Download as pdf or txt
You might also like
- Pencil Me in - 1hn PDFDocument25 pagesPencil Me in - 1hn PDFMaryam Shamkhali100% (3)
- Drafting Men's Pants PatternDocument4 pagesDrafting Men's Pants Patterndanut_doc64% (11)
- General Physics Worksheet - Chapter 1 - (Phys1011)Document2 pagesGeneral Physics Worksheet - Chapter 1 - (Phys1011)melaku zegeye100% (1)
- Exercise 1: Geostatistics: + ) H) K (X K (X) (2N 1 (H)Document8 pagesExercise 1: Geostatistics: + ) H) K (X K (X) (2N 1 (H)vegaron0% (1)
- Lectures 9 and 10: Chapter 7: Linkage, Recombination, and Eukaryotic Gene Mapping, Parts 1 and 2Document8 pagesLectures 9 and 10: Chapter 7: Linkage, Recombination, and Eukaryotic Gene Mapping, Parts 1 and 2Mohammad MohsinNo ratings yet
- Curve fitting-I-IIDocument12 pagesCurve fitting-I-IIRajan SinghNo ratings yet
- Volker BlobelDocument27 pagesVolker Blobelfetiviw298No ratings yet
- The Analysis of 2 2 Factorial Fracture Experiments With Brittle MaterialsDocument8 pagesThe Analysis of 2 2 Factorial Fracture Experiments With Brittle Materialsapi-3733260No ratings yet
- Jobson 1980Document12 pagesJobson 1980pharssNo ratings yet
- Parallel Lines - CWDocument16 pagesParallel Lines - CWHimanshu JethwaniNo ratings yet
- 1 s2.0 S0378375821000033 MainDocument13 pages1 s2.0 S0378375821000033 MainJackson MwaiNo ratings yet
- Elitist Recombination An Integrated Selection Recombination GaDocument5 pagesElitist Recombination An Integrated Selection Recombination GaDivya ShahNo ratings yet
- Maths Grade 12 JIT 2022Document109 pagesMaths Grade 12 JIT 2022Wilfried BarrosNo ratings yet
- GROUP 2 Exercise 2 Gene Segregation and Interaction PDFDocument9 pagesGROUP 2 Exercise 2 Gene Segregation and Interaction PDFMary Joy Annika MagtibayNo ratings yet
- Lect 09Document8 pagesLect 09AdarshNo ratings yet
- Q Stat 4Document11 pagesQ Stat 4tihato8838No ratings yet
- Anyons and Fractional Quantum Hall EffectDocument17 pagesAnyons and Fractional Quantum Hall EffectANISH ACHARYANo ratings yet
- The Optimality of Naive Bayes: Harry ZhangDocument6 pagesThe Optimality of Naive Bayes: Harry Zhang1111566No ratings yet
- Negative PDFDocument4 pagesNegative PDFd-fbuser-25035882No ratings yet
- 03 Descriptive Statistics Part 3 - Mixed LogitDocument17 pages03 Descriptive Statistics Part 3 - Mixed LogitBrhane YgzawNo ratings yet
- The Noncommutative Minimal Model Program. Daniel Halpern-LeistnerDocument30 pagesThe Noncommutative Minimal Model Program. Daniel Halpern-LeistnerZulianiNo ratings yet
- Effective Codescent Morphisms of N-Quasigroups and N-Loops: March 2024Document12 pagesEffective Codescent Morphisms of N-Quasigroups and N-Loops: March 2024andromosdzNo ratings yet
- Optimal local law and central limit theorem for β-ensemblesDocument45 pagesOptimal local law and central limit theorem for β-ensemblesbeemanNo ratings yet
- Chi Square TestDocument2 pagesChi Square TestErwin BulahaoNo ratings yet
- Indefinite Integration - CC - EngDocument48 pagesIndefinite Integration - CC - EngShaileshNamdeoNo ratings yet
- ICTMA2020 AD4SM PosterDocument1 pageICTMA2020 AD4SM Posterticonzero2010No ratings yet
- Q4 W6 WGStatDocument3 pagesQ4 W6 WGStatAndrea KateNo ratings yet
- The Estimation of The Genetic Correlation: TheDocument5 pagesThe Estimation of The Genetic Correlation: Thewilsonlazo_656691303No ratings yet
- Arma2015 000311 PDFDocument6 pagesArma2015 000311 PDFyagebu88No ratings yet
- Alternating Randomized Block Coordinate Descent: Strohmer & Vershynin 2009 Nesterov 2012Document13 pagesAlternating Randomized Block Coordinate Descent: Strohmer & Vershynin 2009 Nesterov 2012BinduMishraNo ratings yet
- Module 4Document36 pagesModule 4MD SHAHRIARMAHMUDNo ratings yet
- 55 Befl05 55Document11 pages55 Befl05 55SaherNo ratings yet
- BenaichDocument27 pagesBenaichhamidfNo ratings yet
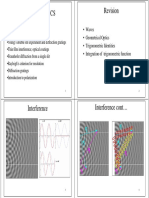
- Physical OpticsDocument15 pagesPhysical OpticssaneleNo ratings yet
