
Decision Trees
Decision Trees
You might also like
- Encyclopedia of Research Design, 3 Volumes (2010) by Neil J. Salkind PDFDocument1,644 pagesEncyclopedia of Research Design, 3 Volumes (2010) by Neil J. Salkind PDFSidney GM85% (34)
- Electromagnetic Waves and Radiating Systems by E.C. Jordan and K.G. Balmain, 2nd Edition, Prentice Hall, 1968Document763 pagesElectromagnetic Waves and Radiating Systems by E.C. Jordan and K.G. Balmain, 2nd Edition, Prentice Hall, 1968Levi HackermanNo ratings yet
- CSC 472Document151 pagesCSC 472Han LinNo ratings yet
- 4 Frontal DisplacementDocument89 pages4 Frontal DisplacementHemant SrivastavaNo ratings yet
- Data Science Interview Preparation (30 Days of Interview Preparation)Document22 pagesData Science Interview Preparation (30 Days of Interview Preparation)Satyavaraprasad BallaNo ratings yet
- Decision TreesDocument11 pagesDecision TreesDerek DegbedzuiNo ratings yet
- Lec 5Document25 pagesLec 5Lyu PhilipNo ratings yet
- Decision-Tree Learning .Document29 pagesDecision-Tree Learning .avinash kumarNo ratings yet
- Decision Tree LearningDocument70 pagesDecision Tree Learningchauhansumi143No ratings yet
- Summary PDFDocument8 pagesSummary PDFNadia ZoubirNo ratings yet
- Korting 2007 C 45Document5 pagesKorting 2007 C 45Ana NabilaNo ratings yet
- ClassificationDocument30 pagesClassificationmostafasameer858No ratings yet
- 21 Decision TreesDocument62 pages21 Decision Treesdamasodra33No ratings yet
- Decision Tree RepresentationDocument2 pagesDecision Tree RepresentationMANAS DUTTANo ratings yet
- Decision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangDocument25 pagesDecision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangJohnnyNo ratings yet
- M01 Tree-Based MethodsDocument38 pagesM01 Tree-Based Methodsanjibalaji52No ratings yet
- Decision Tree Algorithm: and Classification Problems TooDocument12 pagesDecision Tree Algorithm: and Classification Problems TooAva WhiteNo ratings yet
- CRCF BrainstormDocument20 pagesCRCF BrainstormDavid BriggsNo ratings yet
- Decision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangDocument25 pagesDecision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangSNo ratings yet
- Machine Learning: Chapter 3. Decision Tree LearningDocument29 pagesMachine Learning: Chapter 3. Decision Tree LearningPanku RangareeNo ratings yet
- Decision TreesDocument15 pagesDecision TreesAlwan Fauzan NurjamilNo ratings yet
- Decision Tree Classification Algorithm: Why Use Decision Trees?Document15 pagesDecision Tree Classification Algorithm: Why Use Decision Trees?shreya sarkarNo ratings yet
- Module 3 DecisionTree NotesDocument14 pagesModule 3 DecisionTree NotesManas HassijaNo ratings yet
- Decision TreeDocument13 pagesDecision TreeratnamsNo ratings yet
- TreeDocument7 pagesTreeSailla Raghu rajNo ratings yet
- Decision Trees and Random Forest Q&aDocument48 pagesDecision Trees and Random Forest Q&aVishnuNo ratings yet
- Screenshot 2024-02-06 at 1.43.15 PMDocument66 pagesScreenshot 2024-02-06 at 1.43.15 PM1NC21IS062 Vishal H CNo ratings yet
- CZ4032 Data Analytics & Mining NotesDocument16 pagesCZ4032 Data Analytics & Mining NotesFeng ChengxuanNo ratings yet
- 1.decision Trees ConceptsDocument70 pages1.decision Trees ConceptsSuyash JainNo ratings yet
- Module - 3 - DTL & AnnDocument10 pagesModule - 3 - DTL & AnnsuryakiranaNo ratings yet
- Class 16 Decision TreeDocument45 pagesClass 16 Decision TreeSumana BasuNo ratings yet
- Decision TreesDocument14 pagesDecision TreesJosiah MuchiraNo ratings yet
- Decision TreesDocument24 pagesDecision Treesprabhakaran sridharanNo ratings yet
