
Tekst 24 Po Piech, Mastalerz
Tekst 24 Po Piech, Mastalerz
You might also like
- Rozdział 1. Środowisko Przyrodnicze Polski Cz.2 (T. 7-14) Zadania - KLASA 7Document4 pagesRozdział 1. Środowisko Przyrodnicze Polski Cz.2 (T. 7-14) Zadania - KLASA 7Marzena Pakosz-Białasik86% (14)
- 4f17b13d23faaf017cf12476bda840b5Document6 pages4f17b13d23faaf017cf12476bda840b5Karolina Kamińska100% (1)
- SMIO - GPR - Analiza Wskaznikowa 2019Document63 pagesSMIO - GPR - Analiza Wskaznikowa 2019lupus00No ratings yet
- Bak Zastosowanie Netod Wielowymiarowj Analizy PorownawczejDocument15 pagesBak Zastosowanie Netod Wielowymiarowj Analizy PorownawczejCymekNo ratings yet
- Wprowadzenie - Koncepcja I Cel PracyDocument17 pagesWprowadzenie - Koncepcja I Cel PracyZuzia PłaczekNo ratings yet
- Regional Diversity of Economic Development in Poland: Regionalne Zróżnicowanie Rozwoju Gospodarczego W PolsceDocument12 pagesRegional Diversity of Economic Development in Poland: Regionalne Zróżnicowanie Rozwoju Gospodarczego W PolsceOlaNo ratings yet
- Metodologia Badania Ilosciowe 1Document3 pagesMetodologia Badania Ilosciowe 1Julia ZogrodnikNo ratings yet
- Podstawowe Informacje Dotyczace Uzyskiwania Kwalifikacji 6 - 2Document9 pagesPodstawowe Informacje Dotyczace Uzyskiwania Kwalifikacji 6 - 2lucus7756No ratings yet
- Zeszyt29 3Document15 pagesZeszyt29 3pNo ratings yet
- Metody I Techniki Pomiaru Efektów Działań Public Relations Wykorzystywane W Branży Public RelationsDocument24 pagesMetody I Techniki Pomiaru Efektów Działań Public Relations Wykorzystywane W Branży Public RelationsDariusz TworzydłoNo ratings yet
- 808 1328 1 SMDocument16 pages808 1328 1 SMSonia DzierzyńskaNo ratings yet
- Annales Universitatis Mariae Curie-SkłodowskaDocument19 pagesAnnales Universitatis Mariae Curie-Skłodowskaekarkade15No ratings yet
- Raport GDZ 0Document40 pagesRaport GDZ 0Mateusz ChaładaNo ratings yet
- Perspektywy Rozwoju Firm Z Branży Zabezpieczeń, Scenariusze ZmianDocument17 pagesPerspektywy Rozwoju Firm Z Branży Zabezpieczeń, Scenariusze ZmianInstytut Zachodni w PoznaniuNo ratings yet
- W1 Pojęcia Podstawowe I Definicje Metrologiczne ScaloneDocument546 pagesW1 Pojęcia Podstawowe I Definicje Metrologiczne Scalonemax09343No ratings yet
- Civil EnginneringDocument3 pagesCivil EnginneringPulp FictionNo ratings yet
- Metody Badań Rynku - Wykład 1: Data TematDocument272 pagesMetody Badań Rynku - Wykład 1: Data TematPaulinaNo ratings yet
- Zaliczenie Analizy KryminalneDocument4 pagesZaliczenie Analizy Kryminalnekasia52aNo ratings yet
- Tel FonoholizmDocument91 pagesTel FonoholizmJakub CzmychNo ratings yet
- Znaczenie Metrologii I Inżynierii PDocument4 pagesZnaczenie Metrologii I Inżynierii PAngelika ZiółkowskaNo ratings yet
- Prototypowanie Urbanistyczne A InneDocument3 pagesPrototypowanie Urbanistyczne A InneroallaNo ratings yet
- Analizaekonomiczno-Przestrzenna Short VerDocument14 pagesAnalizaekonomiczno-Przestrzenna Short Verkajtek.kubicaNo ratings yet
- HTTPWWW Witu Mil Plwwwbiuletynzeszyty20100115p77Document8 pagesHTTPWWW Witu Mil Plwwwbiuletynzeszyty20100115p77jakuborczykNo ratings yet
- Podkarpacki Barometr TurystycznyDocument106 pagesPodkarpacki Barometr TurystycznypetrykivkaaNo ratings yet
- Niepewności WynikówrDocument13 pagesNiepewności WynikówrBartłomiej CzekierNo ratings yet
- Statystyka I Analiza Danych PomiarowychDocument2 pagesStatystyka I Analiza Danych Pomiarowychzuzka204No ratings yet
