
multiLayerNN PL
multiLayerNN PL
You might also like
- M.K.Jasina, M. Skowronek - Mechanika Budowli Układy Statycznie NiewyznaczalneDocument114 pagesM.K.Jasina, M. Skowronek - Mechanika Budowli Układy Statycznie NiewyznaczalneMariusz MilewskiNo ratings yet
- Architektura Sztucznych Sieci NeuronowychDocument13 pagesArchitektura Sztucznych Sieci NeuronowychGregorNo ratings yet
- Gowno 3Document80 pagesGowno 3mgnc8pkrbpNo ratings yet
- multiClassNN PLDocument22 pagesmultiClassNN PLDinh Duc AnhNo ratings yet
- Trainbpa - Jakosc NauczaniaDocument18 pagesTrainbpa - Jakosc NauczaniaMichalina BoguńNo ratings yet
- Belka Timoshenko Na Sprężystym Podłożu Chodor-ProjektDocument13 pagesBelka Timoshenko Na Sprężystym Podłożu Chodor-ProjektDawid GabrysiakNo ratings yet
- 101 SprawozdanieDocument4 pages101 SprawozdanieAleksandra BrzoskaNo ratings yet
- Cw.4 Cyfrowe Przetwarzanie ObrazowDocument21 pagesCw.4 Cyfrowe Przetwarzanie ObrazowArtur PodolskiNo ratings yet
- Pca NotesDocument3 pagesPca Notesibl81927No ratings yet
- Wyklad 6Document35 pagesWyklad 6MonikaZamłyńskaNo ratings yet
- Cw.3 Dyskretne Sygnaly StochastyczneDocument21 pagesCw.3 Dyskretne Sygnaly StochastyczneArtur PodolskiNo ratings yet
- Signal and System HW4 - SolutionDocument4 pagesSignal and System HW4 - Solutioneccyu97No ratings yet
- W3 InterpolacjaDocument15 pagesW3 InterpolacjaenkantoNo ratings yet
- Signal and System HW5 - SolutionDocument2 pagesSignal and System HW5 - Solutioneccyu97No ratings yet
- RRIC Sprawdzian2022Document14 pagesRRIC Sprawdzian2022psikutateofil69No ratings yet
- Siec HopfieldaDocument10 pagesSiec HopfieldaAnton BranouskiNo ratings yet
- Dwukierunkowa Pamięć Asocjacyjna: 1.1 Podstawowe Informacje o Dwukierunkowej Pamięci AsocjacyjnejDocument4 pagesDwukierunkowa Pamięć Asocjacyjna: 1.1 Podstawowe Informacje o Dwukierunkowej Pamięci AsocjacyjnejAnton BranouskiNo ratings yet
- Siatka DyfrakcyjnaDocument1 pageSiatka DyfrakcyjnaJulkaNo ratings yet
- KF - 10 - 24 Fizyka Relatywistyczna-II - ZbyRasDocument49 pagesKF - 10 - 24 Fizyka Relatywistyczna-II - ZbyRasalekskrzypiecNo ratings yet
- Tsip Student c4Document12 pagesTsip Student c4Sylwia DziewiątakNo ratings yet
- Asd 02Document15 pagesAsd 02Natalya ShakhovskaNo ratings yet
- MES - Krótka PrezentacjaDocument22 pagesMES - Krótka Prezentacjat.matusiak86No ratings yet
- 09 KrzywaDocument5 pages09 KrzywaZbigniew WątrobaNo ratings yet
- 84 Prawdopodobieństwo I Statystyka - 77779Document12 pages84 Prawdopodobieństwo I Statystyka - 77779Anna WilanowskaNo ratings yet
- Matematika2 L1-IntegraliDocument5 pagesMatematika2 L1-IntegralibozanNo ratings yet
- Wzory 2023Document20 pagesWzory 2023MaksNo ratings yet
- Lista 0. Notacja Σ i dwumian NewtonaDocument2 pagesLista 0. Notacja Σ i dwumian NewtonaMalwina JuchiewiczNo ratings yet
- Cwiczenia 2 PochodneDocument10 pagesCwiczenia 2 PochodnetymskiteqNo ratings yet
