Download as pdf or txt
You might also like
- Dianne Auld's Excel Tips: Featuring Compensation and Benefits Formulas Third EditionFrom EverandDianne Auld's Excel Tips: Featuring Compensation and Benefits Formulas Third EditionNo ratings yet
- Lab Report 2 Group1Document7 pagesLab Report 2 Group1azamatNo ratings yet
- Tyler Wrightson - Wireless Network Security - A Beginner's Guide-McGraw-Hill Education (2012)Document369 pagesTyler Wrightson - Wireless Network Security - A Beginner's Guide-McGraw-Hill Education (2012)AnonyNo ratings yet
- Working With Files, Folders & Text Files: What You LearnDocument8 pagesWorking With Files, Folders & Text Files: What You Learnnick gomezNo ratings yet
- © Call Centre Helper: 171 Factorial #VALUE! This Will Cause Errors in Your CalculationsDocument19 pages© Call Centre Helper: 171 Factorial #VALUE! This Will Cause Errors in Your CalculationswircexdjNo ratings yet
- Data Science Unit 1Document24 pagesData Science Unit 1Hanuman JyothiNo ratings yet
- Microsoft Excel TutorialDocument12 pagesMicrosoft Excel TutorialthomasNo ratings yet
- Spearman's Rank: A Guide ToDocument4 pagesSpearman's Rank: A Guide TonugrohoNo ratings yet
- Opration Management TAMDocument5 pagesOpration Management TAMHK 'sNo ratings yet
- Mean Devition and Co-EfficiantDocument18 pagesMean Devition and Co-EfficiantAjay SahooNo ratings yet
- 0.1 Installation of R PackagesDocument10 pages0.1 Installation of R PackagesRajulNo ratings yet
- DL Lab ManualDocument40 pagesDL Lab ManualManojNo ratings yet
- Chap 10Document45 pagesChap 10Sawan AcharyNo ratings yet
- Dealing With DataDocument15 pagesDealing With DatavishnuNo ratings yet
- Who'S Error? - A Case StudyDocument5 pagesWho'S Error? - A Case Studyavik124No ratings yet
- Hot, Red, Large 100°, 10 Meters, 3.46 GramsDocument12 pagesHot, Red, Large 100°, 10 Meters, 3.46 GramsncvpsCRNo ratings yet
- IT Grade - WikipediaDocument2 pagesIT Grade - WikipediaVratislav Němec ml.No ratings yet
- WRITING TASK 1 - BOOK 1 (Charts With Trends)Document109 pagesWRITING TASK 1 - BOOK 1 (Charts With Trends)Nguyen Thi Tu TranNo ratings yet
- Chapter: Measures of Central Tendency: ObjectivesDocument26 pagesChapter: Measures of Central Tendency: ObjectivesHasan RabyNo ratings yet
- Excel TutorialDocument26 pagesExcel Tutorialmrladoorespect46No ratings yet
- Module 8 Computing The Point Estimate of A Population MeanDocument33 pagesModule 8 Computing The Point Estimate of A Population MeanJohn Lloyd LucabanNo ratings yet
- FC601 - TORRES Rhea - Spearmans Rank Correlation Coefficient120520Document12 pagesFC601 - TORRES Rhea - Spearmans Rank Correlation Coefficient120520Rohan NairNo ratings yet
- Excel Speedometer ChartsDocument7 pagesExcel Speedometer ChartsAqeel RashNo ratings yet
- Excel Tables, Formulas & Pivot Tables: What You LearnDocument10 pagesExcel Tables, Formulas & Pivot Tables: What You Learnnick gomezNo ratings yet
- Top500 ForbesDocument44 pagesTop500 Forbeswaliya malikNo ratings yet
- Working With Arrays: What You LearnDocument9 pagesWorking With Arrays: What You Learnnick gomezNo ratings yet
- X-R Chart LabDocument7 pagesX-R Chart Labarslan shahidNo ratings yet
- Daftar Nilai Mata Kuliah Komputer: No Stambuk Nama Nilai HDR Tugas Quis Mid FinalDocument6 pagesDaftar Nilai Mata Kuliah Komputer: No Stambuk Nama Nilai HDR Tugas Quis Mid FinalDiah MhoNo ratings yet
- Supply Chain Management Strategy Planning And Operation 7th Edition Chopra Solutions Manual instant download all chapterDocument37 pagesSupply Chain Management Strategy Planning And Operation 7th Edition Chopra Solutions Manual instant download all chapternersyseywan100% (2)
