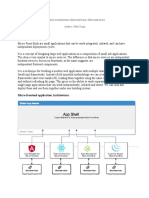
Download as pdf or txt
You might also like
- Whitepaper Micro Frontend PDFDocument6 pagesWhitepaper Micro Frontend PDFAayush TripathiNo ratings yet
- Subject: It Capstone Project: University of Education Lahore, D.G.Khan CampusDocument18 pagesSubject: It Capstone Project: University of Education Lahore, D.G.Khan CampusIT LAb 2No ratings yet
- CS111 IM Week 3Document63 pagesCS111 IM Week 3Jonel NaquitaNo ratings yet
- The Following Syllabus Will Be Covered in This Online Course of Web Design and DevelopmentDocument7 pagesThe Following Syllabus Will Be Covered in This Online Course of Web Design and Developmentpir zadaNo ratings yet
- The Extensible Markup Language (XML) : An Applied Tutorial Kevin ThomasDocument19 pagesThe Extensible Markup Language (XML) : An Applied Tutorial Kevin ThomasSoumen DebguptaNo ratings yet
- Applications of XMLDocument19 pagesApplications of XMLKoushik AkkinapalliNo ratings yet
- The Extensible Markup Language (XML) : An Applied Tutorial Kevin ThomasDocument21 pagesThe Extensible Markup Language (XML) : An Applied Tutorial Kevin ThomasvinothNo ratings yet
- It 6801 Soa QBDocument55 pagesIt 6801 Soa QBSankar JaikissanNo ratings yet
- Main Components of An XML DocumentDocument14 pagesMain Components of An XML DocumentprablpuNo ratings yet
- The Extensible Markup Language (XML)Document21 pagesThe Extensible Markup Language (XML)Manoj Kumar GNo ratings yet
- DTD and XMLDocument13 pagesDTD and XMLMurugananthan RamadossNo ratings yet
- Introduction To XML: A Universal Data FormatDocument41 pagesIntroduction To XML: A Universal Data FormatPhuong LeNo ratings yet
- XMLDocument40 pagesXMLVaishnavi ChauhanNo ratings yet
- Web Unit 2 (Nep)Document45 pagesWeb Unit 2 (Nep)Nishath AshrafNo ratings yet
- XML Stands For Extensible Markup Language.: 2. XML Is Designed To Transport and Store DataDocument62 pagesXML Stands For Extensible Markup Language.: 2. XML Is Designed To Transport and Store DataYazan AswadNo ratings yet
- DTD - Document Type DefinitionDocument30 pagesDTD - Document Type DefinitionHariniNo ratings yet
- XMLDocument7 pagesXMLGhanshyam SharmaNo ratings yet
- J2EE NotesDocument118 pagesJ2EE Notesapi-3795256100% (1)
- Chapter 5 - Introduction To XMLDocument85 pagesChapter 5 - Introduction To XMLReduan ahimuNo ratings yet
- Chapter 7: Information Representation Method - XML SolutionsDocument5 pagesChapter 7: Information Representation Method - XML SolutionsRadhaSharmaNo ratings yet
- Document Type Definition (DTD) : Well-FormedDocument12 pagesDocument Type Definition (DTD) : Well-Formedkanna karthik reddyNo ratings yet
- Integrative Programming and Technologies (Itec4121)Document59 pagesIntegrative Programming and Technologies (Itec4121)AbebeNo ratings yet
- XML HTMLDocument12 pagesXML HTMLSwapna poreddyNo ratings yet
- Document Type DefinitionDocument40 pagesDocument Type Definitionfiker123No ratings yet
- 3 XML DTD and XSLTDocument4 pages3 XML DTD and XSLTshivali.maliNo ratings yet
- W10 Lesson 8 - Document Type Definition - ModuleDocument5 pagesW10 Lesson 8 - Document Type Definition - ModuleJohn Howard GarciaNo ratings yet
