Download as docx, pdf, or txt
You might also like
- Prediction of Future Ski Jacket Demand Using SimulationDocument8 pagesPrediction of Future Ski Jacket Demand Using SimulationAcimSultanNo ratings yet
- Unit 14 - Assignment 1 FrontsheetDocument26 pagesUnit 14 - Assignment 1 FrontsheetPhúc TrầnNo ratings yet
- MachineLearningNotes PDFDocument299 pagesMachineLearningNotes PDFKarthik selvamNo ratings yet
- Speed of Light MeasurementDocument2 pagesSpeed of Light MeasurementbrettNo ratings yet
- Statistic Asm2 VuHaMinhTuan BH00890Document27 pagesStatistic Asm2 VuHaMinhTuan BH00890Linh ĐồngNo ratings yet
- Asm1 Statistics DongThiLinh BH01210Document31 pagesAsm1 Statistics DongThiLinh BH01210Linh ĐồngNo ratings yet
- Asm1 Statistics LeThiThuy EV SNDSDocument38 pagesAsm1 Statistics LeThiThuy EV SNDSLinh ĐồngNo ratings yet
- ASM2 - Distinction - NGUYEN VAN SANG - 570Document63 pagesASM2 - Distinction - NGUYEN VAN SANG - 570tha thaNo ratings yet
- HaTranDoanThuc 574 ASM2 GBD0905Document27 pagesHaTranDoanThuc 574 ASM2 GBD0905Ha Tran Doan Thuc (FGW DN)No ratings yet
- Asm2 5060fullDocument14 pagesAsm2 5060fullchientdgbh211398No ratings yet
- Assignment 570 Final - NTĐDocument21 pagesAssignment 570 Final - NTĐvietnhgch210878No ratings yet
- ASM2 ThamkhaoDocument24 pagesASM2 ThamkhaoNguyen Huu Thang (FGW DN)No ratings yet
- 5060 Asm2Document29 pages5060 Asm2gianglhgbh211236No ratings yet
- 1 - Assignment 01 570Document22 pages1 - Assignment 01 570Hải ĐoànnnNo ratings yet
- Assignment 01 Front Sheet: Unit Number and Title Unit 31: Statistics For ManagementDocument21 pagesAssignment 01 Front Sheet: Unit Number and Title Unit 31: Statistics For ManagementPham Nguyen Anh (FGW HCM)No ratings yet
- 570.assignment-1-Frontsheet ASM1Document16 pages570.assignment-1-Frontsheet ASM1Tran Thi Ngoc Tam (BTEC HN)No ratings yet
- Ngo Hai Trang - 570 ASS2Document29 pagesNgo Hai Trang - 570 ASS2Ngo Hai Trang (FGW HCM)No ratings yet
- Asm1 Bi Group3Document30 pagesAsm1 Bi Group3Ngo Thi Khanh Chi BTEC HNNo ratings yet
- Assignment Front Sheet: Qualification BTEC Level 4 HND Diploma in BusinessDocument26 pagesAssignment Front Sheet: Qualification BTEC Level 4 HND Diploma in BusinessTruong Thi Hue (FPI HN)No ratings yet
- 1 - Assignment 02 NGUYEN HOANG VIET DRFDocument23 pages1 - Assignment 02 NGUYEN HOANG VIET DRFvietnhgch210878No ratings yet
- 570 AS02 NguyenManhQuan GBS210099 GBS1004BDocument34 pages570 AS02 NguyenManhQuan GBS210099 GBS1004Bquannmgbs210099No ratings yet
- Assignment 02 Front Sheet: Unit Number and Title Unit 31: Statistics For ManagementDocument35 pagesAssignment 02 Front Sheet: Unit Number and Title Unit 31: Statistics For ManagementThu HươngNo ratings yet
- Assignment Front Sheet: Qualification BTEC Level 4 HND Diploma in BusinessDocument15 pagesAssignment Front Sheet: Qualification BTEC Level 4 HND Diploma in BusinessNguyen Ngoc Minh Chau (FGW HCM)No ratings yet
