Download as pdf or txt
You might also like
- Test Bank For Cognitive Neuroscience The Biology of The Mind Fifth Edition Fifth EditionDocument36 pagesTest Bank For Cognitive Neuroscience The Biology of The Mind Fifth Edition Fifth Editionshashsilenceri0g32100% (50)
- Reimaging The Career Center - July 2017Document18 pagesReimaging The Career Center - July 2017Casey Boyles100% (1)
- Landsknecht Soldier 1486-1560 - John RichardDocument65 pagesLandsknecht Soldier 1486-1560 - John RichardKenneth Davis100% (4)
- Design of A 4-Way Passive Cross-Over Network - 0 PDFDocument100 pagesDesign of A 4-Way Passive Cross-Over Network - 0 PDFBrandy ThomasNo ratings yet
- Unit VI Parallel Programming ConceptsDocument90 pagesUnit VI Parallel Programming ConceptsPrathameshNo ratings yet
- HPC Lectures 1 5Document18 pagesHPC Lectures 1 5mohamed samyNo ratings yet
- ThreadsDocument32 pagesThreads14mervekaya01No ratings yet
- Pipelining vs. Parallel ProcessingDocument23 pagesPipelining vs. Parallel Processingkarthik1234567890No ratings yet
- Lect 02Document51 pagesLect 02dogasancak01No ratings yet
- Parallel ProgrammingDocument5 pagesParallel ProgrammingTaylor ViscainoNo ratings yet
- Introduction To Parallel Computing in R: 1 MotivationDocument6 pagesIntroduction To Parallel Computing in R: 1 MotivationRanveer RaajNo ratings yet
- Unit1 RMD PDFDocument27 pagesUnit1 RMD PDFMonikaNo ratings yet
- Parallel Database: Architecture For Parallel Databases. Parallel Query Evaluation Parallelizing Individual OperationsDocument27 pagesParallel Database: Architecture For Parallel Databases. Parallel Query Evaluation Parallelizing Individual OperationsCarNo ratings yet
- Parralel Demro 001Document45 pagesParralel Demro 001demro channelNo ratings yet
- Chapter 6 Parallel ProcessorDocument21 pagesChapter 6 Parallel Processorq qqNo ratings yet
- Lecture 09Document25 pagesLecture 09Syed BadshahNo ratings yet
- Lecture 1 Parallel DatabasesDocument30 pagesLecture 1 Parallel DatabasesKumkumo Kussia KossaNo ratings yet
- 03 - Principles of Concurrent Systems - Processes PDFDocument29 pages03 - Principles of Concurrent Systems - Processes PDFSteveFarraNo ratings yet
- 15-740/18-740 Computer Architecture Lecture 3: Performance: Carnegie Mellon UniversityDocument20 pages15-740/18-740 Computer Architecture Lecture 3: Performance: Carnegie Mellon UniversityHariNo ratings yet
- 26 Parallel AlgorithmsDocument24 pages26 Parallel Algorithmsabhijeet.pundkar2021No ratings yet
- Intro Parallel Programming 2015Document38 pagesIntro Parallel Programming 2015Ermin SehicNo ratings yet
- Parallel Computing: Overview: John Urbanic Urbanic@psc - EduDocument34 pagesParallel Computing: Overview: John Urbanic Urbanic@psc - EduanjnasharmaNo ratings yet
- Parallel ProcessingDocument31 pagesParallel ProcessingSantosh SinghNo ratings yet
- Advanced Computer Architecture 1Document14 pagesAdvanced Computer Architecture 1anilbittuNo ratings yet
- 4 Java Concurrent Patterns Advanced m4 SlidesDocument31 pages4 Java Concurrent Patterns Advanced m4 SlideskeshavjaiswalNo ratings yet
- CS3350B Computer Architecture: Marc Moreno MazaDocument45 pagesCS3350B Computer Architecture: Marc Moreno MazaAsHraf G. ElrawEi100% (1)
- Sabah SayedDocument28 pagesSabah SayedaliNo ratings yet
- Calculating Prime Numbers Comparing Java, C, and CudaDocument27 pagesCalculating Prime Numbers Comparing Java, C, and CudaKoukouNo ratings yet
- Parallel Processors From Client To Cloud: Omputer Rganization and EsignDocument43 pagesParallel Processors From Client To Cloud: Omputer Rganization and EsignPavithra JanarthananNo ratings yet
