Download as pdf or txt
You might also like
- Control Engineering Practice: Ronghua Zhang, Yaonan Wang, Wenfang Xie, Tingting Shu, Haoran Tan, Yiming JiangDocument14 pagesControl Engineering Practice: Ronghua Zhang, Yaonan Wang, Wenfang Xie, Tingting Shu, Haoran Tan, Yiming JiangPablo Sari CedilloNo ratings yet
- Fcteg 02 632417Document5 pagesFcteg 02 632417mda mpsNo ratings yet
- A Realtime Path Planning AlgorithmDocument14 pagesA Realtime Path Planning AlgorithmHanbang GaoNo ratings yet
- An Improved A-Star Based P P AlgoDocument13 pagesAn Improved A-Star Based P P AlgoGergely HornyakNo ratings yet
- Kinematics Modelling and Trajectory Planning For An Industrial - 2018Document6 pagesKinematics Modelling and Trajectory Planning For An Industrial - 2018Chanel For KidsNo ratings yet
- Frobt 09 812849Document9 pagesFrobt 09 8128491032220018No ratings yet
- Real-Time Control and Optimization of InternalDocument11 pagesReal-Time Control and Optimization of Internalanthonyca18mNo ratings yet
- 1 s2.0 S0952197619300089 MainDocument16 pages1 s2.0 S0952197619300089 Main100NadaNo ratings yet
- Mobile Robot Path Planning in Dynamic Environments Through Globally Guided Reinforcement LearningDocument8 pagesMobile Robot Path Planning in Dynamic Environments Through Globally Guided Reinforcement LearningVarun AgarwalNo ratings yet
- Final Year Project UpgradedDocument17 pagesFinal Year Project UpgradedEE-B 085 Pritam BiswasNo ratings yet
- Electronics 11 03660Document21 pagesElectronics 11 03660Rahmadi IlyassNo ratings yet
- FP 3Document7 pagesFP 34AL20AI004Anush PoojaryNo ratings yet
- Cui 2021 J. Phys. Conf. Ser. 1865 042068Document10 pagesCui 2021 J. Phys. Conf. Ser. 1865 042068mujahid naumanNo ratings yet
- Sampling Based Robot Motion Planning: Dept. of Ece, Bgsit 2015page 1Document20 pagesSampling Based Robot Motion Planning: Dept. of Ece, Bgsit 2015page 1punithNo ratings yet
- SensorsDocument20 pagesSensorsfaith_khp73301No ratings yet
- Optimal Dispatch Model of Active Distribution Network Based On Particle Swarm Optimization Algorithm With Random WeightDocument4 pagesOptimal Dispatch Model of Active Distribution Network Based On Particle Swarm Optimization Algorithm With Random WeightNicolas LopezNo ratings yet
- Reinforcement Learning Based Approach For Mobile Robot NavigationDocument4 pagesReinforcement Learning Based Approach For Mobile Robot NavigationAkhil Bandamidapalli me20b016No ratings yet
- Chewu 2018 IOP Conf. Ser.: Mater. Sci. Eng. 402 012022Document10 pagesChewu 2018 IOP Conf. Ser.: Mater. Sci. Eng. 402 012022oubahaNo ratings yet
- Yi 2021Document4 pagesYi 2021Sudhanshu MauryaNo ratings yet
- Paper Ieee Forward and Inverse Kinematics of Irb1200Document8 pagesPaper Ieee Forward and Inverse Kinematics of Irb1200Thắng LêNo ratings yet
- Generic Resume TemplateDocument1 pageGeneric Resume Templatekalevaibhav436No ratings yet
- A Novel Low-Cost Quadruped Robot With Joint Fault-Tolerant ControlDocument6 pagesA Novel Low-Cost Quadruped Robot With Joint Fault-Tolerant Controlroboticanvidia42No ratings yet
- On Reducing The Effect of Covariate Factors in GaiDocument9 pagesOn Reducing The Effect of Covariate Factors in GaiHosein GhaeminiaNo ratings yet
