Download as pdf or txt
You might also like
- Problem 1: Markov Reward ProcessDocument3 pagesProblem 1: Markov Reward ProcessAbdul TaufeeqNo ratings yet
- Cse3521 Hw1 SolutionsDocument5 pagesCse3521 Hw1 Solutionsindrajeet4saravananNo ratings yet
- Answers To Workbook EMDocument32 pagesAnswers To Workbook EMRewanNo ratings yet
- 242 Sheet 02 02Document6 pages242 Sheet 02 02RewanNo ratings yet
- Assignment 1Document5 pagesAssignment 1SHUBHAM PANCHALNo ratings yet
- AI 3000 / CS 5500: Reinforcement Learning Assignment 1: Problem 1: Markov Reward ProcessDocument5 pagesAI 3000 / CS 5500: Reinforcement Learning Assignment 1: Problem 1: Markov Reward ProcessSHUBHAM PANCHALNo ratings yet
- CS6700 RL 2024 Wa1Document7 pagesCS6700 RL 2024 Wa1Rahul me20b145No ratings yet
- Assignment 4 (Sol.) : Reinforcement LearningDocument6 pagesAssignment 4 (Sol.) : Reinforcement Learningsimar rocksNo ratings yet
- Assignment 4Document6 pagesAssignment 4SHUBHAM PANCHALNo ratings yet
- CS229 Andrew NGDocument15 pagesCS229 Andrew NGEdwardNo ratings yet
- EE675A Lec12Document5 pagesEE675A Lec12SAURABH VISHWAKARMANo ratings yet
- Reinforcement Learning and Control: CS229 Lecture NotesDocument7 pagesReinforcement Learning and Control: CS229 Lecture NotesShubhamKhodiyarNo ratings yet
- Lec 4Document16 pagesLec 4jessica magdyNo ratings yet
- Assignment 5 (Sol.) : Reinforcement LearningDocument4 pagesAssignment 5 (Sol.) : Reinforcement Learningsachin bhadangNo ratings yet
- Automatic Market-Making With Dynamic Peg: Michael Egorov, Curve Finance (Swiss Stake GMBH) June 9, 2021Document5 pagesAutomatic Market-Making With Dynamic Peg: Michael Egorov, Curve Finance (Swiss Stake GMBH) June 9, 2021Jumady SquarepantsNo ratings yet
- A12 Spring2024Document5 pagesA12 Spring2024sofia pillaiNo ratings yet
- Neoscholar DPRLHW8Document3 pagesNeoscholar DPRLHW8507832497No ratings yet
- Markov Decision Processes and Exact Solution MethodsDocument34 pagesMarkov Decision Processes and Exact Solution MethodsThườngNhẫnNo ratings yet
- Tutorial III Root Locus DesignDocument25 pagesTutorial III Root Locus Designapi-3856083100% (3)
- Understanding and Applying Kalman FilteringDocument37 pagesUnderstanding and Applying Kalman FilteringKoustuvGaraiNo ratings yet
- Understanding and Applying Kalman FilteringDocument37 pagesUnderstanding and Applying Kalman FilteringosamazimNo ratings yet
- 6b SolnDocument3 pages6b SolnOmar AhmedNo ratings yet
- ReportDocument3 pagesReportRahul RNo ratings yet
- Practice MidtermDocument4 pagesPractice MidtermArka MitraNo ratings yet
- MDP 2Document53 pagesMDP 2Tejas MhaiskarNo ratings yet
- Reinforcement Learning and Control: CS229 Lecture NotesDocument15 pagesReinforcement Learning and Control: CS229 Lecture NotesIvan AvramovNo ratings yet
- CMO Assignment 2 Revision 3Document4 pagesCMO Assignment 2 Revision 3rishi guptaNo ratings yet
- KalmanDocument34 pagesKalmanbilal309No ratings yet
- Design and Analysis of Algorithms Loop Correctness: Ade Azurat - Fasilkom UI March 10, 2011Document8 pagesDesign and Analysis of Algorithms Loop Correctness: Ade Azurat - Fasilkom UI March 10, 2011IisAfriyantiNo ratings yet
- EE675A Lecture 16Document6 pagesEE675A Lecture 16sachin bhadangNo ratings yet
- Homework #3: MDPS, Q-Learning, &: PomdpsDocument18 pagesHomework #3: MDPS, Q-Learning, &: Pomdpsshivam pradhanNo ratings yet
- Lecture 15Document4 pagesLecture 15sachin bhadangNo ratings yet
- Non-Deterministic Reward and ActionDocument2 pagesNon-Deterministic Reward and ActionReddy BunnyNo ratings yet
- An Introduction To Policy Search Methods: Thomas FurmstonDocument33 pagesAn Introduction To Policy Search Methods: Thomas Furmstonbehera.eceNo ratings yet
- CHAPTER 21-FinalDocument20 pagesCHAPTER 21-FinalHEMANTH KUMAR.KOLANo ratings yet
- Practice Midterm 2010Document4 pagesPractice Midterm 2010Erico ArchetiNo ratings yet