- 1.1 ParallelismDocument29 pages1.1 ParallelismVinay MishraNo ratings yet
- Tutorial No 1 (Solved)Document2 pagesTutorial No 1 (Solved)mmed68003No ratings yet
- HPCfirstlectureDocument4 pagesHPCfirstlectureJiju P NairNo ratings yet
- 05 ThreadsDocument35 pages05 ThreadskhaledhameadNo ratings yet
- FALLSEM2021-22 CSE4001 ETH VL2021220104078 Reference Material I 09-09-2021 Module-AdditionalNotesDocument51 pagesFALLSEM2021-22 CSE4001 ETH VL2021220104078 Reference Material I 09-09-2021 Module-AdditionalNotesatharva gundawarNo ratings yet
- Parallel Computing IntroductionDocument36 pagesParallel Computing IntroductionajishalfredNo ratings yet
- Pathania 2016Document5 pagesPathania 2016Mansoor GoharNo ratings yet
- Multithreading AlgorithmsDocument36 pagesMultithreading AlgorithmsAsna TariqNo ratings yet
- Parallel Fundamental ConceptsDocument15 pagesParallel Fundamental ConceptsDianaRoseAcupeadoNo ratings yet
- SpeedupDocument12 pagesSpeedupjhoshepsmithNo ratings yet
- Begin Parallel Programming With OpenMP - CodeProjectDocument8 pagesBegin Parallel Programming With OpenMP - CodeProjectManojSudarshanNo ratings yet
- Parallel Processing ReportDocument9 pagesParallel Processing ReportZaidBNo ratings yet
- Parallel ComputingDocument28 pagesParallel ComputingGica SelyNo ratings yet
- Open MPLectureDocument54 pagesOpen MPLectureShakya GauravNo ratings yet
- Multicore Expo Keynote Gatherer v2rDocument10 pagesMulticore Expo Keynote Gatherer v2rAhmedNo ratings yet
- Lec38 BWDocument45 pagesLec38 BWk12730709No ratings yet
- Project - ParallelComputing BSR v2Document40 pagesProject - ParallelComputing BSR v2api-27351105No ratings yet
- Lectures On Pipeline and Vector Processing: Unit 6Document27 pagesLectures On Pipeline and Vector Processing: Unit 6viihaanghtrivediNo ratings yet
- Introduction To Parallel Computing: National Tsing Hua University Instructor: Jerry Chou 2017, Summer SemesterDocument81 pagesIntroduction To Parallel Computing: National Tsing Hua University Instructor: Jerry Chou 2017, Summer SemesterMichael ShiNo ratings yet
- Amdahl's Law in The Multicore EraDocument6 pagesAmdahl's Law in The Multicore EraDmytro Shteflyuk100% (1)
- Introduction To Deep Learning: TA: Drew Hudson May 8, 2020Document33 pagesIntroduction To Deep Learning: TA: Drew Hudson May 8, 2020vip_thb_2007No ratings yet
- Introduction To Deep Learning: TA: Drew Hudson May 8, 2020Document33 pagesIntroduction To Deep Learning: TA: Drew Hudson May 8, 2020Sunil KumarNo ratings yet
- Jeffrey D. Ullman: Stanford UniversityDocument52 pagesJeffrey D. Ullman: Stanford Universityashwin71184No ratings yet
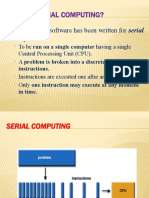
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- Distributed SystemsDocument238 pagesDistributed SystemsOTMANE ER-RAGRAGUINo ratings yet
- MySQL and Linux Tuning - Better TogetherDocument26 pagesMySQL and Linux Tuning - Better TogetherOleksiy Kovyrin100% (1)
- Sevenconcurrencymodelsinsevenweeks PreviewDocument5 pagesSevenconcurrencymodelsinsevenweeks PreviewScribNo ratings yet
- Ia Cell Unit 4Document5 pagesIa Cell Unit 4GiriDharanNo ratings yet
- 1 IntroductionDocument77 pages1 IntroductionAta Ernam (Student)No ratings yet
- L15 Cache IntroductionDocument35 pagesL15 Cache IntroductionRakshan KumarNo ratings yet
- M M M M: M M M M M MDocument28 pagesM M M M: M M M M M MAishwarya Pratap SinghNo ratings yet
- Distributed Deep Learning For Parallel TrainingDocument7 pagesDistributed Deep Learning For Parallel TrainingSibga saeed AkhtarNo ratings yet