- Wykłady PsychometriaDocument22 pagesWykłady PsychometriaВікторія БернашевськаNo ratings yet
- W1 Pojęcia Podstawowe I Definicje Metrologiczne Potok 2Document57 pagesW1 Pojęcia Podstawowe I Definicje Metrologiczne Potok 2mjozwik33No ratings yet
- Struktura Wynagrodzen Wedlug Zawodow W Pazdzierniku 2018Document250 pagesStruktura Wynagrodzen Wedlug Zawodow W Pazdzierniku 2018neyakxtfyfbcqcvyipNo ratings yet
- Analiza Kondycji Branży Public RelationsDocument22 pagesAnaliza Kondycji Branży Public RelationsDariusz TworzydłoNo ratings yet
- Załącznik Do Uchwały NR 411Document12 pagesZałącznik Do Uchwały NR 411Єлизавета ДемченкоNo ratings yet
- Mozliwosci Metodologiczne W BadaniachDocument16 pagesMozliwosci Metodologiczne W Badaniachm.gierczykNo ratings yet
- USE OF Project Management Methodologies AND Project Risk Management IN THE Light OF Empirical ResearchDocument9 pagesUSE OF Project Management Methodologies AND Project Risk Management IN THE Light OF Empirical ResearchDeepak GudleNo ratings yet
- Comparison-Of-Liquidity-Based-And-Financial-Performance-Based-Indicators-In-Financial-Analysis - Content File PDFDocument16 pagesComparison-Of-Liquidity-Based-And-Financial-Performance-Based-Indicators-In-Financial-Analysis - Content File PDFlkwintelNo ratings yet
- Cresswell ProceduryDocument6 pagesCresswell ProceduryMadleneNo ratings yet
- br05 04 Cieslak PLDocument8 pagesbr05 04 Cieslak PLMartyna ŻmudaNo ratings yet
- Article - N - Comparative Study of The Results of The Extinguishing Powder Grain Size Analysis Carried Out by Different MethodsDocument8 pagesArticle - N - Comparative Study of The Results of The Extinguishing Powder Grain Size Analysis Carried Out by Different MethodsPacho ArbelaezNo ratings yet
- Greg, Art11Document9 pagesGreg, Art11sulayla marianoNo ratings yet
- p060 PDFDocument12 pagesp060 PDFOla MakowskaNo ratings yet
- Zastosowanie Środków Inteligentnych Systemów Transportu Do Obsługi Imprez MasowychDocument8 pagesZastosowanie Środków Inteligentnych Systemów Transportu Do Obsługi Imprez Masowychdkowalska853No ratings yet
- Autoethnography Technique Method or New Paradigm On Methodological Status of Autoethnography Content File PDFDocument23 pagesAutoethnography Technique Method or New Paradigm On Methodological Status of Autoethnography Content File PDFkotłapacz 123No ratings yet
- PL Strategiczne Obszary Dzialania 2014 2020Document19 pagesPL Strategiczne Obszary Dzialania 2014 2020Ewa DomaNo ratings yet
- MetodologiaDocument7 pagesMetodologiadominikaszczesniak3055No ratings yet
- Fundusze Sesja 2024Document10 pagesFundusze Sesja 2024Merci OlNo ratings yet
- Niekonwencjonalne MetodyDocument20 pagesNiekonwencjonalne Metodywirus44No ratings yet
- Strategia Rozwoju Transportu Do 2020Document13 pagesStrategia Rozwoju Transportu Do 2020Piotr BOCIANNo ratings yet
- Administracja PublicznaDocument24 pagesAdministracja PublicznaSara SyskaNo ratings yet
- Niepewności Pomiarów W Metodzie RegDocument13 pagesNiepewności Pomiarów W Metodzie RegJanNo ratings yet
- The Netflix Effect. Technology and Entertainment in The 21st Century (PDFDrive) (073-101) .En - pl2Document29 pagesThe Netflix Effect. Technology and Entertainment in The 21st Century (PDFDrive) (073-101) .En - pl2DominikaNo ratings yet
- Diagnoza W Pracy Nauczyciela - TerapeutDocument12 pagesDiagnoza W Pracy Nauczyciela - TerapeutTibNo ratings yet
- Zdjęcie Na Tekst - Cardscanner - Co - KopiaDocument11 pagesZdjęcie Na Tekst - Cardscanner - Co - Kopiaadamwsk290No ratings yet
