
Zheng Ring Loss Convex CVPR 2018 Paper
Zheng Ring Loss Convex CVPR 2018 Paper
You might also like
- Word2Vec Tutorial - The Skip-Gram Model Chris McCormick PDFDocument39 pagesWord2Vec Tutorial - The Skip-Gram Model Chris McCormick PDFVandCasaNo ratings yet
- Solution Dseclzg524!01!102020 Ec2rDocument6 pagesSolution Dseclzg524!01!102020 Ec2rsrirams007100% (1)
- Reinforcement Car Racing With A3CDocument8 pagesReinforcement Car Racing With A3CChan LeeNo ratings yet
- Deep Learning Techniques NotesDocument42 pagesDeep Learning Techniques NotesVeera Nageswaran GNo ratings yet
- Assignment4 - AnswerKeyDocument14 pagesAssignment4 - AnswerKeyadengrayson17No ratings yet
- Lecture2 PDFDocument111 pagesLecture2 PDFdineshNo ratings yet
- Batch NormalizationDocument11 pagesBatch NormalizationAli HssanNo ratings yet
- Enthought Python Machine Learning SciKit Learn Cheat Sheets 1 3 v1.0Document3 pagesEnthought Python Machine Learning SciKit Learn Cheat Sheets 1 3 v1.0Hrishabh VashishtNo ratings yet
- RegularizationDocument38 pagesRegularizationK.P.Revathi Asst prof - IT DeptNo ratings yet
- FRM Part 1 Quants 2023 MLDocument8 pagesFRM Part 1 Quants 2023 MLIshika ParasrampuriaNo ratings yet
- Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift PDFDocument9 pagesBatch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift PDFBartoszSowulNo ratings yet
- CH 4Document41 pagesCH 4Tran Kim ToaiNo ratings yet
- CS 3035 (ML) - CS - End - May - 2023Document11 pagesCS 3035 (ML) - CS - End - May - 2023Rachit SrivastavNo ratings yet
- Estimating Output Variance of A Regressing Tree Model: Case Study of Concrete Strength PredictionDocument16 pagesEstimating Output Variance of A Regressing Tree Model: Case Study of Concrete Strength PredictionMonjurul HasanNo ratings yet
- PublishedDocument9 pagesPublishedQuyết ĐàoNo ratings yet
- 12 2 Maxima N Minima PDFDocument24 pages12 2 Maxima N Minima PDFtarek mahmoudNo ratings yet
- NIPS 2004 Parallel Support Vector Machines The Cascade SVM PaperDocument8 pagesNIPS 2004 Parallel Support Vector Machines The Cascade SVM PaperlukmanNo ratings yet
- NormDocument12 pagesNormssjjj9569No ratings yet
- Training A Binary Classifier With The Quantum Adiabatic AlgorithmDocument11 pagesTraining A Binary Classifier With The Quantum Adiabatic AlgorithmCaballero Alférez Roy TorresNo ratings yet
- L11 - RegularizationDocument25 pagesL11 - RegularizationVõ Bảo QuốcNo ratings yet
- Activation FunctionsDocument10 pagesActivation FunctionsAFFIFA JAHAN ANONNANo ratings yet
- 21-Data Clustering (K-Means Clustering Algorithm), Predictive Analytics-11!04!2023Document41 pages21-Data Clustering (K-Means Clustering Algorithm), Predictive Analytics-11!04!2023Shubham KodilkarNo ratings yet
- A Case For Public-Private Key Pairs: Sandra Arriagada and An Maria TeresaDocument7 pagesA Case For Public-Private Key Pairs: Sandra Arriagada and An Maria TeresaCarolina Ahumada GarciaNo ratings yet
- CS434a/541a: Pattern Recognition Prof. Olga VekslerDocument42 pagesCS434a/541a: Pattern Recognition Prof. Olga Vekslerabhas kumarNo ratings yet
- Lecture Week 2 KNN and Model Evaluation PDFDocument53 pagesLecture Week 2 KNN and Model Evaluation PDFHoàng Phạm100% (1)
- Teachtsp PDFDocument8 pagesTeachtsp PDFNinoska Isabel Púas MarianoNo ratings yet
- Optimisation and Optimal ControlDocument26 pagesOptimisation and Optimal ControlRadhakrishnan V KNo ratings yet
- Modeling TechniquesDocument40 pagesModeling TechniquesareejkhanNo ratings yet