- Similarity Solutions For Partial Differential Equations Generated by Finite and Infinitesimal GroupsDocument100 pagesSimilarity Solutions For Partial Differential Equations Generated by Finite and Infinitesimal GroupsRodrigo PaivaNo ratings yet
- Notes 2016 FRM Quick SheetDocument6 pagesNotes 2016 FRM Quick SheetJoannaNo ratings yet
- 1Document1 page1Amir mohamad MostajeranNo ratings yet
- Equivalent Capacitances For Microstrip Gaps and Steps: Peter Benedek P. SilvesterDocument5 pagesEquivalent Capacitances For Microstrip Gaps and Steps: Peter Benedek P. SilvesterElectronic BoyNo ratings yet
- A Compilation of Mathematical DemonstrationsDocument385 pagesA Compilation of Mathematical DemonstrationsFrank Waabu O'Brien (Dr. Francis J. O'Brien Jr.)100% (1)
- Geometric Sequences: Essential UnderstandingDocument5 pagesGeometric Sequences: Essential UnderstandingGlenda HernandezNo ratings yet
- A Bayesian Perspective On Estimating Mean, Variance, and Standard-Deviation From DataDocument18 pagesA Bayesian Perspective On Estimating Mean, Variance, and Standard-Deviation From DatatrbenjaminNo ratings yet
- NE Actor Xperiments: G= largest s s H α− g>gDocument2 pagesNE Actor Xperiments: G= largest s s H α− g>gErwin BulahaoNo ratings yet
- OTM Correlation Regression Dec 23Document8 pagesOTM Correlation Regression Dec 23Abhijeet SinghNo ratings yet
- PhysRevLett 129 222001Document6 pagesPhysRevLett 129 222001Hongsun KimNo ratings yet
- Theoretical Distributions 1Document2 pagesTheoretical Distributions 1bnanduriNo ratings yet
- 1 2 N N +1 R N N 1Document17 pages1 2 N N +1 R N N 1Renato CastilhoNo ratings yet
- New Fractional Derivative With Non-Singular Kernel For Deriving Legendre Spectral Collocation MethodDocument9 pagesNew Fractional Derivative With Non-Singular Kernel For Deriving Legendre Spectral Collocation MethodHidden ModeNo ratings yet
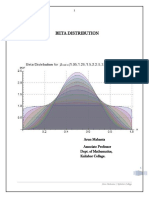
- Mathematical Excursion To Beta Distribution PDFDocument20 pagesMathematical Excursion To Beta Distribution PDFsekarganesanNo ratings yet
- Non-Equilibrium Steady State Response and Fluctuations of Sheared Nematic Liquid CrystalsDocument6 pagesNon-Equilibrium Steady State Response and Fluctuations of Sheared Nematic Liquid CrystalsSurajit DharaNo ratings yet
- Numerical Integration Stiffness Irons 66Document3 pagesNumerical Integration Stiffness Irons 66Felipe GarciaNo ratings yet
- Class 2 SPDocument30 pagesClass 2 SPAbel GulilatNo ratings yet
- Weekly Wages in Rs. No. of Persons Weekly Wages in Rs. No of PersonsDocument15 pagesWeekly Wages in Rs. No. of Persons Weekly Wages in Rs. No of PersonsDarshit PatelNo ratings yet
- ThaodinhDocument20 pagesThaodinhhuanxianlouNo ratings yet
- Micro Lesson PlanDocument2 pagesMicro Lesson Plan21-390Virkula Manish goud GNITC LEMECHNo ratings yet
- CKM Matrix - CERNDocument4 pagesCKM Matrix - CERNNachiket Jhala (RA1911019010065)No ratings yet
- Rosenzweig 1991 0004Document3 pagesRosenzweig 1991 0004Particle Beam Physics LabNo ratings yet
- Differential Equation 2Document6 pagesDifferential Equation 2Cinderella WhiteNo ratings yet
- 3 SimpleLinearRegressionDocument30 pages3 SimpleLinearRegression2022CEP006 AYANKUMAR NASKARNo ratings yet
- Elicit Pre-Assessment Test Connect Us!Document6 pagesElicit Pre-Assessment Test Connect Us!Jeazel MosendoNo ratings yet
- Journal of Inequalities in Pure and Applied Mathematics: Bounds For Linear Recurrences With Restricted CoefficientsDocument15 pagesJournal of Inequalities in Pure and Applied Mathematics: Bounds For Linear Recurrences With Restricted CoefficientsSaherNo ratings yet
- Lecture 3 - Linkage DisequlibriumDocument2 pagesLecture 3 - Linkage DisequlibriumLance CarandangNo ratings yet
- I2ml3e Chap5Document26 pagesI2ml3e Chap5EMS Metalworking MachineryNo ratings yet
- Discrete Orthogonal Polynomials. (AM-164): Asymptotics and Applications (AM-164)From EverandDiscrete Orthogonal Polynomials. (AM-164): Asymptotics and Applications (AM-164)No ratings yet
- SpikingsDocument38 pagesSpikingspradeep kumarNo ratings yet