- FIN+613+Handout+1 1-1 PDFDocument15 pagesFIN+613+Handout+1 1-1 PDFWenting WanNo ratings yet
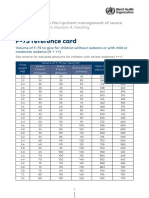
- WHO HEP NFS 21.8 EngDocument3 pagesWHO HEP NFS 21.8 EngCHRYSS FOXNo ratings yet
- Notes On Programs Tramo and Seats: 11 March 2003Document95 pagesNotes On Programs Tramo and Seats: 11 March 2003Juan SantanaNo ratings yet
- Descriptive Statistics SVDocument77 pagesDescriptive Statistics SVwexoutletbrandNo ratings yet
- Lucrare Practică Nr. 1: Statistică Matematică Asistată de CalculatorDocument5 pagesLucrare Practică Nr. 1: Statistică Matematică Asistată de CalculatorCatalin TerescencoNo ratings yet
- Practicle File of Data Warehousing and Data Mining Lab: IILM AHL College of Engineering, Gr. NoidaDocument20 pagesPracticle File of Data Warehousing and Data Mining Lab: IILM AHL College of Engineering, Gr. NoidaAyush SinghNo ratings yet
- Operational Consulting ToolsDocument7 pagesOperational Consulting ToolsSamantha HazellNo ratings yet
- DocxDocument9 pagesDocxDiscord YtNo ratings yet
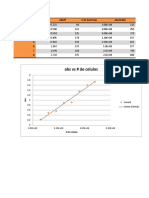
- Abs Vs # de CelulasDocument4 pagesAbs Vs # de CelulasXiadany MendozaNo ratings yet
- Relative Reference: Month Total Income Total Expense Net IncomeDocument13 pagesRelative Reference: Month Total Income Total Expense Net IncomeSrijana ShetNo ratings yet
- Fajar MuhammadDocument2 pagesFajar MuhammadYulia CandraNo ratings yet
- Variabel Independen & Dependen: Tingkat Pedapatan 55 61 67 71 76 81 88 Tingkat Konsumsi 45 48 55 61 64 69 73Document12 pagesVariabel Independen & Dependen: Tingkat Pedapatan 55 61 67 71 76 81 88 Tingkat Konsumsi 45 48 55 61 64 69 73Fajar JarfaNo ratings yet
- Agapi Mikayelyan Mechanics Lab Report 1Document7 pagesAgapi Mikayelyan Mechanics Lab Report 1Վահե ՍուքիասյանNo ratings yet
- DododoDocument10 pagesDododoHarshal LolgeNo ratings yet
- SPC TM Aiag LatestDocument67 pagesSPC TM Aiag LatestDeepak MoreNo ratings yet
- Fill in The Blank For Each of The Problems.: AnswersDocument20 pagesFill in The Blank For Each of The Problems.: AnswersmariaNo ratings yet
- DHRUV - Assignment BIOSTATISTICS (Graph)Document9 pagesDHRUV - Assignment BIOSTATISTICS (Graph)knightsoul1414No ratings yet
- The Statistical Norm or Average of A Data SetDocument2 pagesThe Statistical Norm or Average of A Data SetumangNo ratings yet
- Planning Construction MaterialsDocument37 pagesPlanning Construction MaterialsIshwor PrajapatiNo ratings yet
- ManagementDocument3 pagesManagementNo MoreNo ratings yet
- Sample DataDocument43 pagesSample DataQueenzel SaggotNo ratings yet
- Lab Slide CrankDocument8 pagesLab Slide CrankMuhd AriffNo ratings yet
- Numerical Methods For Describing Data Distributions Honors 281Document13 pagesNumerical Methods For Describing Data Distributions Honors 281Jennifer HaddonNo ratings yet
- Regression Analysis: Source SS DF MS F P-ValueDocument3 pagesRegression Analysis: Source SS DF MS F P-Valuejose rimariNo ratings yet
- Stata 10 (Time Series and Forecasting) : Journal of Statistical Software January 2008Document19 pagesStata 10 (Time Series and Forecasting) : Journal of Statistical Software January 2008Alihasen Yacob DebisoNo ratings yet
- IPE ProfiliDocument1 pageIPE ProfiliBiancorossi AleNo ratings yet
- Quantitative Techniques For Management (DBB2102)Document10 pagesQuantitative Techniques For Management (DBB2102)2004singhalvasuNo ratings yet