- Dwukier Pam AsocDocument5 pagesDwukier Pam AsocAnton BranouskiNo ratings yet
- Egz Analiza I 2023Document2 pagesEgz Analiza I 2023kitajNo ratings yet
- Funkcje Tworzące - WykładDocument2 pagesFunkcje Tworzące - WykładPiotrus KNo ratings yet
- Funkcje Dwu ZM 2024 IS+LDocument8 pagesFunkcje Dwu ZM 2024 IS+LpierworodnymajewskiNo ratings yet
- Równania Różniczkowe 2Document2 pagesRównania Różniczkowe 2OliwierNo ratings yet
- Jak Obliczyc Pochodna Funkcji ZlozonejDocument13 pagesJak Obliczyc Pochodna Funkcji ZlozonejlujihujNo ratings yet
- Zadanie 6Document1 pageZadanie 6mateuszpopek1234No ratings yet
- PP Nowy Wyklad1Document86 pagesPP Nowy Wyklad1hugehubimNo ratings yet
- 86 Prawdopodobieństwo I Statystyka 79698Document12 pages86 Prawdopodobieństwo I Statystyka 79698samochodygrabowskiNo ratings yet
- Rozdz7 RBFDocument15 pagesRozdz7 RBFDominik SkalskiNo ratings yet
- Clase 03 - Reglas de Diferenciación (Regla de La Cadena y Regla de La Potencia)Document4 pagesClase 03 - Reglas de Diferenciación (Regla de La Cadena y Regla de La Potencia)jhunior alexanderNo ratings yet
- Anma 13Document2 pagesAnma 13andrzejstepan10No ratings yet
- MPiS30 Z04 - Zmienne LosoweDocument3 pagesMPiS30 Z04 - Zmienne Losowepiotr234No ratings yet
- Ekonometria - WzoryDocument3 pagesEkonometria - WzoryPatrycja KlimekNo ratings yet
- LZ Am2aDocument10 pagesLZ Am2aGieniuNo ratings yet
- Lecture 10Document3 pagesLecture 10kosteczkaaaaNo ratings yet
- Sprawozdanie Lista4 KamilKrolDocument9 pagesSprawozdanie Lista4 KamilKrollerauzhvaNo ratings yet
- Wiad-1098466-Zestaw Wzorów - Całki Pochodne-Do DrukuDocument2 pagesWiad-1098466-Zestaw Wzorów - Całki Pochodne-Do Drukuulka.cz126No ratings yet
- 02 Normal R StanDocument28 pages02 Normal R Stanandrewsynth99No ratings yet
- Of54rozwet2 1Document6 pagesOf54rozwet2 1maciekkolsztynNo ratings yet
- Mdys 03Document1 pageMdys 03funiaczkiNo ratings yet
- Zmienne Losowe I Ich RozkadyDocument89 pagesZmienne Losowe I Ich RozkadyFeliks A. TymuraNo ratings yet
- Wzory RelatDocument1 pageWzory RelatSebastian StolarskiNo ratings yet
- Wzory Z EkonometriiDocument2 pagesWzory Z EkonometriiMonika KobierskaNo ratings yet
- 01 RAS PLDocument13 pages01 RAS PLMoeCakesNo ratings yet
- Kolokwium Zdalne 2Document6 pagesKolokwium Zdalne 2flaming4321No ratings yet
- Математика 3 задачи за вежбање-прв дел PDFDocument10 pagesМатематика 3 задачи за вежбање-прв дел PDFTralalaNo ratings yet
- MiBM Semestr 3 Wyklad 7Document45 pagesMiBM Semestr 3 Wyklad 7Witold RudzińskiNo ratings yet
- Wykps1 1Document39 pagesWykps1 1kasia rządkowskaNo ratings yet
- Kolokwium 2 v5 OnlineDocument1 pageKolokwium 2 v5 OnlineKarolina IgnaczakNo ratings yet
- Szkic Do Wykladow Z Mechaniki - KinematykaDocument24 pagesSzkic Do Wykladow Z Mechaniki - Kinematykaapi-27558726100% (2)













