Download as pdf or txt
You might also like
- Intermediate RDocument5 pagesIntermediate RLorensius Toto LoboNo ratings yet
- Chapter1 PDFDocument25 pagesChapter1 PDFDaniel Meza BarzenaNo ratings yet
- Pandas Complete NotesDocument105 pagesPandas Complete Notesrishiasawa02No ratings yet
- The Summarize Verb: David RobinsonDocument21 pagesThe Summarize Verb: David RobinsonDaniel Meza BarzenaNo ratings yet
- WS#3 Python Data Science Toolbox - NitroDocument6 pagesWS#3 Python Data Science Toolbox - NitroEliezer NitroNo ratings yet
- Python Data Science Toolbox: Completion 1.3 (D)Document2 pagesPython Data Science Toolbox: Completion 1.3 (D)Emely GonzagaNo ratings yet
- MONTILLA, Vince Ivan Jon S.: Python Data Science ToolboxDocument4 pagesMONTILLA, Vince Ivan Jon S.: Python Data Science ToolboxVince MontillaNo ratings yet
- TIDY Chapter3 SummarizeDocument21 pagesTIDY Chapter3 SummarizeJonathan MenachoNo ratings yet
- DWM - END SEM LAB QuestionsDocument9 pagesDWM - END SEM LAB QuestionsVV PRAVEENNo ratings yet
- Tidyr and Missing Values, Stringr, Forcats. R Markdown, Text Formatting With R Markdown, Code Chunks, YAML HeaderDocument17 pagesTidyr and Missing Values, Stringr, Forcats. R Markdown, Text Formatting With R Markdown, Code Chunks, YAML HeaderkeexuepinNo ratings yet
- GARCIA, Jason Worksheet 1.3Document5 pagesGARCIA, Jason Worksheet 1.3Jason GarciaNo ratings yet
- Chap 2Document49 pagesChap 2Malak BattahNo ratings yet
- Programs For Circular Convolution: Ivan Selesnick C. Sidney BurrusDocument3 pagesPrograms For Circular Convolution: Ivan Selesnick C. Sidney BurrusMegala ShanmugamNo ratings yet
- Research Methodology Lab FileDocument92 pagesResearch Methodology Lab FileAshwin K NNo ratings yet
- DS100Document5 pagesDS100brixter icmatNo ratings yet
- DV0101EN-2-2-1-Area-Plots-Histograms-and-Bar-Charts-py-v2.0: 1 Exploring Datasets With Pandas and MatplotlibDocument29 pagesDV0101EN-2-2-1-Area-Plots-Histograms-and-Bar-Charts-py-v2.0: 1 Exploring Datasets With Pandas and Matplotlibadityakr2410No ratings yet
- Stata DataworkDocument22 pagesStata Dataworkhasan zahidNo ratings yet
- RR - Putri-Nadia-Ningsih 21305144024 TUGAS1Document6 pagesRR - Putri-Nadia-Ningsih 21305144024 TUGAS1Putri NnnNo ratings yet
- C1M6 Peer Reviewed SolvedDocument11 pagesC1M6 Peer Reviewed SolvedAshutosh KumarNo ratings yet
- Life Expectancy Reference Spreadsheet 20090204 Xls FormatDocument428 pagesLife Expectancy Reference Spreadsheet 20090204 Xls FormatpranithNo ratings yet
- BS SRR-3Document20 pagesBS SRR-3anveshvarma365No ratings yet
- Module 1 - Comp 312 - Computer Fundamentals and Programming (Assignment)Document12 pagesModule 1 - Comp 312 - Computer Fundamentals and Programming (Assignment)diosdada mendozaNo ratings yet
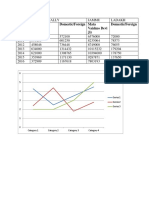
- Amaranth Ji Domestic/Foreign Mata Vaishno Devi Ji) Domestic/ForeignDocument12 pagesAmaranth Ji Domestic/Foreign Mata Vaishno Devi Ji) Domestic/ForeignMir AqibNo ratings yet
- SAS Certified SpecialilllDocument7 pagesSAS Certified SpecialillllalaNo ratings yet
- GEOP 320 Spring 2012 Lab Assignment # 2 DeconvolutionDocument1 pageGEOP 320 Spring 2012 Lab Assignment # 2 DeconvolutionMark MaoNo ratings yet
- 104 Quiz 3 SolutionsDocument7 pages104 Quiz 3 Solutionsyoyopp3366No ratings yet
- 00 - User Manual - Contents PDFDocument16 pages00 - User Manual - Contents PDFDaniel ManoliNo ratings yet
- Data Visualization Using R & Ggplot2: Karthik Ram October 6, 2013Document78 pagesData Visualization Using R & Ggplot2: Karthik Ram October 6, 2013Loraine MenorcaNo ratings yet
