfirstNo ratings yet
- Detection of Local Intrusion To Avoid Damage of Global EffectsDocument4 pagesDetection of Local Intrusion To Avoid Damage of Global EffectstheijesNo ratings yet
- LP 1 Lab Manual - v1Document80 pagesLP 1 Lab Manual - v1Diptesh ThakareNo ratings yet
- The Prediction of Sale Time Series by Artificial Neural NetworkDocument4 pagesThe Prediction of Sale Time Series by Artificial Neural Networkbasualok@rediffmail.comNo ratings yet
- Daa Unit-IDocument14 pagesDaa Unit-Isanthoshi durgaNo ratings yet
- DNN ALL Practical 28Document34 pagesDNN ALL Practical 284073Himanshu PatleNo ratings yet
- Week 2 Project - Search Algorithms - CSMMDocument8 pagesWeek 2 Project - Search Algorithms - CSMMRaj kumar manepallyNo ratings yet
- Week - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Document7 pagesWeek - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Mrunal BhilareNo ratings yet
- Functions and PackagesDocument7 pagesFunctions and PackagesNur SyazlianaNo ratings yet
- Machine LearningDocument56 pagesMachine LearningMani Vrs100% (3)
- Exercise 4 "Linear System Identification Using Neural Networks" ObjectiveDocument7 pagesExercise 4 "Linear System Identification Using Neural Networks" Objectiveberkanhzrc67No ratings yet
- CS3361 - Data Science LaboratoryDocument31 pagesCS3361 - Data Science Laboratoryparanjothi karthikNo ratings yet
- Detecting Heart Abnormalities Using 1D CNN On Data You Cannot SeeDocument18 pagesDetecting Heart Abnormalities Using 1D CNN On Data You Cannot SeesdfasfdNo ratings yet
- First ReportDocument14 pagesFirst Reportdnthrtm3No ratings yet
- 10 PDFDocument12 pages10 PDFAishwarya DasNo ratings yet
- Regularization: Updates To AssignmentDocument21 pagesRegularization: Updates To AssignmentYun SuNo ratings yet
- KerasDocument3 pagesKerasmagas32862No ratings yet
- Development Matlab Toolbox For Grey BoxDocument8 pagesDevelopment Matlab Toolbox For Grey BoxZulisNo ratings yet
- Deep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908Document5 pagesDeep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908vikNo ratings yet
- Tutorial LTE SimDocument6 pagesTutorial LTE SimgowdamandaviNo ratings yet
- Intro 2 NetlabDocument10 pagesIntro 2 NetlabBhaumik BhuvaNo ratings yet
- System Parameters Identification Scilab-Xcos - 0Document4 pagesSystem Parameters Identification Scilab-Xcos - 0manuellleNo ratings yet
- System Parameters Identification Scilab-XcosDocument4 pagesSystem Parameters Identification Scilab-XcosmanuellleNo ratings yet
- Human Activities Classifier Using SVMDocument19 pagesHuman Activities Classifier Using SVMBsef19m012-IQRA SARWARNo ratings yet
- Python Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreFrom EverandPython Advanced Programming: The Guide to Learn Python Programming. Reference with Exercises and Samples About Dynamical Programming, Multithreading, Multiprocessing, Debugging, Testing and MoreNo ratings yet
- 43-Article Text-239-2-10-20201Document9 pages43-Article Text-239-2-10-20201Nurul Fadillah JannahNo ratings yet
- Multicore and Multithreaded Processors: Why Multicore? Thread-Level ParallelismDocument20 pagesMulticore and Multithreaded Processors: Why Multicore? Thread-Level ParallelismNurul Fadillah JannahNo ratings yet
- Kriteria Pembatasan Hak Cipta Lagu Dalam Praktik Covering Melalui Youtube Faghlaifi Naim, SHDocument14 pagesKriteria Pembatasan Hak Cipta Lagu Dalam Praktik Covering Melalui Youtube Faghlaifi Naim, SHNurul Fadillah JannahNo ratings yet
- Ethika Profesi 2 SKS: Wardiyono Drs. Suhaeri, MT Suhaeri@yarsi - Ac.idDocument46 pagesEthika Profesi 2 SKS: Wardiyono Drs. Suhaeri, MT Suhaeri@yarsi - Ac.idNurul Fadillah JannahNo ratings yet
- Tanggal Jumlah - Kematian Kasus - Positive Sehat Kasus AktifDocument2 pagesTanggal Jumlah - Kematian Kasus - Positive Sehat Kasus AktifNurul Fadillah JannahNo ratings yet