- Build Your Own Distributed Compilation Cluster - A Practical WalkthroughFrom EverandBuild Your Own Distributed Compilation Cluster - A Practical WalkthroughNo ratings yet
- Essential Algorithms: A Practical Approach to Computer AlgorithmsFrom EverandEssential Algorithms: A Practical Approach to Computer AlgorithmsRating: 4.5 out of 5 stars4.5/5 (2)
- Hospital Management SystemDocument38 pagesHospital Management SystemSinta ApNo ratings yet
- Bid Document Volume I PKG 3Document85 pagesBid Document Volume I PKG 3J.S. RathoreNo ratings yet
- Vocab Task 1 GeneralDocument14 pagesVocab Task 1 GeneralArvinderNo ratings yet
- Answers To Typical QuestionsDocument30 pagesAnswers To Typical QuestionsErik AllenNo ratings yet
- How To Achieve Inclusive GrowthDocument901 pagesHow To Achieve Inclusive GrowthTAhmedNo ratings yet
- Case 14 Hutch Locating0001 PDFDocument8 pagesCase 14 Hutch Locating0001 PDFAshutosh SharmaNo ratings yet
- 175-Article Text-631-1-10-20210624Document9 pages175-Article Text-631-1-10-20210624Fais FaisNo ratings yet
- Procurement ProceduresDocument13 pagesProcurement ProceduresGILBERTO YOSHIDANo ratings yet
- Crochet BraceletsDocument1 pageCrochet Braceletsminervana1100% (1)
- Quadra Audio/video Entrance Panel Art. 4893M: Technical ManualDocument13 pagesQuadra Audio/video Entrance Panel Art. 4893M: Technical Manualhakera7536No ratings yet
- Pag Ibig Foreclosed Properties MAY 17Document9 pagesPag Ibig Foreclosed Properties MAY 17ramszlaiNo ratings yet
- 24 People Vs Dela Torre-YadaoDocument10 pages24 People Vs Dela Torre-YadaoKingNo ratings yet
- La Soledad National High SchoolDocument1 pageLa Soledad National High Schooleraresus EraresusNo ratings yet
- Wildlife ManagementDocument29 pagesWildlife ManagementJisan JoniNo ratings yet
- F) OO (F .: Philippine Health Insurance CorporationDocument11 pagesF) OO (F .: Philippine Health Insurance CorporationXyla Joy Araneta PerezNo ratings yet
- Advent Lessons & Carols 2019 - December 8 (Year A)Document20 pagesAdvent Lessons & Carols 2019 - December 8 (Year A)HopeNo ratings yet
- RE4 AIO ExtraPrac 1 L1Document2 pagesRE4 AIO ExtraPrac 1 L1Anonymous JsgoHdcdNo ratings yet
- Homer - The First Tragedian PDFDocument14 pagesHomer - The First Tragedian PDFbrunoNo ratings yet
- ATF Form 4 Application For Tax Paid Transfer and Registration of FirearmDocument12 pagesATF Form 4 Application For Tax Paid Transfer and Registration of FirearmAmmoLand Shooting Sports NewsNo ratings yet
- Songbook PatrioticDocument6 pagesSongbook Patrioticapi-54606121533% (3)
- SP Concare Pvt. LTD.: by Mr. Shrinivas Patil (Director)Document19 pagesSP Concare Pvt. LTD.: by Mr. Shrinivas Patil (Director)Ankita Baban GavadeNo ratings yet
- Feminist Christology and PneumatologyDocument18 pagesFeminist Christology and PneumatologyTuangpu SukteNo ratings yet
- WARNING EXPLICT LANGUAGE: Gillis Hits Suspect and Another Officer With RifleDocument6 pagesWARNING EXPLICT LANGUAGE: Gillis Hits Suspect and Another Officer With RifleLas Vegas Review-JournalNo ratings yet
- London Directory (Ing)Document64 pagesLondon Directory (Ing)Marcos F. M.No ratings yet
- Rancang Bangun Otomatisasi Irigasi: (Desain Pintu Air Dan Simulasi Sistem Kendali Level Muka Air Sawah)Document96 pagesRancang Bangun Otomatisasi Irigasi: (Desain Pintu Air Dan Simulasi Sistem Kendali Level Muka Air Sawah)Prayugo HudiansyahNo ratings yet
- Bhayu H. 349655122Document16 pagesBhayu H. 349655122Green Sustain EnergyNo ratings yet