- Extensible Markup LanguageDocument74 pagesExtensible Markup LanguagekalyanvsinfoNo ratings yet
- XML BasicsDocument13 pagesXML BasicsArjun DomleNo ratings yet
- XML in Unit-1Document19 pagesXML in Unit-1kollivenkatesh542No ratings yet
- TCP Lec03Document44 pagesTCP Lec03AbcNo ratings yet
- Xmlunit 2Document133 pagesXmlunit 222r11a05t5No ratings yet
- WT Unit-3 NotesDocument41 pagesWT Unit-3 NoteslavanyaNo ratings yet
- Unit 3 Working With XML Introduction To XMLDocument41 pagesUnit 3 Working With XML Introduction To XMLAishwaryaNo ratings yet
- Document Type Definition DtdsDocument38 pagesDocument Type Definition Dtdsstudentbca232No ratings yet
- Web Data: XMLDocument13 pagesWeb Data: XMLAshokNo ratings yet
- Introduction To XMLDocument49 pagesIntroduction To XMLanon_224317443No ratings yet
- Introduction To Informatics - Fall 02Document40 pagesIntroduction To Informatics - Fall 02vinothNo ratings yet
- Unit 1: Benefits of XML 1.structured DocumentDocument26 pagesUnit 1: Benefits of XML 1.structured Document923 Rishi kumar G GNo ratings yet
- XML IntroductionDocument42 pagesXML IntroductionLokesh VermaNo ratings yet
- DTD TutorialsDocument19 pagesDTD Tutorialsshaker423No ratings yet
- DTDDocument4 pagesDTDyasudharNo ratings yet
- Data Structures and Object Oriented Programming in C++: Unit-IDocument40 pagesData Structures and Object Oriented Programming in C++: Unit-IVasantha KumariNo ratings yet
- XML FaqsDocument17 pagesXML Faqsapi-3819398No ratings yet
- 7 XML 2019Document8 pages7 XML 2019ShaunNo ratings yet
- Unit 4 Question Bank Final Web TechnologyDocument12 pagesUnit 4 Question Bank Final Web TechnologyRithika M NagendiranNo ratings yet
- Subject Name: Web Engineering Subject Code: CS-7003 Semester: 7Document25 pagesSubject Name: Web Engineering Subject Code: CS-7003 Semester: 7Amit SahuNo ratings yet
- The Document Object Model Chapter 5Document28 pagesThe Document Object Model Chapter 5Kulmie ProNo ratings yet
- EletronicDocument12 pagesEletronicdiogo18spNo ratings yet
- Unit 1Document62 pagesUnit 1Harshitha BandhakaviNo ratings yet
- It6401 Soa QBDocument25 pagesIt6401 Soa QBvplvplNo ratings yet
- Document Type DefinitionDocument28 pagesDocument Type DefinitionVathsan GopalanNo ratings yet
- Unit IiDocument106 pagesUnit IiMr.V. PrabhakarNo ratings yet
- UNIT-4 Web AuthoringDocument32 pagesUNIT-4 Web Authoringbeki.ad10No ratings yet
- XML Interview Questions - JavatpointDocument8 pagesXML Interview Questions - JavatpointChandan GowdaNo ratings yet
- Unit Four Question Bank FinalDocument12 pagesUnit Four Question Bank FinalVenkataLakshmi KrishnasamyNo ratings yet
- DTD Tutorial2Document14 pagesDTD Tutorial2Subhasis MishraNo ratings yet
- XML PresentationDocument62 pagesXML PresentationAbhishek Kumar MauryaNo ratings yet
- BC0053 - (Solved) VB - Net (2012)Document10 pagesBC0053 - (Solved) VB - Net (2012)Sohel AhmedNo ratings yet
- XML Documents - Xquery XpathDocument11 pagesXML Documents - Xquery Xpathbarwin rajNo ratings yet
