Download as pdf or txt
You might also like
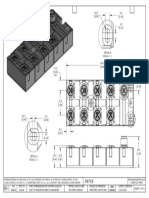
- Cross Box Manual R 10Document16 pagesCross Box Manual R 10ZalNo ratings yet
- 1lable Solution For Tuning Early-Exit Large Language Models2402.00518Document1 page1lable Solution For Tuning Early-Exit Large Language Models2402.00518鄭惠文No ratings yet
- 9 - PDFsam - R Tuning Early-Exit Large Language Models2402.00518Document1 page9 - PDFsam - R Tuning Early-Exit Large Language Models2402.00518鄭惠文No ratings yet
- 1ly-Exit Large Language Models2402.00518Document1 page1ly-Exit Large Language Models2402.00518鄭惠文No ratings yet
- Homework 5Document6 pagesHomework 5euler96No ratings yet
- A Novel Visual Perceptual Model With An Application To Hi-Fidelity Image AnnotationDocument6 pagesA Novel Visual Perceptual Model With An Application To Hi-Fidelity Image Annotationvijay bNo ratings yet
- Document 3 - Stationnarity of DLCACDocument2 pagesDocument 3 - Stationnarity of DLCACjovana.mlnvNo ratings yet
- B) " Data - Frame".: Outliers and Missing Values (8 Marks) AnswerDocument23 pagesB) " Data - Frame".: Outliers and Missing Values (8 Marks) AnswerRaveendra Babu Gaddam100% (1)
- 14 - PDFsamEE-Tuning An Economical Yet Ge Language Models2402.00518Document1 page14 - PDFsamEE-Tuning An Economical Yet Ge Language Models2402.00518鄭惠文No ratings yet
- 1lable Solution For Tuning Early-Exit Large Language Models2402.00518Document1 page1lable Solution For Tuning Early-Exit Large Language Models2402.00518鄭惠文No ratings yet
- M1 Exercises e 1Document36 pagesM1 Exercises e 1aideebNo ratings yet
- 59710Document1 page59710nguyenanhquocdhdiNo ratings yet
- AHO-OFDM Dimming PDFDocument1 pageAHO-OFDM Dimming PDFRashed IslamNo ratings yet
- CSL01Document7 pagesCSL01Mahnoor KhanNo ratings yet
- Validation of Fps Wizard Horizontal Lifeline CalculatorDocument1 pageValidation of Fps Wizard Horizontal Lifeline CalculatorperundingtsteohgmailcomNo ratings yet
- 59719Document1 page59719nguyenanhquocdhdiNo ratings yet
- Conference Template A4Document10 pagesConference Template A4Dũng PhanNo ratings yet
- Control of Mobile Robots - Week 2Document10 pagesControl of Mobile Robots - Week 2Mridul UpadhyayNo ratings yet
- Raystar Optronics, Inc.: RX12864A1 Graphic 128x64 DotsDocument1 pageRaystar Optronics, Inc.: RX12864A1 Graphic 128x64 DotsDVTNo ratings yet
- Sim.I.am: A Robot Simulator: Coursera: Control of Mobile RobotsDocument14 pagesSim.I.am: A Robot Simulator: Coursera: Control of Mobile RobotsMridul UpadhyayNo ratings yet
- SunonDocument4 pagesSunonEmerson Müller Juarez AvilaNo ratings yet
- 256Mb E-Die SDRAM Specification: Revision 1.5 May 2004Document14 pages256Mb E-Die SDRAM Specification: Revision 1.5 May 2004Cường MchwNo ratings yet
- Deep Coverage Program - : Band + SowDocument4 pagesDeep Coverage Program - : Band + SowTaufik AndrianNo ratings yet
- Kaqy214 OptoDocument12 pagesKaqy214 OptoKABOOPATHINo ratings yet
- FC4 Standard Units Pressure CurvesDocument12 pagesFC4 Standard Units Pressure CurvesTiago Karina ElisaNo ratings yet
- EEE309 CT3 - January2016Document2 pagesEEE309 CT3 - January2016Engr. Shahidul IslamNo ratings yet
- HDM24216H-2: Dimensional DrawingDocument2 pagesHDM24216H-2: Dimensional DrawingGustavo NielNo ratings yet
- CSL0406WBCW Series: Data SheetDocument10 pagesCSL0406WBCW Series: Data SheetpabloNo ratings yet
- A General Approach To Sensitivity AnalysisDocument37 pagesA General Approach To Sensitivity AnalysisjimmymorelosNo ratings yet
- HDM 64GS24 - 2: Dimensional DrawingDocument1 pageHDM 64GS24 - 2: Dimensional DrawingAilton SorlagNo ratings yet
- Supplementary MaterialDocument1 pageSupplementary MaterialSimón Oya DíezNo ratings yet
- High Air Flow Series e 2012Document22 pagesHigh Air Flow Series e 2012John Renz Caling RetiroNo ratings yet
- Portfolio Management ProblemDocument12 pagesPortfolio Management Problemanisasheikh83No ratings yet