- 19.5 Markov Decision Processes: Resolving Unbounded Expected RewardsDocument13 pages19.5 Markov Decision Processes: Resolving Unbounded Expected RewardsmatbddNo ratings yet
- Approximate RLDocument10 pagesApproximate RL杨烨峰No ratings yet
- Linear Quadratic ControlDocument7 pagesLinear Quadratic ControlnaumzNo ratings yet
- Notes ValueFunctionIterationDocument10 pagesNotes ValueFunctionIterationapurva.tudekarNo ratings yet
- MRRW Bound and Isoperimetric Problems: 6.1 PreliminariesDocument8 pagesMRRW Bound and Isoperimetric Problems: 6.1 PreliminariesAshoka VanjareNo ratings yet
- 5.4-Reinforcement Learning-Part1-IntroductionDocument15 pages5.4-Reinforcement Learning-Part1-Introductionpolinati.vinesh2023No ratings yet
- LittomoreDocument169 pagesLittomoreKumar RahulNo ratings yet
- Reinforcement Learning in A NutshellDocument12 pagesReinforcement Learning in A NutshellDope IndianNo ratings yet
- Val Fun IterDocument10 pagesVal Fun IterBruno AvilaNo ratings yet
- Q-Learning and Deep Q Networks (DQN)Document52 pagesQ-Learning and Deep Q Networks (DQN)bscjjwNo ratings yet
- Notes 3Document8 pagesNotes 3Sriram BalasubramanianNo ratings yet
- EE 675 Lecture 27th MarchDocument4 pagesEE 675 Lecture 27th Marchsachin bhadangNo ratings yet
- CS 229, Public Course Problem Set #3: Learning Theory and Unsuper-Vised LearningDocument4 pagesCS 229, Public Course Problem Set #3: Learning Theory and Unsuper-Vised Learningsuhar adiNo ratings yet
- Constraint Satisfaction ProblemDocument3 pagesConstraint Satisfaction ProblemSushmita MhamaneNo ratings yet
- Wa 1Document9 pagesWa 1Nohan JoemonNo ratings yet
- cs229 Notes13Document15 pagescs229 Notes13Samarth ChauhanNo ratings yet
- MCMC With Temporary Mapping and Caching With Application On Gaussian Process RegressionDocument16 pagesMCMC With Temporary Mapping and Caching With Application On Gaussian Process RegressionChunyi WangNo ratings yet
- 7th Lecture Note 230515 135845Document21 pages7th Lecture Note 230515 135845Girie YumNo ratings yet
- Hw3sol PDFDocument8 pagesHw3sol PDFShy PeachDNo ratings yet
- Assignment - 10: Shyam Shankar H R EE15B127 November 9, 2017Document15 pagesAssignment - 10: Shyam Shankar H R EE15B127 November 9, 2017Shyam ShankarNo ratings yet
- Reinforcement Learning NeuralDocument4 pagesReinforcement Learning NeuralMolyNo ratings yet
- Lnotes 05Document5 pagesLnotes 05mouaad ibnealryfNo ratings yet
- Unit 3 - Analysis Design of Algorithm - WWW - Rgpvnotes.inDocument8 pagesUnit 3 - Analysis Design of Algorithm - WWW - Rgpvnotes.inPranjal ChawdaNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Lecture 09Document4 pagesLecture 09RewanNo ratings yet
- Lecture 1 Computer Organization 2022Document44 pagesLecture 1 Computer Organization 2022RewanNo ratings yet
- Material Identification ReportDocument11 pagesMaterial Identification ReportRewanNo ratings yet
- The Importance of Art To SocietiesDocument4 pagesThe Importance of Art To SocietiesRewanNo ratings yet
- CH 02Document71 pagesCH 02RewanNo ratings yet
- CH 01Document78 pagesCH 01RewanNo ratings yet
- Lecture 2 Computer Organization 2022Document28 pagesLecture 2 Computer Organization 2022RewanNo ratings yet
- MSE 212 Material Science Lab Experiment (3) : Tensile Test: Submitted byDocument13 pagesMSE 212 Material Science Lab Experiment (3) : Tensile Test: Submitted byRewanNo ratings yet
- Fundamentals of Materials ScienceDocument21 pagesFundamentals of Materials ScienceRewanNo ratings yet
- Synthesis of Methyl OrangeDocument4 pagesSynthesis of Methyl OrangeRewanNo ratings yet
- MSE 222 Materials Science LabDocument12 pagesMSE 222 Materials Science LabRewanNo ratings yet
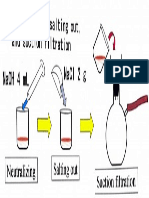
- Naoh 4 ML: Neutralizing, Salting Out, and Suction FiltrationDocument1 pageNaoh 4 ML: Neutralizing, Salting Out, and Suction FiltrationRewanNo ratings yet
- Procedure: (Exp. 1) Preparation of A Standard Solution of Sulfamic AcidDocument3 pagesProcedure: (Exp. 1) Preparation of A Standard Solution of Sulfamic AcidRewanNo ratings yet
