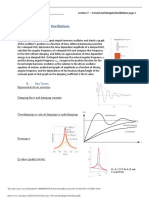
Download as pdf or txt
You might also like
- Kaizen Event CharterDocument4 pagesKaizen Event CharterManuel Dos SantosNo ratings yet
- 01 02 IntroDocument11 pages01 02 Introluomichael23No ratings yet
- L11.2 Prob Models emDocument20 pagesL11.2 Prob Models emVõ Bảo QuốcNo ratings yet
- MATHEMATICAL ECONOMICS Lecture5 15445290Document28 pagesMATHEMATICAL ECONOMICS Lecture5 15445290kyakareyarNo ratings yet
- FunctionsDocument29 pagesFunctionsmartinajoan1No ratings yet
- 2 Regression 2Document39 pages2 Regression 2MInh ThanhNo ratings yet
- 1 - Functions and Graphs - 05+Document21 pages1 - Functions and Graphs - 05+magdylouis989No ratings yet
- Falling Ball Viscometer: Abhishek Suman Department of Energy Science and Engineering IIT BombayDocument12 pagesFalling Ball Viscometer: Abhishek Suman Department of Energy Science and Engineering IIT BombayPratham sehgalNo ratings yet
- Design Optimization (ME41613) + Engineering Design Optimization (ME60079)Document13 pagesDesign Optimization (ME41613) + Engineering Design Optimization (ME60079)HarishNandanNo ratings yet
- 3 Classification 3Document49 pages3 Classification 3MInh ThanhNo ratings yet
- cs224n 2023 Lecture03 NeuralnetsDocument83 pagescs224n 2023 Lecture03 Neuralnetsmyturtle game01No ratings yet
- Lecture 12 ESO207A Expression Evaluation Using StackDocument40 pagesLecture 12 ESO207A Expression Evaluation Using StackIitianNo ratings yet
- A Quick Guide Tol Tex: What Is L Tex? Text Decorations ListsDocument2 pagesA Quick Guide Tol Tex: What Is L Tex? Text Decorations ListsSteve Jurado PinillaNo ratings yet
- 03 - ICT4Dev RegressionDocument42 pages03 - ICT4Dev RegressionHélio Januário SimangoNo ratings yet
- Unit-4 - Vector Calculus-My NotesDocument54 pagesUnit-4 - Vector Calculus-My Notesdeekshithasweety0No ratings yet
- Algorithm Design and Analysis (ADA)Document43 pagesAlgorithm Design and Analysis (ADA)Ananya JainNo ratings yet
- L23 FeatureDetectionDocument29 pagesL23 FeatureDetectiontirumareddybhavyaNo ratings yet
- 1.1 Change in TandemDocument5 pages1.1 Change in Tandemjakeya0No ratings yet
- MATLABDocument22 pagesMATLABFrancis AlmiaNo ratings yet
- Latex ShortcutsDocument3 pagesLatex Shortcutspaulbock2425No ratings yet
- Latex Cheat SheetDocument2 pagesLatex Cheat SheetSign OnnNo ratings yet
- Chapter 1-Algebra dbm10133Document54 pagesChapter 1-Algebra dbm10133Nisa Ar100% (1)
- Chapter 3 - Laplace TransformDocument57 pagesChapter 3 - Laplace TransformBukhari ManshoorNo ratings yet
- Ejemplitos de Latex: H Ector Manuel Mora Escobar Universidad Central, Bogot ADocument20 pagesEjemplitos de Latex: H Ector Manuel Mora Escobar Universidad Central, Bogot AAmanda GarciaNo ratings yet
- Module 2Document2 pagesModule 2Lorraine PeligroNo ratings yet
- Lec.2 Similarity of Fluid MachinesDocument25 pagesLec.2 Similarity of Fluid MachinesMechanical EngineeringNo ratings yet
- Lecture 7 Forced and Damped Oscillations PDFDocument3 pagesLecture 7 Forced and Damped Oscillations PDFSahaj ChhetriNo ratings yet
- 4 LinearlEquationsDocument15 pages4 LinearlEquationsSachin DhimanNo ratings yet
- ML4 Linear ModelsDocument34 pagesML4 Linear ModelsGonzalo ContrerasNo ratings yet
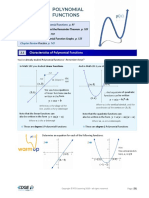
- 2.1 - Characteristics of Polynomial Functions Math 30-1Document14 pages2.1 - Characteristics of Polynomial Functions Math 30-1Math 30-1 EDGE Study Guide Workbook - by RTD LearningNo ratings yet