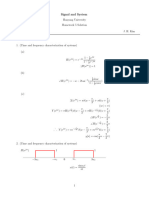













































Download as pdf or txt
You might also like
- M.K.Jasina, M. Skowronek - Mechanika Budowli Układy Statycznie NiewyznaczalneDocument114 pagesM.K.Jasina, M. Skowronek - Mechanika Budowli Układy Statycznie NiewyznaczalneMariusz MilewskiNo ratings yet
- Architektura Sztucznych Sieci NeuronowychDocument13 pagesArchitektura Sztucznych Sieci NeuronowychGregorNo ratings yet
- Gowno 3Document80 pagesGowno 3mgnc8pkrbpNo ratings yet
- multiClassNN PLDocument22 pagesmultiClassNN PLDinh Duc AnhNo ratings yet
- Trainbpa - Jakosc NauczaniaDocument18 pagesTrainbpa - Jakosc NauczaniaMichalina BoguńNo ratings yet
- Belka Timoshenko Na Sprężystym Podłożu Chodor-ProjektDocument13 pagesBelka Timoshenko Na Sprężystym Podłożu Chodor-ProjektDawid GabrysiakNo ratings yet
- 101 SprawozdanieDocument4 pages101 SprawozdanieAleksandra BrzoskaNo ratings yet
- Cw.4 Cyfrowe Przetwarzanie ObrazowDocument21 pagesCw.4 Cyfrowe Przetwarzanie ObrazowArtur PodolskiNo ratings yet
- Pca NotesDocument3 pagesPca Notesibl81927No ratings yet
- Wyklad 6Document35 pagesWyklad 6MonikaZamłyńskaNo ratings yet
- Cw.3 Dyskretne Sygnaly StochastyczneDocument21 pagesCw.3 Dyskretne Sygnaly StochastyczneArtur PodolskiNo ratings yet
- Signal and System HW4 - SolutionDocument4 pagesSignal and System HW4 - Solutioneccyu97No ratings yet
- W3 InterpolacjaDocument15 pagesW3 InterpolacjaenkantoNo ratings yet
- Signal and System HW5 - SolutionDocument2 pagesSignal and System HW5 - Solutioneccyu97No ratings yet
- RRIC Sprawdzian2022Document14 pagesRRIC Sprawdzian2022psikutateofil69No ratings yet
- Siec HopfieldaDocument10 pagesSiec HopfieldaAnton BranouskiNo ratings yet
- Dwukierunkowa Pamięć Asocjacyjna: 1.1 Podstawowe Informacje o Dwukierunkowej Pamięci AsocjacyjnejDocument4 pagesDwukierunkowa Pamięć Asocjacyjna: 1.1 Podstawowe Informacje o Dwukierunkowej Pamięci AsocjacyjnejAnton BranouskiNo ratings yet
- Siatka DyfrakcyjnaDocument1 pageSiatka DyfrakcyjnaJulkaNo ratings yet
- KF - 10 - 24 Fizyka Relatywistyczna-II - ZbyRasDocument49 pagesKF - 10 - 24 Fizyka Relatywistyczna-II - ZbyRasalekskrzypiecNo ratings yet
- Tsip Student c4Document12 pagesTsip Student c4Sylwia DziewiątakNo ratings yet
- Asd 02Document15 pagesAsd 02Natalya ShakhovskaNo ratings yet
- MES - Krótka PrezentacjaDocument22 pagesMES - Krótka Prezentacjat.matusiak86No ratings yet
- 09 KrzywaDocument5 pages09 KrzywaZbigniew WątrobaNo ratings yet
- 84 Prawdopodobieństwo I Statystyka - 77779Document12 pages84 Prawdopodobieństwo I Statystyka - 77779Anna WilanowskaNo ratings yet
- Matematika2 L1-IntegraliDocument5 pagesMatematika2 L1-IntegralibozanNo ratings yet
- Wzory 2023Document20 pagesWzory 2023MaksNo ratings yet
- Lista 0. Notacja Σ i dwumian NewtonaDocument2 pagesLista 0. Notacja Σ i dwumian NewtonaMalwina JuchiewiczNo ratings yet