- Kurs IBM SPSS Statistics - Krzysztof JurekDocument84 pagesKurs IBM SPSS Statistics - Krzysztof JurekmaciekbokuNo ratings yet
- MASZTALERZ 2012 Pomiar Wartosci - W Kierunku IntegracjiDocument8 pagesMASZTALERZ 2012 Pomiar Wartosci - W Kierunku IntegracjiDziyana TaranovichNo ratings yet
- 11 M.Jaciow Miedzynarodowe BadaniaDocument11 pages11 M.Jaciow Miedzynarodowe Badaniaizy40690No ratings yet
- Jakosc ZyciaDocument20 pagesJakosc ZyciaKNo ratings yet
- Rozprawa Doktorska Kowalska MariaDocument178 pagesRozprawa Doktorska Kowalska MariapanskyrimNo ratings yet
- Strategia - Rozwoju Gminy Dębowiec Na Lata 2016-2025Document91 pagesStrategia - Rozwoju Gminy Dębowiec Na Lata 2016-2025waldo79No ratings yet
- PRM 2015-2 05 Szoltysek OtrebaDocument6 pagesPRM 2015-2 05 Szoltysek OtrebaKamil RomanNo ratings yet
- BRiM W1 MergedDocument334 pagesBRiM W1 MergedJakub ChojnackiNo ratings yet
- Metody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Document26 pagesMetody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Ewa ZalewskaNo ratings yet
- Ewaluacja W 5 KrokachDocument27 pagesEwaluacja W 5 Krokachjustyna58999No ratings yet
- Hydrosfera PoprawaDocument2 pagesHydrosfera Poprawazbereznikus50% (2)
- Podreczniki 2021.2022 - Na StroneDocument27 pagesPodreczniki 2021.2022 - Na StroneXGULDANXNo ratings yet
- 0518 Test Ameryka Grupa A 1589747669Document3 pages0518 Test Ameryka Grupa A 1589747669Axer OliNo ratings yet
- Program Nauczania SP GeografiaDocument73 pagesProgram Nauczania SP Geografiagaimg manNo ratings yet
- Europa Prezentacja KL 6Document28 pagesEuropa Prezentacja KL 6Mariola R.MNo ratings yet





























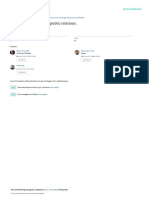
























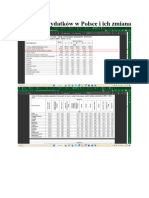











Download as pdf or txt
You might also like
- Rozdział 1. Środowisko Przyrodnicze Polski Cz.2 (T. 7-14) Zadania - KLASA 7Document4 pagesRozdział 1. Środowisko Przyrodnicze Polski Cz.2 (T. 7-14) Zadania - KLASA 7Marzena Pakosz-Białasik86% (14)
- 4f17b13d23faaf017cf12476bda840b5Document6 pages4f17b13d23faaf017cf12476bda840b5Karolina Kamińska100% (1)
- SMIO - GPR - Analiza Wskaznikowa 2019Document63 pagesSMIO - GPR - Analiza Wskaznikowa 2019lupus00No ratings yet
- Bak Zastosowanie Netod Wielowymiarowj Analizy PorownawczejDocument15 pagesBak Zastosowanie Netod Wielowymiarowj Analizy PorownawczejCymekNo ratings yet
- Wprowadzenie - Koncepcja I Cel PracyDocument17 pagesWprowadzenie - Koncepcja I Cel PracyZuzia PłaczekNo ratings yet
- Regional Diversity of Economic Development in Poland: Regionalne Zróżnicowanie Rozwoju Gospodarczego W PolsceDocument12 pagesRegional Diversity of Economic Development in Poland: Regionalne Zróżnicowanie Rozwoju Gospodarczego W PolsceOlaNo ratings yet
- Metodologia Badania Ilosciowe 1Document3 pagesMetodologia Badania Ilosciowe 1Julia ZogrodnikNo ratings yet
- Podstawowe Informacje Dotyczace Uzyskiwania Kwalifikacji 6 - 2Document9 pagesPodstawowe Informacje Dotyczace Uzyskiwania Kwalifikacji 6 - 2lucus7756No ratings yet
- Zeszyt29 3Document15 pagesZeszyt29 3pNo ratings yet
- Metody I Techniki Pomiaru Efektów Działań Public Relations Wykorzystywane W Branży Public RelationsDocument24 pagesMetody I Techniki Pomiaru Efektów Działań Public Relations Wykorzystywane W Branży Public RelationsDariusz TworzydłoNo ratings yet
- 808 1328 1 SMDocument16 pages808 1328 1 SMSonia DzierzyńskaNo ratings yet
