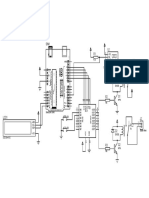
Download as pdf or txt
You might also like
- JBL Boombox PL V2.2 - Boombox 2 Portable Active SubwooferDocument51 pagesJBL Boombox PL V2.2 - Boombox 2 Portable Active SubwooferTitán Soto100% (6)
- Assignment 1Document3 pagesAssignment 1Rupak ThakurNo ratings yet
- MicroprocessorDocument11 pagesMicroprocessorMitesh KumarNo ratings yet
- Chapter 04 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionDocument137 pagesChapter 04 Computer Organization and Design, Fifth Edition: The Hardware/Software Interface (The Morgan Kaufmann Series in Computer Architecture and Design) 5th EditionPriyanka Meena67% (6)
- Schematic TDA7418TR TDA7418 20190204134459Document1 pageSchematic TDA7418TR TDA7418 20190204134459marius tanjalaNo ratings yet
- Panel PLC Biodigester Farm CigandulDocument50 pagesPanel PLC Biodigester Farm Cigandulrahmannafi kurniawanNo ratings yet
- Interface Carte Nucleo - STM32F446RE Potentiomètres: PC1 PC0Document1 pageInterface Carte Nucleo - STM32F446RE Potentiomètres: PC1 PC0Abdessamad houssainiNo ratings yet
- Wiring Blood Bank Smst. 4Document1 pageWiring Blood Bank Smst. 4Said PutraNo ratings yet
- Autoclave Uc Pic Lib I/O: ItibbDocument1 pageAutoclave Uc Pic Lib I/O: ItibbLuis Elizee Blanco100% (1)
- Indoor-Garden MEGA DAS PDFDocument1 pageIndoor-Garden MEGA DAS PDFAhmad RizalNo ratings yet
- ARDUINODocument1 pageARDUINOJLNo ratings yet
- Psdr2 GuideDocument1 pagePsdr2 GuidemarcusNo ratings yet
- 2 Winding Stepper Mortor Driver and ControlDocument1 page2 Winding Stepper Mortor Driver and ControlKishore PagarNo ratings yet
- 1175 TZ1C-Qosmio X500 X505Document43 pages1175 TZ1C-Qosmio X500 X505xingyiservice.mdy123No ratings yet
- sch1 20210812..Document1 pagesch1 20210812..fgvgjhNo ratings yet
- ERC160160-2 InterfacingDocument1 pageERC160160-2 InterfacingWagner SilvaNo ratings yet
- 13cm FM ATV Platinum ReceiverDocument1 page13cm FM ATV Platinum ReceiverK. RAJA SEKARNo ratings yet
- EE316 ReceiverDocument1 pageEE316 ReceiverŞamil ŞirinNo ratings yet
- VF2F2B Schematic PrintsDocument1 pageVF2F2B Schematic PrintsAndersonNo ratings yet
- TI-7 SchematicsDocument4 pagesTI-7 SchematicsdddieguezdNo ratings yet
- Power Card SCHDocument1 pagePower Card SCHashfaqNo ratings yet
- Catalex-Micro-SD-Card-Module-SCH ModificadoDocument1 pageCatalex-Micro-SD-Card-Module-SCH ModificadoBabobrillNo ratings yet
- RF UI BOARD & POWER INTERFACE Rev 1Document1 pageRF UI BOARD & POWER INTERFACE Rev 1宛俊No ratings yet
- Eva EsquematicoDocument22 pagesEva EsquematicoLuis MaitaNo ratings yet
- Power Management Ic: Package: 16-Bump WLCSP, 4x4 Array, 1.73mmx1.73mmDocument12 pagesPower Management Ic: Package: 16-Bump WLCSP, 4x4 Array, 1.73mmx1.73mmSebastian IgnacioNo ratings yet
- XBee USB Adapter SchematicDocument1 pageXBee USB Adapter SchematicRody Garay100% (2)
- Schematic - X-LM 723 AKIM VE VOLTAJ AYARLI GÜÇ KAYNAĞI - 2024-01-01Document1 pageSchematic - X-LM 723 AKIM VE VOLTAJ AYARLI GÜÇ KAYNAĞI - 2024-01-01brunonogueira33No ratings yet
- Advance Communication Laboratory Experiments: Prepared, Edited byDocument5 pagesAdvance Communication Laboratory Experiments: Prepared, Edited byEloisa VictorioNo ratings yet
- Lichee Nano 8.16 (Schematic)Document1 pageLichee Nano 8.16 (Schematic)NikolayVinnikNo ratings yet