- Cwiczenia 2 PochodneDocument10 pagesCwiczenia 2 PochodnetymskiteqNo ratings yet
- Dwukier Pam AsocDocument5 pagesDwukier Pam AsocAnton BranouskiNo ratings yet
- Egz Analiza I 2023Document2 pagesEgz Analiza I 2023kitajNo ratings yet
- Funkcje Tworzące - WykładDocument2 pagesFunkcje Tworzące - WykładPiotrus KNo ratings yet
- Funkcje Dwu ZM 2024 IS+LDocument8 pagesFunkcje Dwu ZM 2024 IS+LpierworodnymajewskiNo ratings yet
- Równania Różniczkowe 2Document2 pagesRównania Różniczkowe 2OliwierNo ratings yet
- Jak Obliczyc Pochodna Funkcji ZlozonejDocument13 pagesJak Obliczyc Pochodna Funkcji ZlozonejlujihujNo ratings yet
- Zadanie 6Document1 pageZadanie 6mateuszpopek1234No ratings yet
- PP Nowy Wyklad1Document86 pagesPP Nowy Wyklad1hugehubimNo ratings yet
- 86 Prawdopodobieństwo I Statystyka 79698Document12 pages86 Prawdopodobieństwo I Statystyka 79698samochodygrabowskiNo ratings yet
- Rozdz7 RBFDocument15 pagesRozdz7 RBFDominik SkalskiNo ratings yet
- Clase 03 - Reglas de Diferenciación (Regla de La Cadena y Regla de La Potencia)Document4 pagesClase 03 - Reglas de Diferenciación (Regla de La Cadena y Regla de La Potencia)jhunior alexanderNo ratings yet
- Anma 13Document2 pagesAnma 13andrzejstepan10No ratings yet
- MPiS30 Z04 - Zmienne LosoweDocument3 pagesMPiS30 Z04 - Zmienne Losowepiotr234No ratings yet
- Ekonometria - WzoryDocument3 pagesEkonometria - WzoryPatrycja KlimekNo ratings yet
- LZ Am2aDocument10 pagesLZ Am2aGieniuNo ratings yet
- Lecture 10Document3 pagesLecture 10kosteczkaaaaNo ratings yet
- Sprawozdanie Lista4 KamilKrolDocument9 pagesSprawozdanie Lista4 KamilKrollerauzhvaNo ratings yet
- Wiad-1098466-Zestaw Wzorów - Całki Pochodne-Do DrukuDocument2 pagesWiad-1098466-Zestaw Wzorów - Całki Pochodne-Do Drukuulka.cz126No ratings yet
- 02 Normal R StanDocument28 pages02 Normal R Stanandrewsynth99No ratings yet
- Of54rozwet2 1Document6 pagesOf54rozwet2 1maciekkolsztynNo ratings yet
- Mdys 03Document1 pageMdys 03funiaczkiNo ratings yet
- Zmienne Losowe I Ich RozkadyDocument89 pagesZmienne Losowe I Ich RozkadyFeliks A. TymuraNo ratings yet
- Wzory RelatDocument1 pageWzory RelatSebastian StolarskiNo ratings yet
- Wzory Z EkonometriiDocument2 pagesWzory Z EkonometriiMonika KobierskaNo ratings yet
- 01 RAS PLDocument13 pages01 RAS PLMoeCakesNo ratings yet
- Kolokwium Zdalne 2Document6 pagesKolokwium Zdalne 2flaming4321No ratings yet
- Математика 3 задачи за вежбање-прв дел PDFDocument10 pagesМатематика 3 задачи за вежбање-прв дел PDFTralalaNo ratings yet
- MiBM Semestr 3 Wyklad 7Document45 pagesMiBM Semestr 3 Wyklad 7Witold RudzińskiNo ratings yet
- Wykps1 1Document39 pagesWykps1 1kasia rządkowskaNo ratings yet
- Kolokwium 2 v5 OnlineDocument1 pageKolokwium 2 v5 OnlineKarolina IgnaczakNo ratings yet
- Szkic Do Wykladow Z Mechaniki - KinematykaDocument24 pagesSzkic Do Wykladow Z Mechaniki - Kinematykaapi-27558726100% (2)