- Stat Features XL May 2003Document12 pagesStat Features XL May 2003nirmal kumarNo ratings yet
- Accessory Design GuidelinesDocument108 pagesAccessory Design GuidelinesMario Seekr100% (1)
- Organizing Data EDADocument20 pagesOrganizing Data EDADan PadillaNo ratings yet
- R Tools Manual NewDocument35 pagesR Tools Manual Newdinesh170900No ratings yet
- Business Analytics-1: STR (Crew - Data)Document16 pagesBusiness Analytics-1: STR (Crew - Data)Nikhil MalhotraNo ratings yet
- A Quick Introduction To Plyr: 1 Why Use Apply Functions Instead of For Loops?Document6 pagesA Quick Introduction To Plyr: 1 Why Use Apply Functions Instead of For Loops?Rose WidantiNo ratings yet
- Report Self-Balancing SkateDocument17 pagesReport Self-Balancing SkateDhruvesh PatelNo ratings yet
- W06 TutorialDocument1 pageW06 TutorialKi KiNo ratings yet
- Analysis of Algorithm: Space ComplexityDocument98 pagesAnalysis of Algorithm: Space ComplexityHadi Abdullah Khan100% (1)
- Hints and AnswersDocument13 pagesHints and Answersashishamitav123No ratings yet
- Assignment 1 ST JuneDocument7 pagesAssignment 1 ST JuneBhomesh GautamNo ratings yet
- R Introduction by Deepayan SarkarDocument23 pagesR Introduction by Deepayan SarkarSunil AravaNo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- Four Step ModelDocument8 pagesFour Step Modelnatdanai asaithammakulNo ratings yet
- Kuliah Umum Aplikasi Matematika Untuk CSDocument46 pagesKuliah Umum Aplikasi Matematika Untuk CSHunterRinaNo ratings yet
- Unit 1-Manuals: I. Vocabulary: Practice 1Document17 pagesUnit 1-Manuals: I. Vocabulary: Practice 1Thụy TrầnNo ratings yet
- Resource 5e85c2740f5e5963197435 PDFDocument133 pagesResource 5e85c2740f5e5963197435 PDFTooniNo ratings yet
- A Study of Heuristically-Based Parametric Performance Optimization Algorithms For Bigdata ComputingDocument3 pagesA Study of Heuristically-Based Parametric Performance Optimization Algorithms For Bigdata Computingtester testginNo ratings yet
- Post Midsem ProbDocument5 pagesPost Midsem Probanshumangupta183No ratings yet
- Pie Charts, Box Plots, Scatter Plots and Bubble PlotsDocument11 pagesPie Charts, Box Plots, Scatter Plots and Bubble PlotsВильсон ЛевNo ratings yet
- Types of GraphDocument40 pagesTypes of GraphvighneshmanojNo ratings yet
- ForecastingDocument12 pagesForecastingMohoua SRNo ratings yet
- Game Programming Steven Roebert IrollDocument14 pagesGame Programming Steven Roebert IrollSteve IceNo ratings yet
- Summary of Results For F - Pso: 1 Hardware SetupDocument4 pagesSummary of Results For F - Pso: 1 Hardware SetupDulal MannaNo ratings yet
- Assignment 3Document15 pagesAssignment 3Adel GharechahiNo ratings yet
- Classification and Regression Trees-3Document27 pagesClassification and Regression Trees-3Hilwin Nisa'No ratings yet
- R For EveryoneDocument48 pagesR For EveryoneHabram Miranda AlcantaraNo ratings yet
- Experiment 3 J.626Document13 pagesExperiment 3 J.626ITA426 SOHAM LENDENo ratings yet
- Chapter 9: Selection of VariablesDocument30 pagesChapter 9: Selection of VariablesMerk GetNo ratings yet
- AML5201 - LabFinal - Suhas - S - Nair - Ipynb - ColaboratoryDocument11 pagesAML5201 - LabFinal - Suhas - S - Nair - Ipynb - Colaboratorykasalasurya16No ratings yet
- Accessory Design Guidelines AppleDocument108 pagesAccessory Design Guidelines AppleMarius AndreiNo ratings yet
- Rising Bubble: Created in COMSOL Multiphysics 5.4Document12 pagesRising Bubble: Created in COMSOL Multiphysics 5.4Victoria BulychevaNo ratings yet