- Sensors 23 03521Document15 pagesSensors 23 03521Mercedes Castañeda JNo ratings yet
- Efficient Heuristic Generation For Robot Path Planning With Recurrent Generative ModelDocument7 pagesEfficient Heuristic Generation For Robot Path Planning With Recurrent Generative ModelVarun AgarwalNo ratings yet
- Sensors: Research and Implementation of Autonomous Navigation For Mobile Robots Based On SLAM Algorithm Under ROSDocument23 pagesSensors: Research and Implementation of Autonomous Navigation For Mobile Robots Based On SLAM Algorithm Under ROSvinay kumar yadavNo ratings yet
- ArticuloDocument3 pagesArticulofabian.aroniNo ratings yet
- Yang 2019Document11 pagesYang 2019mehulaNo ratings yet
- Liuwei NN2022 发表版Document13 pagesLiuwei NN2022 发表版sohel ranaNo ratings yet
- Ece - Ijeceierd - All New 3Document11 pagesEce - Ijeceierd - All New 3global-marketin8184No ratings yet
- Zhao - Sun - 2021 - An Accurate Positioning Method For Robotic Manipulation Based On Vision andDocument16 pagesZhao - Sun - 2021 - An Accurate Positioning Method For Robotic Manipulation Based On Vision andJueMziNo ratings yet
- R Be 550 Motion Planning ProjectDocument8 pagesR Be 550 Motion Planning ProjectAkash SridharanNo ratings yet
- Coupled Bilinear Discriminant Projection For Cross-View Gait RecognitionDocument14 pagesCoupled Bilinear Discriminant Projection For Cross-View Gait Recognitionwenhao zhangNo ratings yet
- Bounding Gait Control of A Parallel Quadruped Robotindustrial RobotDocument12 pagesBounding Gait Control of A Parallel Quadruped Robotindustrial RobotluukverstegenNo ratings yet
- Research On FPGA Based Convolutional Neural Network Acceleration MethodDocument4 pagesResearch On FPGA Based Convolutional Neural Network Acceleration MethodMehmet Kadir KoçNo ratings yet
- Design and Analysis of Mobile Locomation ApproachDocument8 pagesDesign and Analysis of Mobile Locomation ApproachResearch ParkNo ratings yet
- Human-Following of Mobile Robots Based On Object Tracking and Depth VisionDocument5 pagesHuman-Following of Mobile Robots Based On Object Tracking and Depth VisionDuy ChungNo ratings yet
- Dynamic Robot Path Planning Using An Enhanced Simulated Annealing Approach 2013 Applied Mathematics and ComputationDocument18 pagesDynamic Robot Path Planning Using An Enhanced Simulated Annealing Approach 2013 Applied Mathematics and Computationsmkumaran90No ratings yet
- Reinforcement Based Mobile Robot Path Planning With Improved Dynamic Window Approach in Unknown EnvironmentDocument27 pagesReinforcement Based Mobile Robot Path Planning With Improved Dynamic Window Approach in Unknown EnvironmentjohnNo ratings yet
- A Feasible Identification Method of Uncertainty Responses For Vehicle StructuresDocument17 pagesA Feasible Identification Method of Uncertainty Responses For Vehicle Structurespad abtNo ratings yet
- An Overview-Mobile Robot Path Planning NCETEMT-2021 - Paper - 152Document4 pagesAn Overview-Mobile Robot Path Planning NCETEMT-2021 - Paper - 152Vesag nNo ratings yet
- 48 BFDocument9 pages48 BFIsmail LahlouNo ratings yet
- Wevj 14 00276Document16 pagesWevj 14 00276Yajan AgarwalNo ratings yet