- Review-ASM1-Nguyen Thi Cam TienDocument12 pagesReview-ASM1-Nguyen Thi Cam TienNguyen Thi Cam Tien (FPI HCM)No ratings yet
- 491 - Assignment 2 Frontsheet FixDocument13 pages491 - Assignment 2 Frontsheet FixMuoi VanNo ratings yet
- ASM2 TemplateDocument23 pagesASM2 Templatenlcm020298No ratings yet
- Assignment 1Document27 pagesAssignment 1Quỳnh MaiNo ratings yet
- Assignment 1-Ap-Nguyen Quoc PhuDocument13 pagesAssignment 1-Ap-Nguyen Quoc Phumuon nam tran dai nghiaNo ratings yet
- Final - Unit 31. SFM Assignment 1 of 3 - 2021Document3 pagesFinal - Unit 31. SFM Assignment 1 of 3 - 2021thai hoangNo ratings yet
- Asm1 Bi Group2 2ST Buithanhluong BH00174Document25 pagesAsm1 Bi Group2 2ST Buithanhluong BH00174Lương BùiNo ratings yet
- 5060 - Assignment 2 - GBH210959Document31 pages5060 - Assignment 2 - GBH210959phuongnqgbh210959No ratings yet
- 5038 Accounting NguyenThiThanhLan BH00971-4Document25 pages5038 Accounting NguyenThiThanhLan BH00971-4Nguyen Thanh LongNo ratings yet
- Pham Manh Hiep (FGW HN) - 462890 - 0Document14 pagesPham Manh Hiep (FGW HN) - 462890 - 0Vang Phu Qui (FGW HN)No ratings yet
- 1 - Unit 49 - 5131 - Assignment 1 - GBS210603 - PHAM TRAN MINH HIẾUDocument31 pages1 - Unit 49 - 5131 - Assignment 1 - GBS210603 - PHAM TRAN MINH HIẾUhieuptmgbs210603No ratings yet
- Asm2 1631Document23 pagesAsm2 1631Minh ThưNo ratings yet
- HR 22Document25 pagesHR 22Quang Hưng TrầnNo ratings yet
- Studying The Impact of Mergers and Acquisitions On The Aviation IndustryDocument55 pagesStudying The Impact of Mergers and Acquisitions On The Aviation IndustryJatin SharmaNo ratings yet
- 5047 ASM2-NguyenNLT GBD1009 GBD210645Document36 pages5047 ASM2-NguyenNLT GBD1009 GBD210645Nguyen Le Trang Nguyen (FGW DN)No ratings yet
- Final Asm2 BBE NguyenTrongHiep BH01134Document37 pagesFinal Asm2 BBE NguyenTrongHiep BH01134Linh ĐồngNo ratings yet
- Date Received 1st SubmissionDocument26 pagesDate Received 1st SubmissionHuy LêNo ratings yet
- HR 2Document24 pagesHR 2Quang Hưng TrầnNo ratings yet
- Assignment Front Sheet: Date Received (1 Submission) Re-Submission Date Date Received (2 Submission)Document28 pagesAssignment Front Sheet: Date Received (1 Submission) Re-Submission Date Date Received (2 Submission)Phan Phu Truong (FGW HCM)No ratings yet
- Summer Internship ProgrammeDocument20 pagesSummer Internship Programme2248019No ratings yet
- 570-Asm1-Trần Phước VinhDocument33 pages570-Asm1-Trần Phước Vinhcamthuy1611_41546015No ratings yet
- Ha Bao Khang Assingnment 1, ADocument19 pagesHa Bao Khang Assingnment 1, ABảo KhangNo ratings yet
- Assignment 1: Business IntelligenceDocument40 pagesAssignment 1: Business IntelligenceThanh TaiNo ratings yet
- Project Report TextDocument23 pagesProject Report TextSwapnil SanasNo ratings yet
- Ass1 - 1641 - Bui Hoang Long - GCS190639 PDFDocument24 pagesAss1 - 1641 - Bui Hoang Long - GCS190639 PDFLê Tấn NghĩaNo ratings yet