- PLUM - Ordinal Regression: NotesDocument11 pagesPLUM - Ordinal Regression: NotesIanah El SholikhahNo ratings yet
- An Unbiased Approach To Low Rank RecoveryDocument28 pagesAn Unbiased Approach To Low Rank RecoveryHongqing YuNo ratings yet
- Relational DecompositionDocument13 pagesRelational Decompositionsanjayv7210No ratings yet
- Lecture 1, Part 3: Training A Classifier: Roger GrosseDocument11 pagesLecture 1, Part 3: Training A Classifier: Roger GrosseShamil shihab pkNo ratings yet
- 2015 TIP SmoothedLRRDocument9 pages2015 TIP SmoothedLRRsobiaNo ratings yet
- Question Bank 2023 Final All QuestionsDocument78 pagesQuestion Bank 2023 Final All QuestionsBinit KarmakarNo ratings yet
- Anguage Model Compression With Weighted LOW Rank FactorizationDocument15 pagesAnguage Model Compression With Weighted LOW Rank FactorizationLi DuNo ratings yet
- Lab Report #1: Transient Stability Analysis For Single Machine Infinite Bus Bar Using MATLABDocument5 pagesLab Report #1: Transient Stability Analysis For Single Machine Infinite Bus Bar Using MATLABIjaz Ahmad0% (1)
- Blind Deconvolution Using A Normalized Sparsity MeasureDocument8 pagesBlind Deconvolution Using A Normalized Sparsity MeasureRaja Ali KhanNo ratings yet
- ICDM UpliftDocument10 pagesICDM UpliftaliceecpknNo ratings yet
- Arcface: Additive Angular Margin Loss For Deep Face RecognitionDocument10 pagesArcface: Additive Angular Margin Loss For Deep Face RecognitionCẩm Tú CầuNo ratings yet
- Two-Dimensional Linear Discriminant Analysis: Jieping Ye Ravi Janardan Qi LiDocument8 pagesTwo-Dimensional Linear Discriminant Analysis: Jieping Ye Ravi Janardan Qi LiRizka FajariniNo ratings yet
- Learning Structured Low-Rank Representations For Image ClassificationDocument8 pagesLearning Structured Low-Rank Representations For Image Classificationsyed shahNo ratings yet
- Isico 2015Document22 pagesIsico 2015Rifyan AlanaNo ratings yet
- Precise Statistical Analysis of ClassificationDocument80 pagesPrecise Statistical Analysis of ClassificationGuillaume BraunNo ratings yet
- Christopher Manning Lecture 5: Language Models and Recurrent Neural Networks (Oh, and Finish Neural Dependency Parsing J)Document66 pagesChristopher Manning Lecture 5: Language Models and Recurrent Neural Networks (Oh, and Finish Neural Dependency Parsing J)Muhammad Arshad AwanNo ratings yet
- Inverse Reinforcement Learning Through Policy Gradient MinimizationDocument7 pagesInverse Reinforcement Learning Through Policy Gradient MinimizationSakazuki AkainuNo ratings yet
- Chapter 05Document32 pagesChapter 05richaNo ratings yet
- Continuous OptimizationDocument23 pagesContinuous OptimizationPrashant JindalNo ratings yet
- SciKit Cheat Sheets ALLDocument6 pagesSciKit Cheat Sheets ALLJ SalazarNo ratings yet
- Second Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions ManualDocument11 pagesSecond Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions Manualdulcitetutsanz9u100% (21)
- FrescoDocument29 pagesFrescogirishNo ratings yet
- DSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksDocument13 pagesDSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksHesham HefnyNo ratings yet
- Machine Learning Techniques Final Report (Fall, 2020) : ML - ExplorerDocument6 pagesMachine Learning Techniques Final Report (Fall, 2020) : ML - Explorer鄭百宏No ratings yet
- Procedure For Assessing The Displacement Ductility Based On Seismic Collapse Threshold and Dissipated Energy BalanceDocument1 pageProcedure For Assessing The Displacement Ductility Based On Seismic Collapse Threshold and Dissipated Energy BalanceJuan Carlos Vielma PerezNo ratings yet