- Development of A Planar Cable Parallel R 6301e1beDocument9 pagesDevelopment of A Planar Cable Parallel R 6301e1beIsmail LahlouNo ratings yet
- 四足机器人ILQPDocument12 pages四足机器人ILQP咸水鱼No ratings yet
- 002 Pattern DetectionDocument15 pages002 Pattern DetectionPratik TakudageNo ratings yet
- Advances in Engineering Software: Jun-Hao Liang, Ching-Hung LeeDocument10 pagesAdvances in Engineering Software: Jun-Hao Liang, Ching-Hung Leesmkumaran90No ratings yet
- A Model Based Path Planning Algorithm For Self-Driving Cars in Dynamic EnvironmentDocument6 pagesA Model Based Path Planning Algorithm For Self-Driving Cars in Dynamic EnvironmentSiddharth UNo ratings yet
- Yang 2019 J. Phys. Conf. Ser. 1311 012048Document8 pagesYang 2019 J. Phys. Conf. Ser. 1311 012048qq1175988837No ratings yet
- Ijsita200401sharida 295252Document26 pagesIjsita200401sharida 295252darafehNo ratings yet
- Algorithms 15 00477 v3Document16 pagesAlgorithms 15 00477 v3Arda UnsalNo ratings yet
- Path Planning of Mobile Robot in Unknown EnvironmentDocument6 pagesPath Planning of Mobile Robot in Unknown EnvironmentlaishramNo ratings yet
- Proposal Relation Network For Temporal Action Detection: (Wxiang, QZW, Cgao, Nsang) @hust - Edu.cnDocument4 pagesProposal Relation Network For Temporal Action Detection: (Wxiang, QZW, Cgao, Nsang) @hust - Edu.cnVaibhavi LokegaonkarNo ratings yet
- 2019 KSJ IJAMT v101 pp243-259Document17 pages2019 KSJ IJAMT v101 pp243-259Viktor SokolovNo ratings yet
- Khlil 2020 IOP Conf. Ser. Mater. Sci. Eng. 745 012068Document8 pagesKhlil 2020 IOP Conf. Ser. Mater. Sci. Eng. 745 012068Juliana Ricato Musso SilvaNo ratings yet
- Path Planning For A Mobile Robot in Dynamic Environments: International Journal of Physical Sciences September 2011Document12 pagesPath Planning For A Mobile Robot in Dynamic Environments: International Journal of Physical Sciences September 2011楊凱閔No ratings yet
- MT 461 Path Planning in MobileRobotsDocument6 pagesMT 461 Path Planning in MobileRobotsUmair AzizNo ratings yet
- Applsci 12 05999Document11 pagesApplsci 12 05999Videh PatelNo ratings yet
- Learning Applied to Ground Vehicles: Enhancing Ground Vehicle Performance through Computer Vision LearningFrom EverandLearning Applied to Ground Vehicles: Enhancing Ground Vehicle Performance through Computer Vision LearningNo ratings yet
- Referencing: Principles, Practice and Problems: Colin NevilleDocument8 pagesReferencing: Principles, Practice and Problems: Colin NevilleAnonymous GsCkcq8fNo ratings yet
- Bartending Module FinalsDocument94 pagesBartending Module FinalsNorvina Tesoro Dizon100% (1)
- MAED - Management and Supervision of InstructionDocument11 pagesMAED - Management and Supervision of InstructionDenis CadotdotNo ratings yet
- What Do The I Dots RevealDocument3 pagesWhat Do The I Dots RevealAshok TumuluriNo ratings yet
- Shiksha Sopan: An Initiative of IIT Community For Social UpliftmentDocument4 pagesShiksha Sopan: An Initiative of IIT Community For Social UpliftmentAmrendra NarayanNo ratings yet
- Lesson Plan - Integers, Opposites, Absolute Value: Chapter ResourcesDocument19 pagesLesson Plan - Integers, Opposites, Absolute Value: Chapter ResourcesMary Jane BugarinNo ratings yet