- 20 ML of Water: Watch Glass Folded Filter Paper Funnel Conical BeakerDocument1 page20 ML of Water: Watch Glass Folded Filter Paper Funnel Conical BeakerRewanNo ratings yet
- 9 The Ultimate Igcse Guide To Chemistry by CgpwnedDocument272 pages9 The Ultimate Igcse Guide To Chemistry by CgpwnedRewanNo ratings yet
- IGCSE Chemistry Work Book by Richard Harwood PDFDocument97 pagesIGCSE Chemistry Work Book by Richard Harwood PDFRewanNo ratings yet
- Sanjeev Sharma CVDocument2 pagesSanjeev Sharma CVGabriel Reid100% (1)
- PGMDPDocument11 pagesPGMDPsnehilNo ratings yet
- Deep Reinforcement LearningDocument410 pagesDeep Reinforcement LearningaaaaaaaxcNo ratings yet
- Energy Allocation and Utilization For Wirelessly Powered Iot NetworksDocument11 pagesEnergy Allocation and Utilization For Wirelessly Powered Iot NetworksFritz FatigaNo ratings yet
- Inference and Learning From Data Volume 1 Foundations 1St Edition Ali H Sayed Online Ebook Texxtbook Full Chapter PDFDocument69 pagesInference and Learning From Data Volume 1 Foundations 1St Edition Ali H Sayed Online Ebook Texxtbook Full Chapter PDFcathy.matta501100% (9)
- Ps 4Document6 pagesPs 4tony1337No ratings yet
- Applying Q (λ) -learning in Deep Reinforcement Learning to Play Atari GamesDocument6 pagesApplying Q (λ) -learning in Deep Reinforcement Learning to Play Atari GamesomidbundyNo ratings yet
- Lnotes 03Document11 pagesLnotes 03mouaad ibnealryfNo ratings yet
- Exam Prep 4 Solutions: Q1. MDPS: Dice BonanzaDocument4 pagesExam Prep 4 Solutions: Q1. MDPS: Dice BonanzaAskIIT IanNo ratings yet
- UG Project Team - 08Document7 pagesUG Project Team - 08Anand PaulNo ratings yet
- Sem 6 BTCS 602 18Document2 pagesSem 6 BTCS 602 18Mohit ThakurNo ratings yet
- Lecture 9 - RLDocument82 pagesLecture 9 - RL鄭博仁No ratings yet
- RL CheatsheetDocument2 pagesRL CheatsheetrakesharumallaNo ratings yet
- Final Exam: CS 188 Spring 2011 Introduction To Artificial IntelligenceDocument14 pagesFinal Exam: CS 188 Spring 2011 Introduction To Artificial IntelligenceMOhmedSharaf0% (1)
- Dynamic Programming: Thomas J. Sargent and John Stachurski January 16, 2024Document446 pagesDynamic Programming: Thomas J. Sargent and John Stachurski January 16, 2024ferrypangaribuanNo ratings yet
- Artificial Intelligence in 5GDocument34 pagesArtificial Intelligence in 5GSakhawat Ali SahgalNo ratings yet
- Minimizing AoI Using Hybrid NomaDocument7 pagesMinimizing AoI Using Hybrid NomaVishnu TezNo ratings yet
- Markov Decision ProcessDocument11 pagesMarkov Decision ProcessHarpreet Singh BaggaNo ratings yet
- DSC3215-ZHQ (I, 1718)Document2 pagesDSC3215-ZHQ (I, 1718)caspersoongNo ratings yet
- Markov Chain - ExeDocument6 pagesMarkov Chain - ExeDiego SalazarNo ratings yet
- Markov DecisionDocument11 pagesMarkov Decisionradha gulatiNo ratings yet
- UT Dallas Syllabus For cs6375.501.07f Taught by Yu Chung NG (Ycn041000)Document5 pagesUT Dallas Syllabus For cs6375.501.07f Taught by Yu Chung NG (Ycn041000)UT Dallas Provost's Technology GroupNo ratings yet
- Static and Dynamic Appointment Scheduling To Improve Patient Access TimeDocument13 pagesStatic and Dynamic Appointment Scheduling To Improve Patient Access TimeBen Sghaier SaydaNo ratings yet
- AI (6th) May2022Document2 pagesAI (6th) May2022Armaan SinghNo ratings yet
- CS8691 Unit 4Document46 pagesCS8691 Unit 4Cse15No ratings yet
- ML Unit 5 (ChatGPT)Document17 pagesML Unit 5 (ChatGPT)Tufail DarNo ratings yet
- Artificial Intelligence FinalsDocument30 pagesArtificial Intelligence FinalsFrancheska Padilla BotalonNo ratings yet
- What Is Reinforcement LearningDocument12 pagesWhat Is Reinforcement LearningranamzeeshanNo ratings yet
- PomdpsDocument76 pagesPomdpsHimanshu SrivastavaNo ratings yet
- Accuracy Interpretability TradeoffDocument24 pagesAccuracy Interpretability TradeoffbanstalaNo ratings yet