- AAA - Lecture 8 - 9 Decrease and ConquerDocument34 pagesAAA - Lecture 8 - 9 Decrease and ConquerMuhammad JuniadNo ratings yet
- 12HL Note 2 Functions PDocument59 pages12HL Note 2 Functions PKedkanok SittichaiNo ratings yet
- A Transformational Approach To Teaching Matrix Structural AnalysisDocument17 pagesA Transformational Approach To Teaching Matrix Structural AnalysisTaye Oluwafemi OjoNo ratings yet
- On Controllable Sparse Alternatives To SoftmaxDocument16 pagesOn Controllable Sparse Alternatives To SoftmaxAnirban LahaNo ratings yet
- Chapter 01Document12 pagesChapter 01nikadonNo ratings yet
- 2019 Summer Model Answer Paper (Msbte Study Resources)Document27 pages2019 Summer Model Answer Paper (Msbte Study Resources)Aditya BorleNo ratings yet
- A Rank-Order Distance Based Clustering Algorithm For Face TaggingDocument8 pagesA Rank-Order Distance Based Clustering Algorithm For Face Tagging.adtmmalNo ratings yet
- Limits and Continuity (Calculus) Engineering Entrance Exams Question BankFrom EverandLimits and Continuity (Calculus) Engineering Entrance Exams Question BankNo ratings yet
- Bundle Adjustment: Optimizing Visual Data for Precise ReconstructionFrom EverandBundle Adjustment: Optimizing Visual Data for Precise ReconstructionNo ratings yet
- Programming Assignments of Deep Learning Specialization 5 Courses 1Document304 pagesProgramming Assignments of Deep Learning Specialization 5 Courses 1himanshu singhNo ratings yet
- Recurrent Neural Networks (RNNS) : A Gentle Introduction and OverviewDocument16 pagesRecurrent Neural Networks (RNNS) : A Gentle Introduction and OverviewRkeA RkeRNo ratings yet
- Model Klasifikasi Multi ClassDocument28 pagesModel Klasifikasi Multi ClassDonlot AjaNo ratings yet
- Coursera-Deep-Learning Sequence Models EmojifyDocument35 pagesCoursera-Deep-Learning Sequence Models EmojifyEMBA IITKGPNo ratings yet
- 2015-Learning Hierarchical Representation Model For Next Basket RecommendationDocument11 pages2015-Learning Hierarchical Representation Model For Next Basket RecommendationIftekhar AhmadNo ratings yet
- Presentation FYPDocument18 pagesPresentation FYPMohsinNo ratings yet
- Python Basics NympyDocument5 pagesPython Basics NympyikramNo ratings yet
- AML 03 Dense Neural NetworksDocument20 pagesAML 03 Dense Neural NetworksVaibhavNo ratings yet
- An Introduction To Deep Learning On Remote Sensing Images (Tutorial) - Mdl4eoDocument13 pagesAn Introduction To Deep Learning On Remote Sensing Images (Tutorial) - Mdl4eoshivachandraNo ratings yet
- Cosface: Large Margin Cosine Loss For Deep Face RecognitionDocument11 pagesCosface: Large Margin Cosine Loss For Deep Face RecognitionRaymon ArnoldNo ratings yet
- C2 W2 SoftMaxDocument7 pagesC2 W2 SoftMaxmr ceanNo ratings yet
- Nixon, Measuring Calibration in Deep LearningDocument14 pagesNixon, Measuring Calibration in Deep LearningJosé-Manuel Martin CoronadoNo ratings yet
- AITools Unit-4Document25 pagesAITools Unit-4SivaNo ratings yet
- BERT - Ipynb - ColaboratoryDocument6 pagesBERT - Ipynb - ColaboratorymehtakinjalbNo ratings yet
- Le Cun SupportDocument77 pagesLe Cun SupportAngéniolNo ratings yet
- Autospeech: Neural Architecture Search For Speaker RecognitionDocument5 pagesAutospeech: Neural Architecture Search For Speaker RecognitionNuman AbdullahNo ratings yet
- Improving Graph Neural Networks With Simple Architecture DesignDocument10 pagesImproving Graph Neural Networks With Simple Architecture Designhilmi bukhoriNo ratings yet
