Download as pdf or txt
You might also like
- Nna Notary Signing Agent National Loan Documents Sourc2Nd Edition National Notary Association Download PDF ChapterDocument51 pagesNna Notary Signing Agent National Loan Documents Sourc2Nd Edition National Notary Association Download PDF Chapteranthony.pajtas795100% (9)
- MERS Case Law - MERS Milestone ReportDocument10 pagesMERS Case Law - MERS Milestone Reportwinstons231167% (3)
- Creating A Story On Employee Data SheetDocument8 pagesCreating A Story On Employee Data SheetNgumbau MasilaNo ratings yet
- Exercise - Multivariate Analysis - Jupyter NotebookDocument14 pagesExercise - Multivariate Analysis - Jupyter NotebookandonifikriNo ratings yet
- Leer Los Datos: Import As Import As Import As From Import From ImportDocument14 pagesLeer Los Datos: Import As Import As Import As From Import From ImportRicardo Sebastian100% (1)
- Quiet Title Actions - Suit For Quiet TitleDocument5 pagesQuiet Title Actions - Suit For Quiet TitleRK Corbes25% (4)
- Bank Marketing InglesDocument37 pagesBank Marketing InglesFlavio SalazarNo ratings yet
- Helping The Hardest Hit NJHMFADocument61 pagesHelping The Hardest Hit NJHMFApjbergNo ratings yet
- Experiment - 3 Final DraftDocument9 pagesExperiment - 3 Final DraftSiffatjot SinghNo ratings yet
- Step - 05Document56 pagesStep - 05BhuveshNo ratings yet
- Cleaning DataDocument18 pagesCleaning DataVicky VickyNo ratings yet
- Employee DataDocument15 pagesEmployee Datahoài ngọcNo ratings yet
- Job DataDocument12 pagesJob DataTrần Nhật HàoNo ratings yet
- Loan Sanction TestDocument22 pagesLoan Sanction TestAnand Anubhav DataAnalyst Batch48No ratings yet
- Practical 3Document2 pagesPractical 3VatsalNo ratings yet
- DS - Assig-03-Part-I - Jupyter NotebookDocument8 pagesDS - Assig-03-Part-I - Jupyter NotebookYash ShindeNo ratings yet
- Income Qualification Project3Document40 pagesIncome Qualification Project3NikhilNo ratings yet
- Python Sklearn Linear RegressionDocument45 pagesPython Sklearn Linear RegressionSurya Pranav AnnadanamNo ratings yet
- Logistic RegressionDocument28 pagesLogistic RegressiondgdangelodgNo ratings yet
- In Class Test - JoinsDocument3 pagesIn Class Test - JoinsJeewantha SenanayakeNo ratings yet
- File Da Tien Xu LyDocument28 pagesFile Da Tien Xu LyduyNo ratings yet
- Ket Qua Du BaoDocument4 pagesKet Qua Du BaoduyNo ratings yet
- Predictive Modelling ProjectDocument28 pagesPredictive Modelling ProjectPARIJAT DEVNo ratings yet
- fiNAL RESULT MergedDocument42 pagesfiNAL RESULT MergedPhonkNo ratings yet
- Employee Survey & Analysis: This Survey Was Done On 267 EmployeesDocument18 pagesEmployee Survey & Analysis: This Survey Was Done On 267 EmployeesRody El KhalilNo ratings yet
- Logical Function Nestedif If Then Else 300 WowDocument4 pagesLogical Function Nestedif If Then Else 300 WowGAURAV GOSWAMINo ratings yet
- Daily Task 3 & 4 - Query Function & List Comprehension - 06-07-2022 - Jupyter NotebookDocument6 pagesDaily Task 3 & 4 - Query Function & List Comprehension - 06-07-2022 - Jupyter NotebookVrushali VishwasraoNo ratings yet
- Employees Burnout AnalysisDocument20 pagesEmployees Burnout AnalysisVadlamudi DhyanamalikaNo ratings yet
- Data Requested By:: James.p.harris@ons - Gsi.gov - UkDocument4 pagesData Requested By:: James.p.harris@ons - Gsi.gov - UkSummit ResearchNo ratings yet
- Medical Cost PredictionDocument27 pagesMedical Cost PredictionAbhinav RajNo ratings yet
- DSBDA2Document6 pagesDSBDA2403 Chaudhari Sanika SagarNo ratings yet
- Structural Change in Developing Countries Has It Decreased Gender InequalityDocument12 pagesStructural Change in Developing Countries Has It Decreased Gender Inequalitylifetips6786No ratings yet
- Statistical Report of The Employees Daily Wag in A Private Company. Group 2 WisdomDocument9 pagesStatistical Report of The Employees Daily Wag in A Private Company. Group 2 WisdomLuz Angeli TabosoNo ratings yet