- Annales Universitatis Mariae Curie-SkłodowskaDocument19 pagesAnnales Universitatis Mariae Curie-Skłodowskaekarkade15No ratings yet
- Raport GDZ 0Document40 pagesRaport GDZ 0Mateusz ChaładaNo ratings yet
- Perspektywy Rozwoju Firm Z Branży Zabezpieczeń, Scenariusze ZmianDocument17 pagesPerspektywy Rozwoju Firm Z Branży Zabezpieczeń, Scenariusze ZmianInstytut Zachodni w PoznaniuNo ratings yet
- W1 Pojęcia Podstawowe I Definicje Metrologiczne ScaloneDocument546 pagesW1 Pojęcia Podstawowe I Definicje Metrologiczne Scalonemax09343No ratings yet
- Civil EnginneringDocument3 pagesCivil EnginneringPulp FictionNo ratings yet
- Metody Badań Rynku - Wykład 1: Data TematDocument272 pagesMetody Badań Rynku - Wykład 1: Data TematPaulinaNo ratings yet
- Zaliczenie Analizy KryminalneDocument4 pagesZaliczenie Analizy Kryminalnekasia52aNo ratings yet
- Tel FonoholizmDocument91 pagesTel FonoholizmJakub CzmychNo ratings yet
- Znaczenie Metrologii I Inżynierii PDocument4 pagesZnaczenie Metrologii I Inżynierii PAngelika ZiółkowskaNo ratings yet
- Prototypowanie Urbanistyczne A InneDocument3 pagesPrototypowanie Urbanistyczne A InneroallaNo ratings yet
- Analizaekonomiczno-Przestrzenna Short VerDocument14 pagesAnalizaekonomiczno-Przestrzenna Short Verkajtek.kubicaNo ratings yet
- HTTPWWW Witu Mil Plwwwbiuletynzeszyty20100115p77Document8 pagesHTTPWWW Witu Mil Plwwwbiuletynzeszyty20100115p77jakuborczykNo ratings yet
- Podkarpacki Barometr TurystycznyDocument106 pagesPodkarpacki Barometr TurystycznypetrykivkaaNo ratings yet
- Niepewności WynikówrDocument13 pagesNiepewności WynikówrBartłomiej CzekierNo ratings yet
- Statystyka I Analiza Danych PomiarowychDocument2 pagesStatystyka I Analiza Danych Pomiarowychzuzka204No ratings yet
- Wykłady PsychometriaDocument22 pagesWykłady PsychometriaВікторія БернашевськаNo ratings yet
- W1 Pojęcia Podstawowe I Definicje Metrologiczne Potok 2Document57 pagesW1 Pojęcia Podstawowe I Definicje Metrologiczne Potok 2mjozwik33No ratings yet
- Struktura Wynagrodzen Wedlug Zawodow W Pazdzierniku 2018Document250 pagesStruktura Wynagrodzen Wedlug Zawodow W Pazdzierniku 2018neyakxtfyfbcqcvyipNo ratings yet
- Analiza Kondycji Branży Public RelationsDocument22 pagesAnaliza Kondycji Branży Public RelationsDariusz TworzydłoNo ratings yet
- Załącznik Do Uchwały NR 411Document12 pagesZałącznik Do Uchwały NR 411Єлизавета ДемченкоNo ratings yet
- Mozliwosci Metodologiczne W BadaniachDocument16 pagesMozliwosci Metodologiczne W Badaniachm.gierczykNo ratings yet
- USE OF Project Management Methodologies AND Project Risk Management IN THE Light OF Empirical ResearchDocument9 pagesUSE OF Project Management Methodologies AND Project Risk Management IN THE Light OF Empirical ResearchDeepak GudleNo ratings yet
- Comparison-Of-Liquidity-Based-And-Financial-Performance-Based-Indicators-In-Financial-Analysis - Content File PDFDocument16 pagesComparison-Of-Liquidity-Based-And-Financial-Performance-Based-Indicators-In-Financial-Analysis - Content File PDFlkwintelNo ratings yet
- Cresswell ProceduryDocument6 pagesCresswell ProceduryMadleneNo ratings yet
- br05 04 Cieslak PLDocument8 pagesbr05 04 Cieslak PLMartyna ŻmudaNo ratings yet
- Article - N - Comparative Study of The Results of The Extinguishing Powder Grain Size Analysis Carried Out by Different MethodsDocument8 pagesArticle - N - Comparative Study of The Results of The Extinguishing Powder Grain Size Analysis Carried Out by Different MethodsPacho ArbelaezNo ratings yet