- Business Evironment 1Document40 pagesBusiness Evironment 1Huỳnh Thị Tú TrinhNo ratings yet
- H I ĐĂNG Assigment 3 1641Document17 pagesH I ĐĂNG Assigment 3 1641Huynh Ngoc Hai Dang (FGW DN)No ratings yet
- Phân Tích Môi Trư NG VI Mô Và VĨ Mô C A FPTDocument44 pagesPhân Tích Môi Trư NG VI Mô Và VĨ Mô C A FPTthuỷ biên đỗNo ratings yet
- Mpap Final FinalDocument32 pagesMpap Final FinalRukshana KitchilNo ratings yet
- Assignment 1 Front SheetDocument27 pagesAssignment 1 Front SheetTina NguyenNo ratings yet
- HRM 2Document24 pagesHRM 2Quang Hưng TrầnNo ratings yet
- Unit 14 Assignment 1 Business Inteligent PDFDocument12 pagesUnit 14 Assignment 1 Business Inteligent PDFTrần Vũ LinhNo ratings yet
- Assignment 01 Front Sheet: Unit Number and Title Unit 31: Statistics For ManagementDocument11 pagesAssignment 01 Front Sheet: Unit Number and Title Unit 31: Statistics For ManagementTa Ngoc Anh (FGW HCM)No ratings yet
- Khushpreet MbaDocument55 pagesKhushpreet MbaKaran SandhuNo ratings yet
- Sadesh Bawantha Student Number - Cl/Hndbsm/80/15Document30 pagesSadesh Bawantha Student Number - Cl/Hndbsm/80/15Thanula BawanthaNo ratings yet
- 570 Assignment 2Document20 pages570 Assignment 2Nguyen Duc AnhNo ratings yet
- Parth ReportDocument31 pagesParth ReportParth BadigerNo ratings yet
- Asm1 GBH210595 5035Document16 pagesAsm1 GBH210595 5035phuongnqgbh210959No ratings yet
- Asm1 - 5038 Hoang Thi Minh Phuong.Document18 pagesAsm1 - 5038 Hoang Thi Minh Phuong.phuongdi1245No ratings yet
- Business Plan Handbook: Practical guide to create a business planFrom EverandBusiness Plan Handbook: Practical guide to create a business planRating: 5 out of 5 stars5/5 (1)
- 1.st Asm2 LM TranHaiYen TADocument20 pages1.st Asm2 LM TranHaiYen TALinh ĐồngNo ratings yet
- Final Asm1 AccountingPrinciples NguyenKimNganDocument26 pagesFinal Asm1 AccountingPrinciples NguyenKimNganLinh ĐồngNo ratings yet
- Final Asm2 LM TranHaiYen TADocument27 pagesFinal Asm2 LM TranHaiYen TALinh ĐồngNo ratings yet
- Engver Assignment1 PM TranThuyDuongDocument40 pagesEngver Assignment1 PM TranThuyDuongLinh ĐồngNo ratings yet
- Asm1 PMDocument45 pagesAsm1 PMLinh ĐồngNo ratings yet
- Asm1 LM NguyenKimNgan FinalDocument28 pagesAsm1 LM NguyenKimNgan FinalLinh ĐồngNo ratings yet
- Introduction To Probabilistic Analysis: Homework #1Document8 pagesIntroduction To Probabilistic Analysis: Homework #1Paul Renato MonteroNo ratings yet
- 1.stats GenEd SyllabusDocument3 pages1.stats GenEd SyllabusSubhranil SinhaNo ratings yet
- Chapter 08Document41 pagesChapter 08Hasan TarekNo ratings yet
- Chapter 3Document79 pagesChapter 3sirius1No ratings yet
- Z-Score: Definition, Calculation and InterpretationDocument5 pagesZ-Score: Definition, Calculation and Interpretationppkuldeep4No ratings yet
- A Test of Normality: N 1 I 3 I N 1 I 2 I 2Document5 pagesA Test of Normality: N 1 I 3 I N 1 I 2 I 2Yong Leong ChaiNo ratings yet