- EstadísticaDocument2 pagesEstadísticaJuliana Maria Daniela Muñoz RodriguezNo ratings yet
- BS Assignment 2Document2 pagesBS Assignment 2045005No ratings yet
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- Attrition in Indian BPO IndustryDocument19 pagesAttrition in Indian BPO IndustrySushil BaralNo ratings yet
- Histogram, PDF, CDF Dan Peta Penyebaran Titik Bor: Pemodelan Dan Evaluasi CadanganDocument9 pagesHistogram, PDF, CDF Dan Peta Penyebaran Titik Bor: Pemodelan Dan Evaluasi CadanganupiekupittNo ratings yet
- Chapter One: Introduction: 1.1. Background of The ReportDocument9 pagesChapter One: Introduction: 1.1. Background of The ReportKmj MuheetNo ratings yet
- Chapter One: Introduction: 1.1. Background of The ReportDocument9 pagesChapter One: Introduction: 1.1. Background of The ReportKmj MuheetNo ratings yet
- Hypothesis Test: Mean vs. Hypothesized Value: Source SS DF MS F P-ValueDocument11 pagesHypothesis Test: Mean vs. Hypothesized Value: Source SS DF MS F P-ValueJuan Carlos ObesoNo ratings yet
- Business Case - Aerofit - Descriptive Statistics Probability (Final)Document1 pageBusiness Case - Aerofit - Descriptive Statistics Probability (Final)BEST OF BEST100% (1)
- Delicious Ice-Cream at Your Door Steps .!: First Time in Bijapur CityDocument47 pagesDelicious Ice-Cream at Your Door Steps .!: First Time in Bijapur CityomkarpraveenNo ratings yet
- Tugas Manrpo 2020 Kelompok 7 Forecasting CaseDocument13 pagesTugas Manrpo 2020 Kelompok 7 Forecasting CasewinandaNo ratings yet
- Untitled4 Assigment 3Document9 pagesUntitled4 Assigment 3eigintaeeNo ratings yet
- Presentasi: SOAL Dan JawabanDocument18 pagesPresentasi: SOAL Dan JawabanAkkhu Anx AmkNo ratings yet
- PCA Problem Statement With AnswerDocument22 pagesPCA Problem Statement With AnswerSBS MoviesNo ratings yet
- 12 - Chapter 6Document74 pages12 - Chapter 6Nikhil ShuklaNo ratings yet
- Research MethodologyDocument6 pagesResearch MethodologyMANSHI RAINo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- CardioGoodFitness - Descriptive Statistics (2) (1) - Jupyter NotebookDocument14 pagesCardioGoodFitness - Descriptive Statistics (2) (1) - Jupyter NotebookSecret PsychologyNo ratings yet
- Limpieza de DatosDocument32 pagesLimpieza de DatosGerardo Daniel Cañete RiosNo ratings yet
- DATA SCIENCE IDC 302 End Sem ProjectDocument1 pageDATA SCIENCE IDC 302 End Sem Projectsoniakar3000No ratings yet
- Customer Retention in BankDocument27 pagesCustomer Retention in BankHarun ul Rasheed ShaikNo ratings yet
- Computer ppt4 DTDocument49 pagesComputer ppt4 DTKamarina Mohd ZainNo ratings yet
- Logistic RegressionDocument12 pagesLogistic RegressionKagade AjinkyaNo ratings yet
- HRM Assignment - AnalyticsDocument7 pagesHRM Assignment - AnalyticsDeeksha VermaNo ratings yet
- Rsran046 - Sho Adjacencies-CellpairDocument10 pagesRsran046 - Sho Adjacencies-CellpairOnnyNo ratings yet
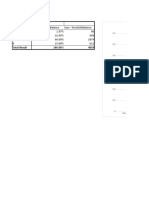
- Data Worklifebalancesum - Worklifebalance Sum - Worklifebalance 1 1.97% 80 2 16.95% 688 3 66.00% 2679 4 15.08% 612Document285 pagesData Worklifebalancesum - Worklifebalance Sum - Worklifebalance 1 1.97% 80 2 16.95% 688 3 66.00% 2679 4 15.08% 612Namita BhattNo ratings yet
- Breakout Session - TaskDocument5 pagesBreakout Session - Taskandrew.tugumeNo ratings yet
- RSRAN046 - SHO Adjacencies-CELLPAIR-whole Period-Rsran WCDMA17 SQL Reports RSRAN046 xml-2019 09 06-15 08 24 560Document10 pagesRSRAN046 - SHO Adjacencies-CELLPAIR-whole Period-Rsran WCDMA17 SQL Reports RSRAN046 xml-2019 09 06-15 08 24 560Nguyen Quoc DoanNo ratings yet
- Stern's MBA 1 Students Expect To Make The Big Bucks After Graduation!Document18 pagesStern's MBA 1 Students Expect To Make The Big Bucks After Graduation!Mukesh ManwaniNo ratings yet