- MID 2 PresentationDocument40 pagesMID 2 PresentationQuratulain TariqNo ratings yet
- Machine Learning Lab: Delhi Technological UniversityDocument6 pagesMachine Learning Lab: Delhi Technological UniversityHimanshu SinghNo ratings yet
- Chapter 4classification and PredictionDocument19 pagesChapter 4classification and PredictionsrjaswarNo ratings yet
- ML Unit 3 NotesDocument117 pagesML Unit 3 Notescabhi7789No ratings yet
- ML UNIT-2 NotesDocument15 pagesML UNIT-2 NotesAnil KrishnaNo ratings yet
- Unit 2Document11 pagesUnit 2hollowpurple156No ratings yet
- Decision TreeDocument5 pagesDecision Treeprakash.omprakash.om1No ratings yet
- 10 2Document10 pages10 2uxamaNo ratings yet
- Decision TreeDocument68 pagesDecision Tree2K20CO345 Priti MeenaNo ratings yet
- Decision TreeDocument25 pagesDecision Treericardo_g1973No ratings yet
- ML Unit 3Document14 pagesML Unit 3aiswaryaNo ratings yet
- Fuzzy Decision TreesDocument12 pagesFuzzy Decision TreesVu Trung NguyenNo ratings yet
- Decision Trees and How To Build and Optimize Decision Tree ClassifierDocument16 pagesDecision Trees and How To Build and Optimize Decision Tree ClassifierShalini SinghalNo ratings yet
- Decision and Regression Tree LearningDocument51 pagesDecision and Regression Tree LearningMOOKAMBIGA A100% (1)
- Malacad Activity3Document8 pagesMalacad Activity3Regine MalacadNo ratings yet
- Unit2 MLDocument19 pagesUnit2 MLyashksharma181202No ratings yet
- Cluster Lecture 2Document14 pagesCluster Lecture 2Dardo CurtiNo ratings yet
- Decision TreesDocument14 pagesDecision TreesJustin Russo Harry50% (2)
- DWDM Asgmnt ProgDocument51 pagesDWDM Asgmnt Progcopy leaksNo ratings yet
- Module 3Document102 pagesModule 3Vaibhav SinglaNo ratings yet
- Experiment No 04: Theory: Decision Tree: Decision Tree Is The Most Powerful and Popular Tool ForDocument7 pagesExperiment No 04: Theory: Decision Tree: Decision Tree Is The Most Powerful and Popular Tool ForMIHIR PATELNo ratings yet
- Unit 2 1Document15 pagesUnit 2 1moviedownloadasNo ratings yet
- AIML Module4Document59 pagesAIML Module4lavanyalkaroshiNo ratings yet
- 09 Decision Trees Nearest NeighborDocument8 pages09 Decision Trees Nearest NeighborYiwei ChenNo ratings yet
- Decisiontree 2Document16 pagesDecisiontree 2shilpaNo ratings yet
- ML Decode TE ITDocument71 pagesML Decode TE ITomsonawane15203No ratings yet
- Trinh Khanh Ly 20213676Document13 pagesTrinh Khanh Ly 20213676Khánh Ly TrịnhNo ratings yet
- Day 3Document32 pagesDay 3Dishant GuptaNo ratings yet
- UNIT3Document71 pagesUNIT3TomNo ratings yet
- Lecture #15: Regression Trees & Random ForestsDocument34 pagesLecture #15: Regression Trees & Random ForestsAsh KPJNo ratings yet
- TricycleDocument10 pagesTricyclechancer01No ratings yet
- Calculating Slack Time and Identifying The Critical PathDocument3 pagesCalculating Slack Time and Identifying The Critical PathkharismaNo ratings yet
- Chapters 3 and 4: Complete Solution Graphical SolutionDocument26 pagesChapters 3 and 4: Complete Solution Graphical SolutionLauren StevensonNo ratings yet
- Assignment SolutionsDocument4 pagesAssignment SolutionsshruthinNo ratings yet
- Chapter 7 - Torsion - Civil PDFDocument50 pagesChapter 7 - Torsion - Civil PDFcoded coderNo ratings yet
- Dr. Carlos S. Lanting College: Basic Education - Senior High SchoolDocument8 pagesDr. Carlos S. Lanting College: Basic Education - Senior High SchoolJohn Peter ElloricoNo ratings yet
- Appendix ThreeDocument2 pagesAppendix ThreeTom DavisNo ratings yet
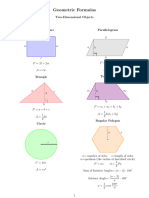
- Math Resources Geometry FormulasDocument2 pagesMath Resources Geometry FormulasMoslem GrimaldiNo ratings yet