- XML Programming: The Ultimate Guide to Fast, Easy, and Efficient Learning of XML ProgrammingFrom EverandXML Programming: The Ultimate Guide to Fast, Easy, and Efficient Learning of XML ProgrammingRating: 2.5 out of 5 stars2.5/5 (2)
- Gyan's ResumeDocument1 pageGyan's ResumeGyan Pratap SinghNo ratings yet
- Development Security Guide Oracle FLEXCUBE Payments Release 12.3.0.0.0 (December) (2016)Document19 pagesDevelopment Security Guide Oracle FLEXCUBE Payments Release 12.3.0.0.0 (December) (2016)MulualemNo ratings yet
- Reflex User Manual: European Southern ObservatoryDocument36 pagesReflex User Manual: European Southern ObservatoryCiprian BalcanNo ratings yet
- Java Vs PHPDocument3 pagesJava Vs PHPHeadless77No ratings yet
- Unit 1 PDFDocument100 pagesUnit 1 PDFSai KrishnaNo ratings yet
- Apps ScriptDocument18 pagesApps ScriptAlaric MorganNo ratings yet
- Full Chapter Frameworkless Front End Development Do You Control Your Dependencies or Are They Controlling You Francesco Strazzullo PDFDocument64 pagesFull Chapter Frameworkless Front End Development Do You Control Your Dependencies or Are They Controlling You Francesco Strazzullo PDFkelly.brackett212No ratings yet
- 8 Tips For Writing Better Unit Tests - by Fotis Adamakis - Jun, 2023 - MediumDocument13 pages8 Tips For Writing Better Unit Tests - by Fotis Adamakis - Jun, 2023 - MediumDeepakNo ratings yet
- SerialDocument1 pageSeriallaw1595No ratings yet
- Computer CodingDocument20 pagesComputer CodingK3NN3THNo ratings yet
- Class 4Document18 pagesClass 4Javed IqbalNo ratings yet
- CS220 Midterm Spring23 - AnswersDocument9 pagesCS220 Midterm Spring23 - Answersazizkhezam9No ratings yet
- Casting: Typescript Repl in Node - JsDocument12 pagesCasting: Typescript Repl in Node - JsLuis Delascar Valencia MenaNo ratings yet
- Java 5 CH 11 MCAnswersDocument13 pagesJava 5 CH 11 MCAnswersAbigael HNo ratings yet
- Java VariablesDocument8 pagesJava VariablesDhonna IdosoraNo ratings yet
- ComprihensiveDocument39 pagesComprihensiveRabia BashirNo ratings yet
- Resume FebaDocument2 pagesResume Febafeba ferdinandNo ratings yet
- Constructor in JavaDocument6 pagesConstructor in JavaqwermnbNo ratings yet
- Rakesh VanamDocument1 pageRakesh VanamRatnesh PatelNo ratings yet
- Tip: The "Don't Repeat Yourself" (DRY) Principle Is About Reducing The Repetition of Code. YouDocument37 pagesTip: The "Don't Repeat Yourself" (DRY) Principle Is About Reducing The Repetition of Code. YouHestia HDNo ratings yet
- Highlights of Netbeans Ide 8.0 Keyboard Shortcuts & Code TemplatesDocument2 pagesHighlights of Netbeans Ide 8.0 Keyboard Shortcuts & Code TemplatesPaulo Gutierrez M.No ratings yet
- Unit 14 p1Document2 pagesUnit 14 p1api-319906681No ratings yet
- Teerthankar Mahaveer University: Database of Fantasy Cricket Game in PythonDocument32 pagesTeerthankar Mahaveer University: Database of Fantasy Cricket Game in PythonArpit SinghNo ratings yet
- Book enDocument254 pagesBook enlnwwaii1234No ratings yet
- 17CS71 Wta Mod 3 PPTDocument144 pages17CS71 Wta Mod 3 PPTVedant SinhaNo ratings yet
- Midterms - Attempt Review PDFDocument6 pagesMidterms - Attempt Review PDFkatherine anne ortizNo ratings yet