- Catalogue DL55 North AmericaDocument56 pagesCatalogue DL55 North AmericaJuan Ernesto PerezNo ratings yet
- Reflection FactorDocument3 pagesReflection FactorMUHAMMAD SADIQ SYAMIR BIN HASNAN MoeNo ratings yet
- DBV DimensionDocument4 pagesDBV DimensionjoeywunNo ratings yet
- Design of Source Degenerated Cascode Dual FunctionDocument25 pagesDesign of Source Degenerated Cascode Dual Functionmaia.df11No ratings yet
- KMOC302X Series: CosmoDocument10 pagesKMOC302X Series: CosmomejmakNo ratings yet
- پارتیکل سایزDocument1 pageپارتیکل سایزsaeid.mehregan.shNo ratings yet
- LMC Lem 2x2Document2 pagesLMC Lem 2x2mohiNo ratings yet
- Voltage Mode Multiplying DAC Reference DesignDocument16 pagesVoltage Mode Multiplying DAC Reference DesignMouloud IbelaidenNo ratings yet
- ระยะห่างแถวDocument1 pageระยะห่างแถวWarajak N.No ratings yet
- 32-06 Lead in - Lead Out PDFDocument1 page32-06 Lead in - Lead Out PDFDavid BumbaloughNo ratings yet
- The Tolerance Unless Classified 0.3mm: Outline Dimension & Block DiagramDocument1 pageThe Tolerance Unless Classified 0.3mm: Outline Dimension & Block DiagramadilNo ratings yet
- Principles of Chemistry A Molecular Approach 2nd Edition Tro Solutions Manual 1Document36 pagesPrinciples of Chemistry A Molecular Approach 2nd Edition Tro Solutions Manual 1tammycontrerasgdaxwypisr100% (33)
- Machine Learning Basics: Lecture Slides For Chapter 5 of Deep Learning Ian Goodfellow 2016-09-26Document14 pagesMachine Learning Basics: Lecture Slides For Chapter 5 of Deep Learning Ian Goodfellow 2016-09-26Indra Kelana JayaNo ratings yet
- ARCH GARCH ModelsDocument8 pagesARCH GARCH ModelsnicolzeeNo ratings yet
- Eaton Em2507 Euromag Terminal Blocks Cage Clamp Da 1608398Document2 pagesEaton Em2507 Euromag Terminal Blocks Cage Clamp Da 1608398Dinu Racautanu MironNo ratings yet
- Raystar Optronics, Inc.: RC2002A Character 20x2Document1 pageRaystar Optronics, Inc.: RC2002A Character 20x2Zeyad AymanNo ratings yet
- Dalettes Coffrage Adeoti Sa: PK 0+000 - PK 0+030 2Document2 pagesDalettes Coffrage Adeoti Sa: PK 0+000 - PK 0+030 2aziz gbedourorouNo ratings yet
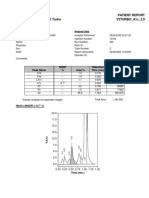
- Bio-Rad CDM System Patient Report Medcis Pathlab Variant Turbo V2Turbo - A1C - 2.0Document1 pageBio-Rad CDM System Patient Report Medcis Pathlab Variant Turbo V2Turbo - A1C - 2.0CNo ratings yet
- The Tolerance Unless Classified 0.3mm: Outline Dimension & Block DiagramDocument2 pagesThe Tolerance Unless Classified 0.3mm: Outline Dimension & Block DiagramhenriquegonferNo ratings yet
- VLT Series 2000: Specification Chart InstallationDocument45 pagesVLT Series 2000: Specification Chart InstallationErwin SusantoNo ratings yet
- Adapalene and BPO Gel 0.1% and 2.5% (RLD Vs TEST)Document9 pagesAdapalene and BPO Gel 0.1% and 2.5% (RLD Vs TEST)Rahul MayeeNo ratings yet
- ANN For Fitting Applications (Data Modeling)Document47 pagesANN For Fitting Applications (Data Modeling)ahmedNo ratings yet
- CPT Static Liquefaction Analysis PlotsDocument1 pageCPT Static Liquefaction Analysis PlotsmyplaxisNo ratings yet
- Preliminary Footing Design Template: Jsdesign EngineeringDocument2 pagesPreliminary Footing Design Template: Jsdesign EngineeringJohnnyNo ratings yet
- P1 (4.5) Material Change Sheetpile1Document1 pageP1 (4.5) Material Change Sheetpile1Utari Tri NoviatiNo ratings yet
- LTE FDD MIMO Technology: ZTE UniversityDocument33 pagesLTE FDD MIMO Technology: ZTE UniversityjedossousNo ratings yet
- Julia Raymond Lorenz (2000) PDFDocument79 pagesJulia Raymond Lorenz (2000) PDFDimas DcnNo ratings yet
- Mastery and Achievement Levels in Empowerment Technologies of Grade 11 Stem Learners Taught Under Blended Learning ModalityDocument33 pagesMastery and Achievement Levels in Empowerment Technologies of Grade 11 Stem Learners Taught Under Blended Learning ModalityGerome RogelNo ratings yet