- LncRNA-disease Association Prediction Method Based On Heterogeneous Information Completion and Convolutional Neural NetworkDocument9 pagesLncRNA-disease Association Prediction Method Based On Heterogeneous Information Completion and Convolutional Neural Networkpradeep kumarNo ratings yet
- Mathematical Methods For Assessing The Accuracy of Pre-Planned and Guided Surgical OsteotomiesDocument13 pagesMathematical Methods For Assessing The Accuracy of Pre-Planned and Guided Surgical Osteotomiespradeep kumarNo ratings yet
- Neural Representations of Dynamic Visual StimuliDocument24 pagesNeural Representations of Dynamic Visual Stimulipradeep kumarNo ratings yet
- How Cells Stay Together A Mechanism For Maintenance of A Robust Cluster Explored by Local and Nonlocal Continuum ModelsDocument20 pagesHow Cells Stay Together A Mechanism For Maintenance of A Robust Cluster Explored by Local and Nonlocal Continuum Modelspradeep kumarNo ratings yet
- Vagus Nerve Stimulation - Laying The Groundwork For Predictive Network-Based Computer ModelsDocument33 pagesVagus Nerve Stimulation - Laying The Groundwork For Predictive Network-Based Computer Modelspradeep kumarNo ratings yet
- Recurrent Neural Chemical Reaction Networks That Approximate Arbitrary DynamicsDocument20 pagesRecurrent Neural Chemical Reaction Networks That Approximate Arbitrary Dynamicspradeep kumarNo ratings yet
- Mapping Dynamical Systems Into Chemical ReactionsDocument30 pagesMapping Dynamical Systems Into Chemical Reactionspradeep kumarNo ratings yet
- Mitigate Position Bias in Large Language Models Via Scaling A Single DimensionDocument20 pagesMitigate Position Bias in Large Language Models Via Scaling A Single Dimensionpradeep kumarNo ratings yet
- AutoGen: Enabling Next-Gen LLM Applications Via Multi-Agent ConversationDocument43 pagesAutoGen: Enabling Next-Gen LLM Applications Via Multi-Agent Conversationpradeep kumarNo ratings yet
- Galois in MatLab GuideDocument30 pagesGalois in MatLab Guidelitter_trashNo ratings yet
- 2006 AJC H2 MY SolnDocument9 pages2006 AJC H2 MY Solnjunie9201No ratings yet
- Parallel DimensionsDocument17 pagesParallel Dimensionsnikoleta_tmmNo ratings yet
- Guia Formacion SASDocument16 pagesGuia Formacion SASwespinoaNo ratings yet
- Sol PDFDocument312 pagesSol PDFRupakNo ratings yet
- Fabric DetectionDocument18 pagesFabric DetectionAnitha KarunakaranNo ratings yet
- Sequence and SeriesDocument22 pagesSequence and SeriesMUQDOOM AliNo ratings yet
- How To Create A Geometric, WPAP Vector Portrait in Adobe IllustratorDocument16 pagesHow To Create A Geometric, WPAP Vector Portrait in Adobe IllustratorGabriel SetyohandokoNo ratings yet
- Q4 Mathematics 6 Module 7Document20 pagesQ4 Mathematics 6 Module 7Giyu TomiokaNo ratings yet
- Regression AnalysisDocument6 pagesRegression AnalysisDonabell RapiNo ratings yet
- Chapter 6 (Integration Techniques) : DX X XDocument27 pagesChapter 6 (Integration Techniques) : DX X XAfiqah ZainuddinNo ratings yet
- Deld Practical Course PlanDocument8 pagesDeld Practical Course PlanSampada ThoratNo ratings yet
- Manual For Master Researchpproposal - ThesisDocument54 pagesManual For Master Researchpproposal - ThesisTewfic Seid100% (3)
- Ratios and Proportions QuestionsDocument2 pagesRatios and Proportions QuestionsRavi Shankar0% (1)
- Analysis of CostsDocument26 pagesAnalysis of CostsTanvi ThakurNo ratings yet
- Exercises - PrologDocument6 pagesExercises - PrologMj EbrahimNo ratings yet
- Tutorial 6Document2 pagesTutorial 6uniqueNo ratings yet
- Analysis of Repeated Measures and Time SeriesDocument90 pagesAnalysis of Repeated Measures and Time Series2874970No ratings yet
- 09 PDFDocument12 pages09 PDFAlifudin KhumaidiNo ratings yet
- ML Lecture 1 Introduction and PoliciesDocument45 pagesML Lecture 1 Introduction and PoliciesFaizad UllahNo ratings yet
- Illumination Technology Module 3Document45 pagesIllumination Technology Module 3Viki PrasadNo ratings yet
- Friction MCQ Practice Sheet Part 1Document7 pagesFriction MCQ Practice Sheet Part 1eka123100% (1)
- Chapter 4 PDFDocument24 pagesChapter 4 PDFirusha100% (1)
- Chap 005Document153 pagesChap 005Kim NgânNo ratings yet