- Developers Google Com Machine Learning Crash Course Multi CLDocument5 pagesDevelopers Google Com Machine Learning Crash Course Multi CLcantahornNo ratings yet
- 2021 - Extracting Training Data From Lms GPT2 - Carlini GoogleDocument19 pages2021 - Extracting Training Data From Lms GPT2 - Carlini Googlerajesh716No ratings yet
- Character N-Gram Embeddings To Improve RNN Language Models: Sho Takase, Jun Suzuki, Masaaki NagataDocument9 pagesCharacter N-Gram Embeddings To Improve RNN Language Models: Sho Takase, Jun Suzuki, Masaaki NagataHalahManehNo ratings yet
- ML VisualsDocument61 pagesML VisualsChrisNo ratings yet
- An Explainable Model-Agnostic Algorithm For CNN-based Biometrics VerificationDocument6 pagesAn Explainable Model-Agnostic Algorithm For CNN-based Biometrics VerificationLuzNo ratings yet
- DeepMicrobes Taxonomic Classification For Metagenomics Using Deep LearningDocument13 pagesDeepMicrobes Taxonomic Classification For Metagenomics Using Deep LearningAdwikaNo ratings yet
- Advanced Materials - 2018 - Hu - Memristor Based Analog Computation and Neural Network Classification With A Dot ProductDocument10 pagesAdvanced Materials - 2018 - Hu - Memristor Based Analog Computation and Neural Network Classification With A Dot ProductDiptanu DebnathNo ratings yet
- Spell Correction For Azerbaijani Language Using Deep Neural NetworksDocument5 pagesSpell Correction For Azerbaijani Language Using Deep Neural NetworksAnmol SinhaNo ratings yet
- Presentation 1Document14 pagesPresentation 1MeghaNo ratings yet
- SoftMax ASAP2020 June14Document9 pagesSoftMax ASAP2020 June14amanNo ratings yet


































































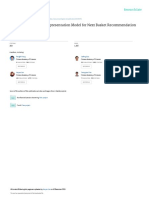

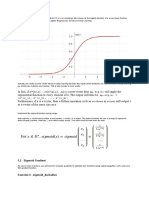




















Download as pdf or txt
You might also like
- Word2Vec Tutorial - The Skip-Gram Model Chris McCormick PDFDocument39 pagesWord2Vec Tutorial - The Skip-Gram Model Chris McCormick PDFVandCasaNo ratings yet
- Solution Dseclzg524!01!102020 Ec2rDocument6 pagesSolution Dseclzg524!01!102020 Ec2rsrirams007100% (1)
- Reinforcement Car Racing With A3CDocument8 pagesReinforcement Car Racing With A3CChan LeeNo ratings yet
- Deep Learning Techniques NotesDocument42 pagesDeep Learning Techniques NotesVeera Nageswaran GNo ratings yet
- Assignment4 - AnswerKeyDocument14 pagesAssignment4 - AnswerKeyadengrayson17No ratings yet
- Lecture2 PDFDocument111 pagesLecture2 PDFdineshNo ratings yet
- Batch NormalizationDocument11 pagesBatch NormalizationAli HssanNo ratings yet
- Enthought Python Machine Learning SciKit Learn Cheat Sheets 1 3 v1.0Document3 pagesEnthought Python Machine Learning SciKit Learn Cheat Sheets 1 3 v1.0Hrishabh VashishtNo ratings yet
- RegularizationDocument38 pagesRegularizationK.P.Revathi Asst prof - IT DeptNo ratings yet
- FRM Part 1 Quants 2023 MLDocument8 pagesFRM Part 1 Quants 2023 MLIshika ParasrampuriaNo ratings yet
- Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift PDFDocument9 pagesBatch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift PDFBartoszSowulNo ratings yet
- CH 4Document41 pagesCH 4Tran Kim ToaiNo ratings yet
- CS 3035 (ML) - CS - End - May - 2023Document11 pagesCS 3035 (ML) - CS - End - May - 2023Rachit SrivastavNo ratings yet
- Estimating Output Variance of A Regressing Tree Model: Case Study of Concrete Strength PredictionDocument16 pagesEstimating Output Variance of A Regressing Tree Model: Case Study of Concrete Strength PredictionMonjurul HasanNo ratings yet