- How To (Maybe) Measure Laser Beam QualityDocument16 pagesHow To (Maybe) Measure Laser Beam QualityLuming ZhaoNo ratings yet
- AP Statistics Probability Student Handout: 2017-2018 EDITIONDocument13 pagesAP Statistics Probability Student Handout: 2017-2018 EDITIONsdjklf jklsdf0% (1)
- Distributions For Uncertainty Analysis - RevisedDocument12 pagesDistributions For Uncertainty Analysis - RevisedrogeriocorreaNo ratings yet
- Nuclear Counting StatisticsDocument18 pagesNuclear Counting Statisticsjeff_hammonds351No ratings yet
- Understanding The Lomb-Scargle Periodogram: Escience Institute, University of WashingtonDocument55 pagesUnderstanding The Lomb-Scargle Periodogram: Escience Institute, University of Washingtonnaniro orinanNo ratings yet
- Theory of Uncertainty of Measurement PDFDocument14 pagesTheory of Uncertainty of Measurement PDFLong Nguyễn VănNo ratings yet
- #Data Assimilation - Mathematical Concepts and Instructive ExamplesDocument140 pages#Data Assimilation - Mathematical Concepts and Instructive ExamplesMichael G. TadesseNo ratings yet
- A Montecarlo Simulation Tool To Verify The Efficiency of Operating Room PlansDocument23 pagesA Montecarlo Simulation Tool To Verify The Efficiency of Operating Room PlansAditya PrasharNo ratings yet
- Central Limit Theorem: Mat02 - Statistics and ProbabilityDocument20 pagesCentral Limit Theorem: Mat02 - Statistics and ProbabilityKd CaisedoNo ratings yet
- StatisticsDocument41 pagesStatisticsSiddharth DasNo ratings yet
- 406 QM MCQ 75Document3 pages406 QM MCQ 75Preet GalaniNo ratings yet
- Tutorial Chapter 6Document5 pagesTutorial Chapter 6Prasun ThapaNo ratings yet
- Unit 4 SPCDocument15 pagesUnit 4 SPCBhupendra KarandikarNo ratings yet
- Full Download Book Statistics For Business and Economics 10Th Global Edition PDFDocument41 pagesFull Download Book Statistics For Business and Economics 10Th Global Edition PDFkevin.martinez492100% (29)
- Uncertainty, Data & Judgement: Extra ExercisesDocument53 pagesUncertainty, Data & Judgement: Extra ExercisesSergio GoldinNo ratings yet
- Statistics and Probability Quiz 1 Exploring Random VariableDocument3 pagesStatistics and Probability Quiz 1 Exploring Random Variablejuan ramosNo ratings yet
- Confidence Intervals For Kelly CriterionDocument12 pagesConfidence Intervals For Kelly Criterionsuedesuede100% (1)
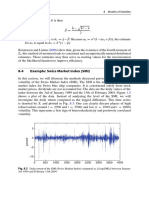
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- Journal of The American Statistical AssociationDocument5 pagesJournal of The American Statistical AssociationRudi JuliantoNo ratings yet
- Handout 4 - Statistical IntervalDocument13 pagesHandout 4 - Statistical Intervalabrilapollo.siaNo ratings yet
- Estimation and Hypothesis Testing of Cointegration Vectors in Gaussian Vector Auto Regressive ModelsDocument31 pagesEstimation and Hypothesis Testing of Cointegration Vectors in Gaussian Vector Auto Regressive ModelsMenaz AliNo ratings yet