- Arducam Mega Getting Started GuideDocument10 pagesArducam Mega Getting Started GuideaabejaroNo ratings yet
- Reflow Control Board PDFDocument1 pageReflow Control Board PDFRafael Ruiz CabreraNo ratings yet
- Smart Meter ConnectionDocument1 pageSmart Meter ConnectionSaldz SetariosNo ratings yet
- MT6572 SchematicDocument19 pagesMT6572 SchematicdomisoftNo ratings yet
- Wireless Shell Reference Hardware DesignDocument1 pageWireless Shell Reference Hardware DesignBrentNo ratings yet
- I2c Moist SensorDocument1 pageI2c Moist SensormicNo ratings yet
- Aae1 s1s LinkDocument14 pagesAae1 s1s LinkHisham GemanNo ratings yet
- Notes: 6.302 Feedback SystemsDocument5 pagesNotes: 6.302 Feedback SystemsTwinkle RatnaNo ratings yet
- 19 Exercise IEC61850 E SWDocument21 pages19 Exercise IEC61850 E SWlephuonganh_2001No ratings yet
- Arduino Stepper Motor ControlDocument1 pageArduino Stepper Motor ControlLivake BukNo ratings yet
- Interfacing ER-TFT028-4 With Capacitive Touch Panel To MCU STC12LE5A60S2Document1 pageInterfacing ER-TFT028-4 With Capacitive Touch Panel To MCU STC12LE5A60S2asdfghjNo ratings yet
- Appendix 6 TemplateDocument30 pagesAppendix 6 TemplateCakasana AlifNo ratings yet
- Alc Vehicle AuDocument7 pagesAlc Vehicle AuSRITECH SOLUTIONSNo ratings yet
- Esquema de ConexiónDocument1 pageEsquema de ConexiónRicardoNo ratings yet
- Elektrikal Training Set Wiring Diagram PDFDocument3 pagesElektrikal Training Set Wiring Diagram PDFO hangNo ratings yet
- TB67S128FTG Datasheet en 20201215Document49 pagesTB67S128FTG Datasheet en 20201215EdsonNo ratings yet
- RH Console Wiring Ride Control Wiring: 416F2, 422F2, 428F2 and 434F2 Electrical System Backhoe LoaderDocument4 pagesRH Console Wiring Ride Control Wiring: 416F2, 422F2, 428F2 and 434F2 Electrical System Backhoe LoaderPaul HernandezNo ratings yet
- Operation Panel Board (Basic) (PCB1) Power Pack-BCT (PCB9) : Key Card (Option)Document2 pagesOperation Panel Board (Basic) (PCB1) Power Pack-BCT (PCB9) : Key Card (Option)nickususNo ratings yet
- A17 Lighting Fan EBOPS CircuitDocument1 pageA17 Lighting Fan EBOPS CircuitEdhimj UnmeNo ratings yet
- Control HazardDocument4 pagesControl Hazard788SAURAV KUMAR SAHOONo ratings yet
- Wistron GodzillaDocument61 pagesWistron Godzillarodrigootavio5No ratings yet
- Walkie Talkie GERBERDocument1 pageWalkie Talkie GERBERAbhishek TiwariNo ratings yet
- Infrared Sensor Infrared Sensor Infrared Sensor Infrared SensorDocument1 pageInfrared Sensor Infrared Sensor Infrared Sensor Infrared SensorMohamed CharradaNo ratings yet
- BarrierGate WiringLayoutDocument1 pageBarrierGate WiringLayoutLulu ChaniagoNo ratings yet
- Modulo BootloaderDocument1 pageModulo BootloaderAbel FloresNo ratings yet
- 18 Urban Cruiser: Back-Up Light ClockDocument1 page18 Urban Cruiser: Back-Up Light ClockHEMIL ROBERTO RODRIGUEZ HERRERANo ratings yet
- Comix 35Document6 pagesComix 35oriol.berges.bergadaNo ratings yet
- Universitaet Wuppertal, Fb-Esheetmatr - Nr.Namescalesizerevcad-Technikencade (Prof - Dr.-Ing Moelle)Document1 pageUniversitaet Wuppertal, Fb-Esheetmatr - Nr.Namescalesizerevcad-Technikencade (Prof - Dr.-Ing Moelle)abdo Zinneddine100% (1)
- RTC 6705Document12 pagesRTC 6705a637888No ratings yet