- PublishedDocument9 pagesPublishedQuyết ĐàoNo ratings yet
- 12 2 Maxima N Minima PDFDocument24 pages12 2 Maxima N Minima PDFtarek mahmoudNo ratings yet
- NIPS 2004 Parallel Support Vector Machines The Cascade SVM PaperDocument8 pagesNIPS 2004 Parallel Support Vector Machines The Cascade SVM PaperlukmanNo ratings yet
- NormDocument12 pagesNormssjjj9569No ratings yet
- Training A Binary Classifier With The Quantum Adiabatic AlgorithmDocument11 pagesTraining A Binary Classifier With The Quantum Adiabatic AlgorithmCaballero Alférez Roy TorresNo ratings yet
- L11 - RegularizationDocument25 pagesL11 - RegularizationVõ Bảo QuốcNo ratings yet
- Activation FunctionsDocument10 pagesActivation FunctionsAFFIFA JAHAN ANONNANo ratings yet
- 21-Data Clustering (K-Means Clustering Algorithm), Predictive Analytics-11!04!2023Document41 pages21-Data Clustering (K-Means Clustering Algorithm), Predictive Analytics-11!04!2023Shubham KodilkarNo ratings yet
- A Case For Public-Private Key Pairs: Sandra Arriagada and An Maria TeresaDocument7 pagesA Case For Public-Private Key Pairs: Sandra Arriagada and An Maria TeresaCarolina Ahumada GarciaNo ratings yet
- CS434a/541a: Pattern Recognition Prof. Olga VekslerDocument42 pagesCS434a/541a: Pattern Recognition Prof. Olga Vekslerabhas kumarNo ratings yet
- Lecture Week 2 KNN and Model Evaluation PDFDocument53 pagesLecture Week 2 KNN and Model Evaluation PDFHoàng Phạm100% (1)
- Teachtsp PDFDocument8 pagesTeachtsp PDFNinoska Isabel Púas MarianoNo ratings yet
- Optimisation and Optimal ControlDocument26 pagesOptimisation and Optimal ControlRadhakrishnan V KNo ratings yet
- Modeling TechniquesDocument40 pagesModeling TechniquesareejkhanNo ratings yet
- PLUM - Ordinal Regression: NotesDocument11 pagesPLUM - Ordinal Regression: NotesIanah El SholikhahNo ratings yet
- An Unbiased Approach To Low Rank RecoveryDocument28 pagesAn Unbiased Approach To Low Rank RecoveryHongqing YuNo ratings yet
- Relational DecompositionDocument13 pagesRelational Decompositionsanjayv7210No ratings yet
- Lecture 1, Part 3: Training A Classifier: Roger GrosseDocument11 pagesLecture 1, Part 3: Training A Classifier: Roger GrosseShamil shihab pkNo ratings yet
- 2015 TIP SmoothedLRRDocument9 pages2015 TIP SmoothedLRRsobiaNo ratings yet
- Question Bank 2023 Final All QuestionsDocument78 pagesQuestion Bank 2023 Final All QuestionsBinit KarmakarNo ratings yet
- Anguage Model Compression With Weighted LOW Rank FactorizationDocument15 pagesAnguage Model Compression With Weighted LOW Rank FactorizationLi DuNo ratings yet
- Lab Report #1: Transient Stability Analysis For Single Machine Infinite Bus Bar Using MATLABDocument5 pagesLab Report #1: Transient Stability Analysis For Single Machine Infinite Bus Bar Using MATLABIjaz Ahmad0% (1)
- Blind Deconvolution Using A Normalized Sparsity MeasureDocument8 pagesBlind Deconvolution Using A Normalized Sparsity MeasureRaja Ali KhanNo ratings yet
- ICDM UpliftDocument10 pagesICDM UpliftaliceecpknNo ratings yet
- Arcface: Additive Angular Margin Loss For Deep Face RecognitionDocument10 pagesArcface: Additive Angular Margin Loss For Deep Face RecognitionCẩm Tú CầuNo ratings yet
- Two-Dimensional Linear Discriminant Analysis: Jieping Ye Ravi Janardan Qi LiDocument8 pagesTwo-Dimensional Linear Discriminant Analysis: Jieping Ye Ravi Janardan Qi LiRizka FajariniNo ratings yet