- Driver Alert System Based On Eye RecognitionDocument20 pagesDriver Alert System Based On Eye Recognitionhostel boysNo ratings yet
- PDC BixioRimoldiDocument311 pagesPDC BixioRimoldiFrank211No ratings yet
- m2 Rev3t - Swokowski - PDFDocument3 pagesm2 Rev3t - Swokowski - PDFSkyezine Via Kit FoxNo ratings yet
- H.C.F. & L.C.M (Amcat)Document6 pagesH.C.F. & L.C.M (Amcat)GauravNo ratings yet
- G2 - Rules of ThumbDocument80 pagesG2 - Rules of ThumbEliel De Souza100% (4)
- XII Maths DPP (29) - Prev ChapsDocument16 pagesXII Maths DPP (29) - Prev ChapsAshish RanjanNo ratings yet
- SSC 418Document150 pagesSSC 418Lenin ValerioNo ratings yet
- The MV3R-Tree: A Spatio-Temporal Access Method For Timestamp and Interval QueriesDocument33 pagesThe MV3R-Tree: A Spatio-Temporal Access Method For Timestamp and Interval QueriesJericko TejidoNo ratings yet
- Deflection of Symmetric Beams: Chapter SevenDocument49 pagesDeflection of Symmetric Beams: Chapter SevenrenebbNo ratings yet
- Phys Lect Eng LSSBT 1Document11 pagesPhys Lect Eng LSSBT 1api-239131622No ratings yet
- G 8 - 3rd PretestDocument4 pagesG 8 - 3rd PretestHero-name-mo?No ratings yet
- Notes M1 MPG Unit 1Document21 pagesNotes M1 MPG Unit 1aishaNo ratings yet
- BCSL-044 - Statistical Techniques (Lab) PDFDocument25 pagesBCSL-044 - Statistical Techniques (Lab) PDFArjun Sharad100% (1)
- Lecture-2 PropPred MergedDocument35 pagesLecture-2 PropPred MergedAleezay AmirNo ratings yet
- Previous University Question PaperDocument3 pagesPrevious University Question Papersafu_117No ratings yet
- System of Fits and TolerancesDocument41 pagesSystem of Fits and TolerancesAnkit MittalNo ratings yet
- Nwmo TR 2015 06Document85 pagesNwmo TR 2015 06CoraNo ratings yet
- Lear Jonathan Aristotelian InfinityDocument25 pagesLear Jonathan Aristotelian Infinityαλεξάνδρα σούσουNo ratings yet

























































































Download as pdf or txt
You might also like
- Encyclopedia of Research Design, 3 Volumes (2010) by Neil J. Salkind PDFDocument1,644 pagesEncyclopedia of Research Design, 3 Volumes (2010) by Neil J. Salkind PDFSidney GM85% (34)
- Electromagnetic Waves and Radiating Systems by E.C. Jordan and K.G. Balmain, 2nd Edition, Prentice Hall, 1968Document763 pagesElectromagnetic Waves and Radiating Systems by E.C. Jordan and K.G. Balmain, 2nd Edition, Prentice Hall, 1968Levi HackermanNo ratings yet
- CSC 472Document151 pagesCSC 472Han LinNo ratings yet
- 4 Frontal DisplacementDocument89 pages4 Frontal DisplacementHemant SrivastavaNo ratings yet
- Data Science Interview Preparation (30 Days of Interview Preparation)Document22 pagesData Science Interview Preparation (30 Days of Interview Preparation)Satyavaraprasad BallaNo ratings yet
- Decision TreesDocument11 pagesDecision TreesDerek DegbedzuiNo ratings yet
- Lec 5Document25 pagesLec 5Lyu PhilipNo ratings yet
- Decision-Tree Learning .Document29 pagesDecision-Tree Learning .avinash kumarNo ratings yet
- Decision Tree LearningDocument70 pagesDecision Tree Learningchauhansumi143No ratings yet
- Summary PDFDocument8 pagesSummary PDFNadia ZoubirNo ratings yet
- Korting 2007 C 45Document5 pagesKorting 2007 C 45Ana NabilaNo ratings yet
- ClassificationDocument30 pagesClassificationmostafasameer858No ratings yet
- 21 Decision TreesDocument62 pages21 Decision Treesdamasodra33No ratings yet
- Decision Tree RepresentationDocument2 pagesDecision Tree RepresentationMANAS DUTTANo ratings yet
- Decision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangDocument25 pagesDecision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangJohnnyNo ratings yet