- PLSQL 1 3Document27 pagesPLSQL 1 3Nurul Fadillah JannahNo ratings yet
- PLSQL 4 3 PracticeDocument2 pagesPLSQL 4 3 PracticeNurul Fadillah JannahNo ratings yet
- Srinu Python ResumeDocument2 pagesSrinu Python ResumeSrinivasa ReddyNo ratings yet
- S1720, S2700, S5700, and S6720 Series Ethernet Switches Configuration Guide - SecurityDocument13 pagesS1720, S2700, S5700, and S6720 Series Ethernet Switches Configuration Guide - Securitynodih20749No ratings yet
- Prognostics of Power MOSFET Using Artificial Neural Network ApproachDocument13 pagesPrognostics of Power MOSFET Using Artificial Neural Network ApproachMohan Kumar DashNo ratings yet
- Downloaded From Manuals Search EngineDocument15 pagesDownloaded From Manuals Search EnginetheunauthorisedNo ratings yet
- IT - Informatics AlphabetDocument6 pagesIT - Informatics AlphabetDrago RadićNo ratings yet
- MicroBit Quick Start Teacher GuideDocument36 pagesMicroBit Quick Start Teacher GuideChris KladisNo ratings yet
- Smart GridsDocument2 pagesSmart GridsJaideep BollapragadaNo ratings yet
- Siddesh Bhagwan Pingale: EducationDocument2 pagesSiddesh Bhagwan Pingale: EducationSiddesh PingaleNo ratings yet
- Drop BoxDocument62 pagesDrop BoxJesús L. Santamaría AngelesNo ratings yet
- Performance Analysis of Sidelink 5G-V2X Mode 2 Through An Open-Source SimulatorDocument14 pagesPerformance Analysis of Sidelink 5G-V2X Mode 2 Through An Open-Source SimulatorStefan VesicNo ratings yet
- 001-Ict Service Request FormDocument2 pages001-Ict Service Request FormClaire Natingor LagrosaNo ratings yet
- WSJ'S Tech Guide To Working From Home Working From HomeDocument23 pagesWSJ'S Tech Guide To Working From Home Working From HomeAlirezaNo ratings yet
- Hacking: Don't Learn To Hack - Hack To LearnDocument19 pagesHacking: Don't Learn To Hack - Hack To LearnSrini VasNo ratings yet
- Teaching and Learning With Ict Tools: Issues and ChallengesDocument8 pagesTeaching and Learning With Ict Tools: Issues and ChallengesJames Moreno100% (1)
- Oracle Software Technical Support Policies: 1. OverviewDocument24 pagesOracle Software Technical Support Policies: 1. OverviewOscarNo ratings yet
- Ai 1Document2 pagesAi 1Abokhaled AL-ashmawiNo ratings yet
- Mitsubishi: General Purpose AC SERVODocument15 pagesMitsubishi: General Purpose AC SERVOBrendisNo ratings yet
- Chapter 1 To 3 Solution Manual Sample 6eDocument6 pagesChapter 1 To 3 Solution Manual Sample 6eUmer Farooq MirzaNo ratings yet
- List of Inventory On E-Classroom Equipment / Materials: Carmen Central Elementary School Sped CenterDocument2 pagesList of Inventory On E-Classroom Equipment / Materials: Carmen Central Elementary School Sped CenterJane HarlyNo ratings yet
- COAL Lab 8 (22k-4136)Document10 pagesCOAL Lab 8 (22k-4136)k224136 Muhammad Arham AffanNo ratings yet
- Jntua - B.tech. - R20 - Swayam Courses - Odd Semester - 2023 - 21.06.2023Document10 pagesJntua - B.tech. - R20 - Swayam Courses - Odd Semester - 2023 - 21.06.2023Vits 3526 KhushalNo ratings yet
- Amd S1G2 Cpu: Vramx4 Gddr3 512MBDocument56 pagesAmd S1G2 Cpu: Vramx4 Gddr3 512MBحسن علي نوفلNo ratings yet
- Master of Technology in Computer Science: Generative Adversarial NetworkDocument11 pagesMaster of Technology in Computer Science: Generative Adversarial Networkrifat iqbalNo ratings yet
- Lab1 Cald Bese13 ADocument7 pagesLab1 Cald Bese13 Apioneer boysNo ratings yet
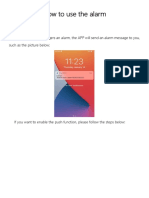
- How To Use The AlarmDocument11 pagesHow To Use The AlarmrbokisNo ratings yet
- Saha Dissertation 2020Document282 pagesSaha Dissertation 2020pwz100% (1)
- Huawei MA5821S enDocument5 pagesHuawei MA5821S enkentmultanNo ratings yet
- PSCAD V5 - HPC Brochure 2023Document2 pagesPSCAD V5 - HPC Brochure 2023vaucejoNo ratings yet