- Learning Structured Low-Rank Representations For Image ClassificationDocument8 pagesLearning Structured Low-Rank Representations For Image Classificationsyed shahNo ratings yet
- Isico 2015Document22 pagesIsico 2015Rifyan AlanaNo ratings yet
- Precise Statistical Analysis of ClassificationDocument80 pagesPrecise Statistical Analysis of ClassificationGuillaume BraunNo ratings yet
- Christopher Manning Lecture 5: Language Models and Recurrent Neural Networks (Oh, and Finish Neural Dependency Parsing J)Document66 pagesChristopher Manning Lecture 5: Language Models and Recurrent Neural Networks (Oh, and Finish Neural Dependency Parsing J)Muhammad Arshad AwanNo ratings yet
- Inverse Reinforcement Learning Through Policy Gradient MinimizationDocument7 pagesInverse Reinforcement Learning Through Policy Gradient MinimizationSakazuki AkainuNo ratings yet
- Chapter 05Document32 pagesChapter 05richaNo ratings yet
- Continuous OptimizationDocument23 pagesContinuous OptimizationPrashant JindalNo ratings yet
- SciKit Cheat Sheets ALLDocument6 pagesSciKit Cheat Sheets ALLJ SalazarNo ratings yet
- Second Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions ManualDocument11 pagesSecond Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions Manualdulcitetutsanz9u100% (21)
- FrescoDocument29 pagesFrescogirishNo ratings yet
- DSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksDocument13 pagesDSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksHesham HefnyNo ratings yet
- Machine Learning Techniques Final Report (Fall, 2020) : ML - ExplorerDocument6 pagesMachine Learning Techniques Final Report (Fall, 2020) : ML - Explorer鄭百宏No ratings yet
- Procedure For Assessing The Displacement Ductility Based On Seismic Collapse Threshold and Dissipated Energy BalanceDocument1 pageProcedure For Assessing The Displacement Ductility Based On Seismic Collapse Threshold and Dissipated Energy BalanceJuan Carlos Vielma PerezNo ratings yet
- AAA - Lecture 8 - 9 Decrease and ConquerDocument34 pagesAAA - Lecture 8 - 9 Decrease and ConquerMuhammad JuniadNo ratings yet
- 12HL Note 2 Functions PDocument59 pages12HL Note 2 Functions PKedkanok SittichaiNo ratings yet
- A Transformational Approach To Teaching Matrix Structural AnalysisDocument17 pagesA Transformational Approach To Teaching Matrix Structural AnalysisTaye Oluwafemi OjoNo ratings yet
- On Controllable Sparse Alternatives To SoftmaxDocument16 pagesOn Controllable Sparse Alternatives To SoftmaxAnirban LahaNo ratings yet
- Chapter 01Document12 pagesChapter 01nikadonNo ratings yet
- 2019 Summer Model Answer Paper (Msbte Study Resources)Document27 pages2019 Summer Model Answer Paper (Msbte Study Resources)Aditya BorleNo ratings yet
- A Rank-Order Distance Based Clustering Algorithm For Face TaggingDocument8 pagesA Rank-Order Distance Based Clustering Algorithm For Face Tagging.adtmmalNo ratings yet
- Limits and Continuity (Calculus) Engineering Entrance Exams Question BankFrom EverandLimits and Continuity (Calculus) Engineering Entrance Exams Question BankNo ratings yet
- Bundle Adjustment: Optimizing Visual Data for Precise ReconstructionFrom EverandBundle Adjustment: Optimizing Visual Data for Precise ReconstructionNo ratings yet
- Programming Assignments of Deep Learning Specialization 5 Courses 1Document304 pagesProgramming Assignments of Deep Learning Specialization 5 Courses 1himanshu singhNo ratings yet
- Recurrent Neural Networks (RNNS) : A Gentle Introduction and OverviewDocument16 pagesRecurrent Neural Networks (RNNS) : A Gentle Introduction and OverviewRkeA RkeRNo ratings yet