- M01 Tree-Based MethodsDocument38 pagesM01 Tree-Based Methodsanjibalaji52No ratings yet
- Decision Tree Algorithm: and Classification Problems TooDocument12 pagesDecision Tree Algorithm: and Classification Problems TooAva WhiteNo ratings yet
- CRCF BrainstormDocument20 pagesCRCF BrainstormDavid BriggsNo ratings yet
- Decision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangDocument25 pagesDecision Tree Algorithm: Comp328 Tutorial 1 Kai ZhangSNo ratings yet
- Machine Learning: Chapter 3. Decision Tree LearningDocument29 pagesMachine Learning: Chapter 3. Decision Tree LearningPanku RangareeNo ratings yet
- Decision TreesDocument15 pagesDecision TreesAlwan Fauzan NurjamilNo ratings yet
- Decision Tree Classification Algorithm: Why Use Decision Trees?Document15 pagesDecision Tree Classification Algorithm: Why Use Decision Trees?shreya sarkarNo ratings yet
- Module 3 DecisionTree NotesDocument14 pagesModule 3 DecisionTree NotesManas HassijaNo ratings yet
- Decision TreeDocument13 pagesDecision TreeratnamsNo ratings yet
- TreeDocument7 pagesTreeSailla Raghu rajNo ratings yet
- Decision Trees and Random Forest Q&aDocument48 pagesDecision Trees and Random Forest Q&aVishnuNo ratings yet
- Screenshot 2024-02-06 at 1.43.15 PMDocument66 pagesScreenshot 2024-02-06 at 1.43.15 PM1NC21IS062 Vishal H CNo ratings yet
- CZ4032 Data Analytics & Mining NotesDocument16 pagesCZ4032 Data Analytics & Mining NotesFeng ChengxuanNo ratings yet
- 1.decision Trees ConceptsDocument70 pages1.decision Trees ConceptsSuyash JainNo ratings yet
- Module - 3 - DTL & AnnDocument10 pagesModule - 3 - DTL & AnnsuryakiranaNo ratings yet
- Class 16 Decision TreeDocument45 pagesClass 16 Decision TreeSumana BasuNo ratings yet
- Decision TreesDocument14 pagesDecision TreesJosiah MuchiraNo ratings yet
- Decision TreesDocument24 pagesDecision Treesprabhakaran sridharanNo ratings yet
- MID 2 PresentationDocument40 pagesMID 2 PresentationQuratulain TariqNo ratings yet
- Machine Learning Lab: Delhi Technological UniversityDocument6 pagesMachine Learning Lab: Delhi Technological UniversityHimanshu SinghNo ratings yet
- Chapter 4classification and PredictionDocument19 pagesChapter 4classification and PredictionsrjaswarNo ratings yet
- ML Unit 3 NotesDocument117 pagesML Unit 3 Notescabhi7789No ratings yet
- ML UNIT-2 NotesDocument15 pagesML UNIT-2 NotesAnil KrishnaNo ratings yet
- Unit 2Document11 pagesUnit 2hollowpurple156No ratings yet
- Decision TreeDocument5 pagesDecision Treeprakash.omprakash.om1No ratings yet
- 10 2Document10 pages10 2uxamaNo ratings yet
- Decision TreeDocument68 pagesDecision Tree2K20CO345 Priti MeenaNo ratings yet
- Decision TreeDocument25 pagesDecision Treericardo_g1973No ratings yet
- ML Unit 3Document14 pagesML Unit 3aiswaryaNo ratings yet
- Fuzzy Decision TreesDocument12 pagesFuzzy Decision TreesVu Trung NguyenNo ratings yet
- Decision Trees and How To Build and Optimize Decision Tree ClassifierDocument16 pagesDecision Trees and How To Build and Optimize Decision Tree ClassifierShalini SinghalNo ratings yet
- Decision and Regression Tree LearningDocument51 pagesDecision and Regression Tree LearningMOOKAMBIGA A100% (1)
- Malacad Activity3Document8 pagesMalacad Activity3Regine MalacadNo ratings yet
- Unit2 MLDocument19 pagesUnit2 MLyashksharma181202No ratings yet
- Cluster Lecture 2Document14 pagesCluster Lecture 2Dardo CurtiNo ratings yet
- Decision TreesDocument14 pagesDecision TreesJustin Russo Harry50% (2)
- DWDM Asgmnt ProgDocument51 pagesDWDM Asgmnt Progcopy leaksNo ratings yet
- Module 3Document102 pagesModule 3Vaibhav SinglaNo ratings yet