- Krishnas Textbook On Trigonometry (A. R. Vasishtha)Document126 pagesKrishnas Textbook On Trigonometry (A. R. Vasishtha)Ankur MishraNo ratings yet
- Software TestingDocument3 pagesSoftware TestingEnockNo ratings yet
- The Logarithmic Functions AutosavedDocument20 pagesThe Logarithmic Functions AutosavedhanaNo ratings yet
- Geostatistical SimulationDocument262 pagesGeostatistical SimulationcesarchrNo ratings yet
- Visual Basic Lecture Notes 3Document4 pagesVisual Basic Lecture Notes 3NISHIKANTA SAHOONo ratings yet
- Pertemuan 4-5. Scalable AlgorithmDocument55 pagesPertemuan 4-5. Scalable Algorithmhengky.75123014No ratings yet
- 2017 - 2005 Mathematics HSC Old SyllabusDocument79 pages2017 - 2005 Mathematics HSC Old SyllabuspinkyNo ratings yet
- 3DINVER.M: A MATLAB Program To Invert The Gravity Anomaly Over A 3D Horizontal Density Interface by Parker-Oldenburg's AlgorithmDocument8 pages3DINVER.M: A MATLAB Program To Invert The Gravity Anomaly Over A 3D Horizontal Density Interface by Parker-Oldenburg's AlgorithmlolobsNo ratings yet
- Trigonomertic Graphs SLDocument5 pagesTrigonomertic Graphs SLlolmemNo ratings yet
- Detailed Syllabus For MCA EntranceDocument3 pagesDetailed Syllabus For MCA EntranceSoumen GhoshNo ratings yet
- Discontinuous FunctionsDocument4 pagesDiscontinuous FunctionskeirolyNo ratings yet
- Course Planner: Subject Wise Syllabus PlanDocument2 pagesCourse Planner: Subject Wise Syllabus Plansoni dwivediNo ratings yet
- Mastering in Data Science 3RITPLDocument33 pagesMastering in Data Science 3RITPL091105Akanksha ghule100% (1)
- CHP 3 Image Enhancement in The Spatial Domain 1 MinDocument33 pagesCHP 3 Image Enhancement in The Spatial Domain 1 MinAbhijay Singh JainNo ratings yet
- Derivative of Algebraic FunctionDocument43 pagesDerivative of Algebraic FunctionreyiNo ratings yet
- Y1 Ebs Mathematics1Document166 pagesY1 Ebs Mathematics1Masengesho ishimwe PatienceNo ratings yet
- General Mathematics 1st Sem Mid Term ExamDocument4 pagesGeneral Mathematics 1st Sem Mid Term ExamCarye James Amrad Adelante50% (2)
- ABB 800xa System 800xa Engineering 6.0 Process GraphicsDocument740 pagesABB 800xa System 800xa Engineering 6.0 Process Graphicsman_y2k100% (2)
- Numerical DifferentiationDocument11 pagesNumerical DifferentiationtsamuelsNo ratings yet
- Exam 2020Document9 pagesExam 2020Aavesh DagarNo ratings yet
- Velammal Matriculation Higher Secondary School Computer Science Unit Test - I Class: 12std MARK: 50 I.Choose The Best Answer 10 1 10 D) ModulesDocument2 pagesVelammal Matriculation Higher Secondary School Computer Science Unit Test - I Class: 12std MARK: 50 I.Choose The Best Answer 10 1 10 D) Modulesx a m xNo ratings yet
- Discrete Functions MCR3U Unit 8 (May 2015)Document18 pagesDiscrete Functions MCR3U Unit 8 (May 2015)Shanaz ParsanNo ratings yet
- 60CA 60CB操作手冊 (英)Document106 pages60CA 60CB操作手冊 (英)taurusmaquinaschileNo ratings yet
- DLL-WK 6-LC 10,11Document13 pagesDLL-WK 6-LC 10,11Nicole TanyagNo ratings yet
- Longino - The Fate of Knowledge in Social Theories of ScienceDocument12 pagesLongino - The Fate of Knowledge in Social Theories of ScienceJuan RengifoNo ratings yet
- 22MCA344 Software Testing Module2Document311 pages22MCA344 Software Testing Module2Ashok B PNo ratings yet
- Interview QA On InformaticaDocument21 pagesInterview QA On InformaticaSubrahmanyam SudiNo ratings yet
- SSC-II Mathematics (All Sets With Solutions) - CombinedDocument47 pagesSSC-II Mathematics (All Sets With Solutions) - CombinedNaveed Haider MirzaNo ratings yet
- Assignment 1 SolutionsDocument12 pagesAssignment 1 SolutionsvbweuhvbwNo ratings yet