- Hybrid DGA Method For Power Transformer Faults Diagnosis Based On Evolutionary K-Means Clustering and Dissolved Gas Subsets AnalysisDocument8 pagesHybrid DGA Method For Power Transformer Faults Diagnosis Based On Evolutionary K-Means Clustering and Dissolved Gas Subsets AnalysisbenlahnecheNo ratings yet
- Uninstall GGDocument2 pagesUninstall GGVignesh RenganathNo ratings yet
- A Case Study On Application of The Theory of Planned Behaviour Predicting Physical Activity of Adolescents in Hong Kong 2161 0711.1000231Document6 pagesA Case Study On Application of The Theory of Planned Behaviour Predicting Physical Activity of Adolescents in Hong Kong 2161 0711.1000231Kishenthi KerisnanNo ratings yet
- Life Skill Development Solved MCQs (Set-2)Document8 pagesLife Skill Development Solved MCQs (Set-2)funny world100% (3)
- Banning of Assi-Wps OfficeDocument17 pagesBanning of Assi-Wps OfficeSarah Mae BalanNo ratings yet
- EF3e Preint Filetest 05a Answer Sheet PDFDocument1 pageEF3e Preint Filetest 05a Answer Sheet PDFDiego Real Torres NinaNo ratings yet
- 910 - B.sc. PT I Physics (Semester I & II)Document8 pages910 - B.sc. PT I Physics (Semester I & II)Priyanka KhatikNo ratings yet
- 1-7 ThesisDocument62 pages1-7 ThesisShobhit GoswamiNo ratings yet
- Swatantrayoparant Jansankhya Vruddhi Ka Krushi Vikas Par Prabhav - Ek Bhaugolik Adhyayan (Orayya Janpad Ke Vishesh Sandarbh Me)Document12 pagesSwatantrayoparant Jansankhya Vruddhi Ka Krushi Vikas Par Prabhav - Ek Bhaugolik Adhyayan (Orayya Janpad Ke Vishesh Sandarbh Me)Anonymous CwJeBCAXpNo ratings yet
- Nutrition and Stress ManagementDocument17 pagesNutrition and Stress Managementanagha_wankar2548No ratings yet
- Action Research ProsidingDocument8 pagesAction Research ProsidingHAnif KHairNo ratings yet
- HR Audit QuestionnaireDocument20 pagesHR Audit QuestionnaireNayyera AnbreenNo ratings yet
- NOv 13 2019 English 3Document2 pagesNOv 13 2019 English 3Carmela Efondo100% (1)
- Sigmund FreudDocument1 pageSigmund FreudCarla Sofía López MorenoNo ratings yet
- 1800flowers PMG - SS and Email Only PDFDocument8 pages1800flowers PMG - SS and Email Only PDFKimCanillasVincereNo ratings yet
- Positive and Normative Accounting Theory: Definition and DevelopmentDocument10 pagesPositive and Normative Accounting Theory: Definition and DevelopmentPhượng ViNo ratings yet
- UERM Minimum Qualifications For AdmissionDocument3 pagesUERM Minimum Qualifications For AdmissionNO ONENo ratings yet
- SDOIN FLAT DATA ENTRY FileDocument4 pagesSDOIN FLAT DATA ENTRY FileMARISSA MARCOSNo ratings yet
- 10.2 Lesson On How To Write A Good SpeechDocument5 pages10.2 Lesson On How To Write A Good SpeechNafis Al ZameeNo ratings yet
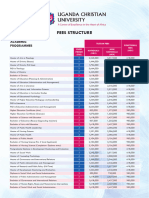
- Fees StructureDocument3 pagesFees Structurehealed928No ratings yet
- Poster On Real Time Face Recognition - Team RhetoriciansDocument1 pagePoster On Real Time Face Recognition - Team RhetoriciansAbdullah Al FahimNo ratings yet
- Zabbix General Brochure 2.0Document45 pagesZabbix General Brochure 2.0Prasad JagtapNo ratings yet
- TOEFL iBTDocument43 pagesTOEFL iBTsuponova.nilufarNo ratings yet
- UrduHindi TII RidhimaPuri LessonPlanforMeansofTransportationDocument3 pagesUrduHindi TII RidhimaPuri LessonPlanforMeansofTransportationmichaelrNo ratings yet