- Experiment No 04: Theory: Decision Tree: Decision Tree Is The Most Powerful and Popular Tool ForDocument7 pagesExperiment No 04: Theory: Decision Tree: Decision Tree Is The Most Powerful and Popular Tool ForMIHIR PATELNo ratings yet
- Unit 2 1Document15 pagesUnit 2 1moviedownloadasNo ratings yet
- AIML Module4Document59 pagesAIML Module4lavanyalkaroshiNo ratings yet
- 09 Decision Trees Nearest NeighborDocument8 pages09 Decision Trees Nearest NeighborYiwei ChenNo ratings yet
- Decisiontree 2Document16 pagesDecisiontree 2shilpaNo ratings yet
- ML Decode TE ITDocument71 pagesML Decode TE ITomsonawane15203No ratings yet
- Trinh Khanh Ly 20213676Document13 pagesTrinh Khanh Ly 20213676Khánh Ly TrịnhNo ratings yet
- Day 3Document32 pagesDay 3Dishant GuptaNo ratings yet
- UNIT3Document71 pagesUNIT3TomNo ratings yet
- Lecture #15: Regression Trees & Random ForestsDocument34 pagesLecture #15: Regression Trees & Random ForestsAsh KPJNo ratings yet
- TricycleDocument10 pagesTricyclechancer01No ratings yet
- Calculating Slack Time and Identifying The Critical PathDocument3 pagesCalculating Slack Time and Identifying The Critical PathkharismaNo ratings yet
- Chapters 3 and 4: Complete Solution Graphical SolutionDocument26 pagesChapters 3 and 4: Complete Solution Graphical SolutionLauren StevensonNo ratings yet
- Assignment SolutionsDocument4 pagesAssignment SolutionsshruthinNo ratings yet
- Chapter 7 - Torsion - Civil PDFDocument50 pagesChapter 7 - Torsion - Civil PDFcoded coderNo ratings yet
- Dr. Carlos S. Lanting College: Basic Education - Senior High SchoolDocument8 pagesDr. Carlos S. Lanting College: Basic Education - Senior High SchoolJohn Peter ElloricoNo ratings yet
- Appendix ThreeDocument2 pagesAppendix ThreeTom DavisNo ratings yet
- Math Resources Geometry FormulasDocument2 pagesMath Resources Geometry FormulasMoslem GrimaldiNo ratings yet
- Driver Alert System Based On Eye RecognitionDocument20 pagesDriver Alert System Based On Eye Recognitionhostel boysNo ratings yet
- PDC BixioRimoldiDocument311 pagesPDC BixioRimoldiFrank211No ratings yet
- m2 Rev3t - Swokowski - PDFDocument3 pagesm2 Rev3t - Swokowski - PDFSkyezine Via Kit FoxNo ratings yet
- H.C.F. & L.C.M (Amcat)Document6 pagesH.C.F. & L.C.M (Amcat)GauravNo ratings yet
- G2 - Rules of ThumbDocument80 pagesG2 - Rules of ThumbEliel De Souza100% (4)
- XII Maths DPP (29) - Prev ChapsDocument16 pagesXII Maths DPP (29) - Prev ChapsAshish RanjanNo ratings yet
- SSC 418Document150 pagesSSC 418Lenin ValerioNo ratings yet
- The MV3R-Tree: A Spatio-Temporal Access Method For Timestamp and Interval QueriesDocument33 pagesThe MV3R-Tree: A Spatio-Temporal Access Method For Timestamp and Interval QueriesJericko TejidoNo ratings yet
- Deflection of Symmetric Beams: Chapter SevenDocument49 pagesDeflection of Symmetric Beams: Chapter SevenrenebbNo ratings yet
- Phys Lect Eng LSSBT 1Document11 pagesPhys Lect Eng LSSBT 1api-239131622No ratings yet
- G 8 - 3rd PretestDocument4 pagesG 8 - 3rd PretestHero-name-mo?No ratings yet
- Notes M1 MPG Unit 1Document21 pagesNotes M1 MPG Unit 1aishaNo ratings yet
- BCSL-044 - Statistical Techniques (Lab) PDFDocument25 pagesBCSL-044 - Statistical Techniques (Lab) PDFArjun Sharad100% (1)
- Lecture-2 PropPred MergedDocument35 pagesLecture-2 PropPred MergedAleezay AmirNo ratings yet
- Previous University Question PaperDocument3 pagesPrevious University Question Papersafu_117No ratings yet
- System of Fits and TolerancesDocument41 pagesSystem of Fits and TolerancesAnkit MittalNo ratings yet
- Nwmo TR 2015 06Document85 pagesNwmo TR 2015 06CoraNo ratings yet
- Lear Jonathan Aristotelian InfinityDocument25 pagesLear Jonathan Aristotelian Infinityαλεξάνδρα σούσουNo ratings yet