- DC Single Line Diagram 01Document1 pageDC Single Line Diagram 01syedabubakars12No ratings yet
- Y301 Point To Point DiagramDocument1 pageY301 Point To Point Diagramanh thoNo ratings yet
- Schematic 12 129005Document1 pageSchematic 12 129005ALFONZO DANIELNo ratings yet
- Organisasi Sistem Komputer: OSK 11 - SuperscalarDocument28 pagesOrganisasi Sistem Komputer: OSK 11 - Superscalarفردوس سليمانNo ratings yet
- PART14Document54 pagesPART14halilkuyukNo ratings yet
- Unit 1Document17 pagesUnit 1017 Sreeja MammaiNo ratings yet
- CH16 COA9e Instruction Level Parallelism and Superscalar ProcessorsDocument20 pagesCH16 COA9e Instruction Level Parallelism and Superscalar ProcessorsTuấnNo ratings yet
- ECE 341 Final Exam Solution: Problem No. 1 (10 Points)Document9 pagesECE 341 Final Exam Solution: Problem No. 1 (10 Points)bsudheertecNo ratings yet
- Branch Hazard.: Control HazardsDocument4 pagesBranch Hazard.: Control HazardsJeya Sheeba ANo ratings yet
- The Processor: (Datapath and Pipelining)Document144 pagesThe Processor: (Datapath and Pipelining)paranoid486No ratings yet
- MatterDocument47 pagesMatterDevanand T SanthaNo ratings yet
- Advanced Computer Architecture (ACA) AssignmentDocument16 pagesAdvanced Computer Architecture (ACA) AssignmentSayed Aman KonenNo ratings yet
- Quiz For Chapter 4 With SolutionsDocument30 pagesQuiz For Chapter 4 With Solutionsorlandolanchipa100% (1)
- Computer Organzation and Architecture Question BankDocument10 pagesComputer Organzation and Architecture Question Bankmichael100% (2)
- The Processor: The Hardware/Software Interface 5Document149 pagesThe Processor: The Hardware/Software Interface 5ayylmao kekNo ratings yet
- E103.d 2020pap0015Document11 pagesE103.d 2020pap0015ATHIRA V RNo ratings yet
- Chapter 04 RISC VDocument130 pagesChapter 04 RISC VTrí ĐôNo ratings yet
- Chapter-10 Parallel Programming Models, Languages and CompilersDocument30 pagesChapter-10 Parallel Programming Models, Languages and Compilers1HK16CS104 Muntazir Hussain BhatNo ratings yet
- Coa-2-Marks-Q & ADocument30 pagesCoa-2-Marks-Q & AArup RakshitNo ratings yet
- Aca 3Document113 pagesAca 3Prateek SharmaNo ratings yet
- Chapter 04 Computer Architecture and DDocument95 pagesChapter 04 Computer Architecture and DPooja VashisthNo ratings yet
- College Data Analysis and Prediction SRSDocument68 pagesCollege Data Analysis and Prediction SRSsanjana100% (1)
- Saddam 024222000534-1194 Sec D-39thDocument14 pagesSaddam 024222000534-1194 Sec D-39thSaddam KhanNo ratings yet
- Dynamic Cache Management TechniqueDocument15 pagesDynamic Cache Management Technique185G1 Pragna KoneruNo ratings yet
- 80486Document21 pages80486Khadar Nawas0% (1)
- SonicBOOM - The 3rd Generation Berkeley Out-of-Order MachineDocument7 pagesSonicBOOM - The 3rd Generation Berkeley Out-of-Order MachineMihir SavadiNo ratings yet
- SUSHWANTH Dynamic Cache Management TechniqueDocument33 pagesSUSHWANTH Dynamic Cache Management TechniqueSunil ReddyNo ratings yet
- Vlsi Interview Questions 2Document15 pagesVlsi Interview Questions 2Ganessh Balaji100% (1)
- CS M151B / EE M116C: Computer Systems ArchitectureDocument50 pagesCS M151B / EE M116C: Computer Systems ArchitecturetinhtrilacNo ratings yet
- Chapter6 - PipeliningDocument61 pagesChapter6 - PipeliningPrakash SubramanianNo ratings yet