- MAT Lecture2Document47 pagesMAT Lecture2Deniz Egemen YılmazNo ratings yet
- 0R.8 NTH Root-Fall 2022Document11 pages0R.8 NTH Root-Fall 2022Qtrw007No ratings yet
- L TEX Basic IntroductionDocument6 pagesL TEX Basic Introductionjasdeep_kour236066No ratings yet
- Eng Math 1 Im 5Document8 pagesEng Math 1 Im 5PENDON, JORELLENo ratings yet
- Latex Cheat SheetDocument2 pagesLatex Cheat Sheetalvaro_65No ratings yet
- 3 Radicals and SurdsDocument86 pages3 Radicals and SurdsawidisasmitoNo ratings yet
- AssignmentDocument6 pagesAssignmentShareefh BashaNo ratings yet
- CH 2Document4 pagesCH 2Adnan NajemNo ratings yet
- IJAMSS - The Numerical Solutions of Multiple Integrals Based On Haar Wavelet, Blockpulse Function, Chebyshev Wavelet and Sinc FunctionDocument14 pagesIJAMSS - The Numerical Solutions of Multiple Integrals Based On Haar Wavelet, Blockpulse Function, Chebyshev Wavelet and Sinc Functioniaset123No ratings yet
- Chapter 4 - Functions-6Document109 pagesChapter 4 - Functions-6Frank WanNo ratings yet
- RegressionDocument17 pagesRegressionRenhe SONGNo ratings yet
- Modeling & Computation: Shusen WangDocument41 pagesModeling & Computation: Shusen WangMInh ThanhNo ratings yet
- BCal HandoutDocument10 pagesBCal HandoutJustin MonoyNo ratings yet
- Tareas Capitulo 12, Limites, Derivadas e Integrales de Funciones VectorialesDocument4 pagesTareas Capitulo 12, Limites, Derivadas e Integrales de Funciones VectorialesGerardo Jesús Ramos GómezNo ratings yet
- SymbolsDocument10 pagesSymbolsAgeNo ratings yet
- Relations and Functions NotesDocument181 pagesRelations and Functions NotesAsmi JohnNo ratings yet
- Module 3.3 AnnotatedDocument49 pagesModule 3.3 AnnotatedSnehaNo ratings yet
- Measure Theory and Lebesgue Integration: Joshua H. Lifton Originally Published 31 March 1999 Revised 5 September 2004Document28 pagesMeasure Theory and Lebesgue Integration: Joshua H. Lifton Originally Published 31 March 1999 Revised 5 September 2004Erdal UnluyolNo ratings yet
- Curs3site PDFDocument38 pagesCurs3site PDFGigi FloricaNo ratings yet
- Week2 DLDocument29 pagesWeek2 DLluomichael23No ratings yet
- 10 2 Guide Notes SE Simplifying RadicalsDocument3 pages10 2 Guide Notes SE Simplifying RadicalsANGELO TIQUIONo ratings yet
- Optimization Lec03 ClassicalConstrainedDocument18 pagesOptimization Lec03 ClassicalConstrainedJohn LameiNo ratings yet
- Mathematics7 Quarter1 Module5 Week5Document6 pagesMathematics7 Quarter1 Module5 Week5Gelie A. CampanillaNo ratings yet
- Implement Neural Networks Using Keras and Pytorch: Liang LiangDocument32 pagesImplement Neural Networks Using Keras and Pytorch: Liang LiangraveritaNo ratings yet
- Intro To Latex, Part Ii: Math, Bibtex, and Customization: David DiezDocument47 pagesIntro To Latex, Part Ii: Math, Bibtex, and Customization: David DiezKevin CárdenasNo ratings yet
- 5th Session MTH111-1Document12 pages5th Session MTH111-1aitchinsontimothyNo ratings yet
- LAB#2 Implementation of Constants, Variables and ExpressionsDocument6 pagesLAB#2 Implementation of Constants, Variables and ExpressionskhawarNo ratings yet
- Latex CheatsheetDocument2 pagesLatex CheatsheetVicente Mataix FerrándizNo ratings yet
- Let's Practise: Maths Workbook Coursebook 8From EverandLet's Practise: Maths Workbook Coursebook 8No ratings yet
- Math, Grade 1: Strengthening Basic Skills with Jokes, Comics, and RiddlesFrom EverandMath, Grade 1: Strengthening Basic Skills with Jokes, Comics, and RiddlesNo ratings yet