- Model Klasifikasi Multi ClassDocument28 pagesModel Klasifikasi Multi ClassDonlot AjaNo ratings yet
- Coursera-Deep-Learning Sequence Models EmojifyDocument35 pagesCoursera-Deep-Learning Sequence Models EmojifyEMBA IITKGPNo ratings yet
- 2015-Learning Hierarchical Representation Model For Next Basket RecommendationDocument11 pages2015-Learning Hierarchical Representation Model For Next Basket RecommendationIftekhar AhmadNo ratings yet
- Presentation FYPDocument18 pagesPresentation FYPMohsinNo ratings yet
- Python Basics NympyDocument5 pagesPython Basics NympyikramNo ratings yet
- AML 03 Dense Neural NetworksDocument20 pagesAML 03 Dense Neural NetworksVaibhavNo ratings yet
- An Introduction To Deep Learning On Remote Sensing Images (Tutorial) - Mdl4eoDocument13 pagesAn Introduction To Deep Learning On Remote Sensing Images (Tutorial) - Mdl4eoshivachandraNo ratings yet
- Cosface: Large Margin Cosine Loss For Deep Face RecognitionDocument11 pagesCosface: Large Margin Cosine Loss For Deep Face RecognitionRaymon ArnoldNo ratings yet
- C2 W2 SoftMaxDocument7 pagesC2 W2 SoftMaxmr ceanNo ratings yet
- Nixon, Measuring Calibration in Deep LearningDocument14 pagesNixon, Measuring Calibration in Deep LearningJosé-Manuel Martin CoronadoNo ratings yet
- AITools Unit-4Document25 pagesAITools Unit-4SivaNo ratings yet
- BERT - Ipynb - ColaboratoryDocument6 pagesBERT - Ipynb - ColaboratorymehtakinjalbNo ratings yet
- Le Cun SupportDocument77 pagesLe Cun SupportAngéniolNo ratings yet
- Autospeech: Neural Architecture Search For Speaker RecognitionDocument5 pagesAutospeech: Neural Architecture Search For Speaker RecognitionNuman AbdullahNo ratings yet
- Improving Graph Neural Networks With Simple Architecture DesignDocument10 pagesImproving Graph Neural Networks With Simple Architecture Designhilmi bukhoriNo ratings yet
- Developers Google Com Machine Learning Crash Course Multi CLDocument5 pagesDevelopers Google Com Machine Learning Crash Course Multi CLcantahornNo ratings yet
- 2021 - Extracting Training Data From Lms GPT2 - Carlini GoogleDocument19 pages2021 - Extracting Training Data From Lms GPT2 - Carlini Googlerajesh716No ratings yet
- Character N-Gram Embeddings To Improve RNN Language Models: Sho Takase, Jun Suzuki, Masaaki NagataDocument9 pagesCharacter N-Gram Embeddings To Improve RNN Language Models: Sho Takase, Jun Suzuki, Masaaki NagataHalahManehNo ratings yet
- ML VisualsDocument61 pagesML VisualsChrisNo ratings yet
- An Explainable Model-Agnostic Algorithm For CNN-based Biometrics VerificationDocument6 pagesAn Explainable Model-Agnostic Algorithm For CNN-based Biometrics VerificationLuzNo ratings yet
- DeepMicrobes Taxonomic Classification For Metagenomics Using Deep LearningDocument13 pagesDeepMicrobes Taxonomic Classification For Metagenomics Using Deep LearningAdwikaNo ratings yet
- Advanced Materials - 2018 - Hu - Memristor Based Analog Computation and Neural Network Classification With A Dot ProductDocument10 pagesAdvanced Materials - 2018 - Hu - Memristor Based Analog Computation and Neural Network Classification With A Dot ProductDiptanu DebnathNo ratings yet
- Spell Correction For Azerbaijani Language Using Deep Neural NetworksDocument5 pagesSpell Correction For Azerbaijani Language Using Deep Neural NetworksAnmol SinhaNo ratings yet
- Presentation 1Document14 pagesPresentation 1MeghaNo ratings yet
- SoftMax ASAP2020 June14Document9 pagesSoftMax ASAP2020 June14amanNo ratings yet