- Lampiran LampiranDocument9 pagesLampiran LampiranJss eeNo ratings yet
- Lecture-1: Introduction To SPSSDocument14 pagesLecture-1: Introduction To SPSSMimo BaruaNo ratings yet
- Homework 3 SolDocument3 pagesHomework 3 SolgraceNo ratings yet
- DATA SCIENCE IDC 302 End Sem ProjectDocument1 pageDATA SCIENCE IDC 302 End Sem Projectsoniakar3000No ratings yet
- Learning Management System Group 1Document37 pagesLearning Management System Group 1Rizky HarmiyantiNo ratings yet
- Ysio Max: / Product DescriptionDocument7 pagesYsio Max: / Product DescriptionZak zsNo ratings yet
- NVR (TC-R3440 Spec-I-B-N-H-C) SPECDocument3 pagesNVR (TC-R3440 Spec-I-B-N-H-C) SPECchard xuNo ratings yet
- Module - 1 NotesDocument18 pagesModule - 1 NotesAnkith S RaoNo ratings yet
- Multidiagnost Eleva: Preferred Room LayoutDocument3 pagesMultidiagnost Eleva: Preferred Room LayoutlorisaszigiNo ratings yet
- 1602-18-737-071 ES&IOT Lab 1 - MergedDocument139 pages1602-18-737-071 ES&IOT Lab 1 - Mergedcity cyberNo ratings yet
- KJHGDDocument3 pagesKJHGDgav oviNo ratings yet
- BMS 201 Identifiers, Variables and Constant 2021Document19 pagesBMS 201 Identifiers, Variables and Constant 2021Brian MutuaNo ratings yet
- Auxiliary MemoryDocument18 pagesAuxiliary MemoryRahul GoswamiNo ratings yet
- PRO1 - 03E - Simatic Manager (Compatibility Mode) (Repaired)Document1 pagePRO1 - 03E - Simatic Manager (Compatibility Mode) (Repaired)hwhhadiNo ratings yet
- Ehang Play User Toolkit ManualDocument6 pagesEhang Play User Toolkit Manualatk merasNo ratings yet
- Saveetha EngineeringDocument3 pagesSaveetha Engineeringshanjuneo17No ratings yet
- Installation Guide: Chromeleon 7 Chromatography Data SystemDocument100 pagesInstallation Guide: Chromeleon 7 Chromatography Data SystemMiguel Saucedo MoraNo ratings yet
- Design of ExperimentDocument13 pagesDesign of Experimentzaib hassanNo ratings yet
- SOP For Students (Laptop)Document28 pagesSOP For Students (Laptop)Aditya PilaniaNo ratings yet
- Mcafee Network Security Platform: Physical Appliance SpecificationsDocument9 pagesMcafee Network Security Platform: Physical Appliance SpecificationsMOKTAR BAKARNo ratings yet
- Acp-2010 2320 DS (041123) 20230412143317Document2 pagesAcp-2010 2320 DS (041123) 20230412143317Quân BùiNo ratings yet
- Computer Organisation and Architecture.Document178 pagesComputer Organisation and Architecture.AkshayAnand100% (1)
- 03-Databases MDB2023Document15 pages03-Databases MDB2023Gargi JanaNo ratings yet
- Deathlok IIIDocument7 pagesDeathlok IIIdfgdfNo ratings yet
- Smart Guide Org en Smartguide Vs Izi Travel Comparing The Best Digital Guide Audio PlatformsDocument8 pagesSmart Guide Org en Smartguide Vs Izi Travel Comparing The Best Digital Guide Audio PlatformsSmart GuideNo ratings yet
- CS101Document18 pagesCS101sibghat ullahNo ratings yet
- Brochure DynaFlexDocument4 pagesBrochure DynaFlexRikyNo ratings yet
- Sublime Text For Windows Cheat SheetDocument11 pagesSublime Text For Windows Cheat SheettrmpereiraNo ratings yet
- Flow Over AirfoilDocument22 pagesFlow Over AirfoilRahis Pal SinghNo ratings yet
- Tellabs 8660 Data SheetDocument3 pagesTellabs 8660 Data SheetkiennaNo ratings yet
- Artificial IntelligenceDocument119 pagesArtificial IntelligenceRavishankar BhaganagareNo ratings yet
- Sarmaya's Terms of ServiceDocument10 pagesSarmaya's Terms of ServiceHammad ZafarNo ratings yet
- Purchase Request: Mindanao State UniversityDocument4 pagesPurchase Request: Mindanao State UniversityMuhammad FadelNo ratings yet