- Mock - Coding: Numpy NP CSV Sklearn - Linear - Model Pandas PD Matplotlib - Pyplot PLT Sklearn - MetricsDocument2 pagesMock - Coding: Numpy NP CSV Sklearn - Linear - Model Pandas PD Matplotlib - Pyplot PLT Sklearn - MetricsYTPUB001No ratings yet
- RIND 1 JUL 2021 VerB Resol TipsDocument5 pagesRIND 1 JUL 2021 VerB Resol TipsjopsrodriguesNo ratings yet
- 01 Slides - enDocument246 pages01 Slides - enjopsrodriguesNo ratings yet
- 03 HardwareDocument6 pages03 HardwarejopsrodriguesNo ratings yet
- 02 ColourDocument8 pages02 ColourjopsrodriguesNo ratings yet
- 01 Visual PerceptionDocument7 pages01 Visual PerceptionjopsrodriguesNo ratings yet
- 04 2dtransformsDocument3 pages04 2dtransformsjopsrodriguesNo ratings yet
- (66309) Extended AbstractDocument5 pages(66309) Extended AbstractjopsrodriguesNo ratings yet
- Foreclosure From Lenders Perspective - 2008Document65 pagesForeclosure From Lenders Perspective - 2008pennyh72No ratings yet
- Commercial Mortgage Broker Leads ListDocument102 pagesCommercial Mortgage Broker Leads ListMalik UzairNo ratings yet
- AAOIFI SS - 39 - MorgageDocument24 pagesAAOIFI SS - 39 - MorgagenooruzzamanNo ratings yet
- This Deed of MortgageDocument2 pagesThis Deed of MortgageAAKANKSHA BHATIANo ratings yet
- RockFin Budget Highlights - 2024-25Document16 pagesRockFin Budget Highlights - 2024-25Defimediagroup LdmgNo ratings yet
- Correspondence From McCALLA RAYMER, LLC Received Feb. 3, 2016collections-February 4, 2016 - NewDocument9 pagesCorrespondence From McCALLA RAYMER, LLC Received Feb. 3, 2016collections-February 4, 2016 - NewTiyemerenaset Ma'at El100% (1)
- Literature Review On Loan DelinquencyDocument4 pagesLiterature Review On Loan Delinquencyafmaadalrefplh100% (1)
- RFBTDocument1 pageRFBTJims Leñar CezarNo ratings yet
- AmbrayDocument3 pagesAmbrayJosie Alonzo AndradeNo ratings yet
- Letter of ForbearanceDocument2 pagesLetter of ForbearancedidNo ratings yet
- Chattel MortgageDocument9 pagesChattel MortgageMa. Louise Aviso0% (1)
- Long-Term Social Impacts and Financial Costs of Foreclosure On Families and Communities of ColorDocument49 pagesLong-Term Social Impacts and Financial Costs of Foreclosure On Families and Communities of ColorJH_CarrNo ratings yet
- D.E. 126-DEFENDANTS' MEMORANDUM IN SUPPORT OF THEIR OPPOSITION TO RELATOR'S MOTION FOR LEAVE TO FILE THIRD AMENDED COMPLAINT, Apr. 27, 2018Document46 pagesD.E. 126-DEFENDANTS' MEMORANDUM IN SUPPORT OF THEIR OPPOSITION TO RELATOR'S MOTION FOR LEAVE TO FILE THIRD AMENDED COMPLAINT, Apr. 27, 2018larry-612445No ratings yet
- Written Assignment TemplateDocument81 pagesWritten Assignment TemplateAqib AzizNo ratings yet
- Canadian Mortgage Calculator: Inputs Balance at TermDocument33 pagesCanadian Mortgage Calculator: Inputs Balance at Termbracilides82No ratings yet
- An Introduction To The Subprime Crisis in The U.SDocument25 pagesAn Introduction To The Subprime Crisis in The U.SAdeel RanaNo ratings yet
- Basic Banking Tools and VocabularyDocument1 pageBasic Banking Tools and Vocabularyperrine11No ratings yet
- Gurpreet RandhawaDocument93 pagesGurpreet RandhawaMelissa MontalvoNo ratings yet
- WB 1a.1b.2a.2b.3a Siedykh ADocument30 pagesWB 1a.1b.2a.2b.3a Siedykh AАнастасия СедыхNo ratings yet
- Business Math q2 m9 AnswersDocument4 pagesBusiness Math q2 m9 Answersangel annNo ratings yet
- Redemption BAHL (Faizan Pharmacy) SamundriDocument2 pagesRedemption BAHL (Faizan Pharmacy) Samundrifaizanhafeez786No ratings yet
- Housing Finance Literature ReviewDocument7 pagesHousing Finance Literature Reviewvagipelez1z2100% (1)
- The Negotiation and Assignment of The Promissory NoteDocument7 pagesThe Negotiation and Assignment of The Promissory NotePatricia ParkeNo ratings yet
- Fixed-Rate Mortgage, Monthly PaymentsDocument41 pagesFixed-Rate Mortgage, Monthly Paymentslinda zyongweNo ratings yet
- Stop Foreclosure NowDocument2 pagesStop Foreclosure Nowmugman100% (1)
- Dacion en PagoDocument2 pagesDacion en Pagohailglee1925No ratings yet