- Amazing Grace Diagram Lesson Plan 2 6 17Document2 pagesAmazing Grace Diagram Lesson Plan 2 6 17api-310967404No ratings yet
- Andrea Casper: 5 Reasons Your School Needs Flexible Learning SpacesDocument3 pagesAndrea Casper: 5 Reasons Your School Needs Flexible Learning SpacesFrank ElijordeNo ratings yet
- Joseph Strawder Resume - 2019 Updatedraft - As Comments 4-19-2019Document1 pageJoseph Strawder Resume - 2019 Updatedraft - As Comments 4-19-2019api-580838834No ratings yet
- Technology Observation FormDocument2 pagesTechnology Observation Formapi-190174138100% (1)
- Drs. Martinus Gea, M.Si 2019Document53 pagesDrs. Martinus Gea, M.Si 2019Rival ImanuelNo ratings yet
- The Challenges of Music Teaching and Learning in Primary Schools in Offinso South MunicipalityDocument5 pagesThe Challenges of Music Teaching and Learning in Primary Schools in Offinso South MunicipalityHannah Elizabeth GarridoNo ratings yet
- Jean PiagetDocument2 pagesJean PiagetsharmilaNo ratings yet
- Parameters Strongly Agree Agree Disagree Strongl y Disagree: Teacher-Student Relationship QuestionnaireDocument3 pagesParameters Strongly Agree Agree Disagree Strongl y Disagree: Teacher-Student Relationship QuestionnaireJoyce Voon Ern Cze100% (1)
- Kufa Solomon Final ProjectDocument62 pagesKufa Solomon Final ProjectEmmanuel YakubuNo ratings yet
- Contextualized Lesson Plan in BiologyDocument1 pageContextualized Lesson Plan in Biologychorie navarreteNo ratings yet
- Pengaruh Gaya Belajar David Kolb (Diverger, Assimilator, Materi Pencemaran LingkunganDocument8 pagesPengaruh Gaya Belajar David Kolb (Diverger, Assimilator, Materi Pencemaran LingkunganSandy zaidNo ratings yet
- New SAT Reading Practice Tests: New SAT Writing and Language Practice Tests: New SAT Math Practice TestsDocument16 pagesNew SAT Reading Practice Tests: New SAT Writing and Language Practice Tests: New SAT Math Practice TestsPaulNo ratings yet
- Accomplishment Report On Reading Program (Phil-Iri) : RationaleDocument3 pagesAccomplishment Report On Reading Program (Phil-Iri) : RationaleHenio NanongNo ratings yet
- Reflection Paper PDFDocument3 pagesReflection Paper PDFryanadamgrayNo ratings yet
- Japanese Management PractiseDocument17 pagesJapanese Management PractiseLauraNo ratings yet
- School Memo No.4s.2024 Inset 2024Document16 pagesSchool Memo No.4s.2024 Inset 2024Christopher OlayaNo ratings yet
- A New Leadership Curriculum: The Multiplication of IntelligenceDocument4 pagesA New Leadership Curriculum: The Multiplication of IntelligenceGisele PhaloNo ratings yet
- Catch-Up Friday Improving The Reading ProficiencyDocument13 pagesCatch-Up Friday Improving The Reading ProficiencyAlyssa DutolloNo ratings yet
- Amber Lees ResumeDocument1 pageAmber Lees Resumeapi-460543617No ratings yet
- Action Research For Classroom TeachersDocument4 pagesAction Research For Classroom TeachersJoshua FaradayNo ratings yet
- Cambridge Primary Science Book 3Document13 pagesCambridge Primary Science Book 3Alewasi WalaaNo ratings yet
- Mb1 Homework HelpDocument8 pagesMb1 Homework Helpzsbkvilpd100% (1)
- Student Mentoring FormDocument3 pagesStudent Mentoring FormbmdbmdbmdNo ratings yet
- Resume SampleDocument1 pageResume SampleMARICEL M. ROLDANNo ratings yet
- Kinds/classification of ResearchDocument11 pagesKinds/classification of Researcherwin rectoNo ratings yet
- FUTURE SCHOOL: A Blueprint For How The Education System of The Future Should Function and Why?Document142 pagesFUTURE SCHOOL: A Blueprint For How The Education System of The Future Should Function and Why?Cassie Janisch100% (1)
- Weekly Home Learning Plan: Contemporary Philippine Arts From The RegionsDocument5 pagesWeekly Home Learning Plan: Contemporary Philippine Arts From The RegionsJealf Zenia CastroNo ratings yet
- Track 2 Contract Revised Signed JG SsDocument4 pagesTrack 2 Contract Revised Signed JG Sssstone1No ratings yet