- Math, Grade 3: Strengthening Basic Skills with Jokes, Comics, and RiddlesFrom EverandMath, Grade 3: Strengthening Basic Skills with Jokes, Comics, and RiddlesNo ratings yet
- Asres Abitie Kebede Dissertation ThesisDocument249 pagesAsres Abitie Kebede Dissertation ThesisJemal TeshaleNo ratings yet
- May 2016 Computer Science Exam Paper, Paper 2 in English Time Zone 0Document15 pagesMay 2016 Computer Science Exam Paper, Paper 2 in English Time Zone 0Vidya DubeyNo ratings yet
- Week 7 Chapter 7: Guest RegistrationDocument12 pagesWeek 7 Chapter 7: Guest RegistrationechxNo ratings yet
- Introduction To IR (Student-Ver)Document18 pagesIntroduction To IR (Student-Ver)Ngọc VõNo ratings yet
- Literature Activity 1Document2 pagesLiterature Activity 1Elisha Grace JadormeoNo ratings yet
- Full Blast 2 TestsDocument3 pagesFull Blast 2 TestsСветлана ГребневаNo ratings yet
- Bending StressDocument9 pagesBending StressUjjal Kalita 19355No ratings yet
- HRMDocument2 pagesHRMHariom BhatiNo ratings yet
- Mood Disorders:: Identification and ManagementDocument45 pagesMood Disorders:: Identification and ManagementFikatu HugoronNo ratings yet
- Tap ChangerDocument6 pagesTap ChangermshahidshaukatNo ratings yet
- Impact of Leadership Styles On Employee Performance Case Study of A Non Profit Organization NGO in CambodiaDocument7 pagesImpact of Leadership Styles On Employee Performance Case Study of A Non Profit Organization NGO in CambodiaEditor IJTSRDNo ratings yet
- Canary Global Sourcing - 2023Document24 pagesCanary Global Sourcing - 2023John LongNo ratings yet
- Summer Training in Lucknow - AUTOCADDocument14 pagesSummer Training in Lucknow - AUTOCADArshit RaiNo ratings yet
- Methods of Volume StudyDocument13 pagesMethods of Volume StudyJaiminkumar SutharNo ratings yet
- Journal Pmed 1003501Document28 pagesJournal Pmed 1003501Abi HinojosaNo ratings yet
- Drivers and Approaches To The Circular Economy in ManufacturingDocument14 pagesDrivers and Approaches To The Circular Economy in ManufacturingSofia CavalcanteNo ratings yet
- RMAS An Officer and A Problem SolverDocument28 pagesRMAS An Officer and A Problem SolverSayera AkterNo ratings yet
- Manual - HSIDocument23 pagesManual - HSIrichardfloyd100% (2)
- Las Navas-Catubig-Laoang - Along The River RouteDocument2 pagesLas Navas-Catubig-Laoang - Along The River RouteChloe GalarozaNo ratings yet
- GPS Tracker Communication ProtocolDocument39 pagesGPS Tracker Communication ProtocolMuhammed EmamNo ratings yet
- Lean Six Sigma HealthcareDocument4 pagesLean Six Sigma HealthcareSusmit Jain100% (1)
- 2-Writing Numero 1Document6 pages2-Writing Numero 1Alejandra CaballeroNo ratings yet
- Chapter 4.5 SC f5Document7 pagesChapter 4.5 SC f5kwongyawNo ratings yet
- 3C Lotus Boulevard Noida, Lo....Document3 pages3C Lotus Boulevard Noida, Lo....NishimaNo ratings yet
- Purpose of ResearchDocument3 pagesPurpose of ResearchPRINTDESK by DanNo ratings yet
- Chapter 15 Part 2Document40 pagesChapter 15 Part 2omarNo ratings yet
- PZ Financial AnalysisDocument2 pagesPZ Financial Analysisdewanibipin100% (1)
- WWW TSZ Com NP 2021 09 The-Bull-Exercise-Questions-And-Answers HTMLDocument11 pagesWWW TSZ Com NP 2021 09 The-Bull-Exercise-Questions-And-Answers HTMLAbhay PantNo ratings yet
- Article LOUATIphenicienpuniqueDocument20 pagesArticle LOUATIphenicienpuniqueDabdoubidabdoubi DabdoubiNo ratings yet