- Greg, Art11Document9 pagesGreg, Art11sulayla marianoNo ratings yet
- p060 PDFDocument12 pagesp060 PDFOla MakowskaNo ratings yet
- Zastosowanie Środków Inteligentnych Systemów Transportu Do Obsługi Imprez MasowychDocument8 pagesZastosowanie Środków Inteligentnych Systemów Transportu Do Obsługi Imprez Masowychdkowalska853No ratings yet
- Autoethnography Technique Method or New Paradigm On Methodological Status of Autoethnography Content File PDFDocument23 pagesAutoethnography Technique Method or New Paradigm On Methodological Status of Autoethnography Content File PDFkotłapacz 123No ratings yet
- PL Strategiczne Obszary Dzialania 2014 2020Document19 pagesPL Strategiczne Obszary Dzialania 2014 2020Ewa DomaNo ratings yet
- MetodologiaDocument7 pagesMetodologiadominikaszczesniak3055No ratings yet
- Fundusze Sesja 2024Document10 pagesFundusze Sesja 2024Merci OlNo ratings yet
- Niekonwencjonalne MetodyDocument20 pagesNiekonwencjonalne Metodywirus44No ratings yet
- Strategia Rozwoju Transportu Do 2020Document13 pagesStrategia Rozwoju Transportu Do 2020Piotr BOCIANNo ratings yet
- Administracja PublicznaDocument24 pagesAdministracja PublicznaSara SyskaNo ratings yet
- Niepewności Pomiarów W Metodzie RegDocument13 pagesNiepewności Pomiarów W Metodzie RegJanNo ratings yet
- The Netflix Effect. Technology and Entertainment in The 21st Century (PDFDrive) (073-101) .En - pl2Document29 pagesThe Netflix Effect. Technology and Entertainment in The 21st Century (PDFDrive) (073-101) .En - pl2DominikaNo ratings yet
- Diagnoza W Pracy Nauczyciela - TerapeutDocument12 pagesDiagnoza W Pracy Nauczyciela - TerapeutTibNo ratings yet
- Zdjęcie Na Tekst - Cardscanner - Co - KopiaDocument11 pagesZdjęcie Na Tekst - Cardscanner - Co - Kopiaadamwsk290No ratings yet
- Kurs IBM SPSS Statistics - Krzysztof JurekDocument84 pagesKurs IBM SPSS Statistics - Krzysztof JurekmaciekbokuNo ratings yet
- MASZTALERZ 2012 Pomiar Wartosci - W Kierunku IntegracjiDocument8 pagesMASZTALERZ 2012 Pomiar Wartosci - W Kierunku IntegracjiDziyana TaranovichNo ratings yet
- 11 M.Jaciow Miedzynarodowe BadaniaDocument11 pages11 M.Jaciow Miedzynarodowe Badaniaizy40690No ratings yet
- Jakosc ZyciaDocument20 pagesJakosc ZyciaKNo ratings yet
- Rozprawa Doktorska Kowalska MariaDocument178 pagesRozprawa Doktorska Kowalska MariapanskyrimNo ratings yet
- Strategia - Rozwoju Gminy Dębowiec Na Lata 2016-2025Document91 pagesStrategia - Rozwoju Gminy Dębowiec Na Lata 2016-2025waldo79No ratings yet
- PRM 2015-2 05 Szoltysek OtrebaDocument6 pagesPRM 2015-2 05 Szoltysek OtrebaKamil RomanNo ratings yet
- BRiM W1 MergedDocument334 pagesBRiM W1 MergedJakub ChojnackiNo ratings yet
- Metody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Document26 pagesMetody I Narzędzia Opisu Systemów Gospodarczych: Ćwiczenia 1Ewa ZalewskaNo ratings yet
- Ewaluacja W 5 KrokachDocument27 pagesEwaluacja W 5 Krokachjustyna58999No ratings yet
- Hydrosfera PoprawaDocument2 pagesHydrosfera Poprawazbereznikus50% (2)
- Podreczniki 2021.2022 - Na StroneDocument27 pagesPodreczniki 2021.2022 - Na StroneXGULDANXNo ratings yet
- 0518 Test Ameryka Grupa A 1589747669Document3 pages0518 Test Ameryka Grupa A 1589747669Axer OliNo ratings yet
- Program Nauczania SP GeografiaDocument73 pagesProgram Nauczania SP Geografiagaimg manNo ratings yet
- Europa Prezentacja KL 6Document28 pagesEuropa Prezentacja KL 6Mariola R.MNo ratings yet