Download as pdf or txt
You might also like
- Emirates CompetenancyDocument20 pagesEmirates CompetenancyAbhilash Mathew0% (1)
- Currie 1968Document8 pagesCurrie 1968AlexNo ratings yet
- Hazard. Norma Shell. Shell StandardDocument86 pagesHazard. Norma Shell. Shell Standardgustavoemir67% (3)
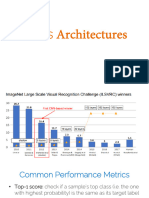
- CNN Architectures - Transfer LearningDocument64 pagesCNN Architectures - Transfer LearningBaraniNo ratings yet
- Convolutional Neural Networks: CS 535 Deep Learning, Winter 2020 Fuxin LiDocument44 pagesConvolutional Neural Networks: CS 535 Deep Learning, Winter 2020 Fuxin LisandhyaNo ratings yet
- QUESTION 2 - Convolution Neural Network Q2 A - Consider The Following CNN ArchitectureDocument2 pagesQUESTION 2 - Convolution Neural Network Q2 A - Consider The Following CNN ArchitectureMuhammad Rizwan KhalidNo ratings yet
- Pretrained Models 6Document9 pagesPretrained Models 6sama ghorabNo ratings yet
- Convolutional Neural NetworksDocument102 pagesConvolutional Neural NetworksAbdul hadiNo ratings yet
- 02 Te384 - Lecture2 - Switching SystemsDocument93 pages02 Te384 - Lecture2 - Switching Systemsmaka bojangNo ratings yet
- Convolutional Neural NetworksDocument55 pagesConvolutional Neural NetworksaliNo ratings yet
- CNN Architectures 01Document66 pagesCNN Architectures 01Abdul hadiNo ratings yet
- Wireless Communication ArchitectureDocument61 pagesWireless Communication Architectureumaranitg2188No ratings yet
- VGG16 ArchitectureDocument30 pagesVGG16 ArchitectureMehak SmaghNo ratings yet
- Final Trial MLDocument4 pagesFinal Trial MLRaghav RawatNo ratings yet
- NN 07Document24 pagesNN 07youssef husseinNo ratings yet
- Forward Error CorrectionDocument21 pagesForward Error CorrectionWasay KhanNo ratings yet
- Moblie Computing Cell StructureDocument25 pagesMoblie Computing Cell Structure2020csb062.bijayNo ratings yet
- Practice Questions CNNs SolnsDocument11 pagesPractice Questions CNNs Solnssaisivani.ashok2021No ratings yet
- SegmentationDocument34 pagesSegmentationAnishek ChaudharyNo ratings yet
- 15. AlexNetDocument20 pages15. AlexNetnericjoel2003No ratings yet
- AOD Assignment-1Document11 pagesAOD Assignment-1AbhiNo ratings yet
- Problem A. Alakazam: InputDocument24 pagesProblem A. Alakazam: InputRoberto FrancoNo ratings yet
- Gargoyle II - English.cleanDocument36 pagesGargoyle II - English.cleanWilma van der BorghtNo ratings yet
- Slides about network simplex methodDocument55 pagesSlides about network simplex methodHamza AmirNo ratings yet
- Day 13Document18 pagesDay 13studyxubuntuNo ratings yet
- Assignment 2: The North-South Highway System Passing Through Albany, New York Can Accommodate The Capacities ShownDocument4 pagesAssignment 2: The North-South Highway System Passing Through Albany, New York Can Accommodate The Capacities Shownjaydeep barodiaNo ratings yet
- Dense NetDocument28 pagesDense NetFahad RazaNo ratings yet
- Transfer Learning - Part 1Document16 pagesTransfer Learning - Part 1AditiNo ratings yet
- Dividing Polynomials Using Long DivisionDocument33 pagesDividing Polynomials Using Long DivisionReinabelle Marfil MarquezNo ratings yet
- 13. LeNetDocument39 pages13. LeNetnericjoel2003No ratings yet
- CSP NqueenDocument17 pagesCSP Nqueenরাফিদ আহমেদNo ratings yet
- CNN 22mar2017Document110 pagesCNN 22mar2017Rahul AryanNo ratings yet
- Mascara Chica OutletDocument15 pagesMascara Chica OutletCarla Lattenero100% (3)
- Lecture 3Document12 pagesLecture 3aly869556No ratings yet
- UNIT-2 Stream Ciphers and Block Ciphers: Cryptography and Network Security (3161606)Document32 pagesUNIT-2 Stream Ciphers and Block Ciphers: Cryptography and Network Security (3161606)Ganesh GhutiyaNo ratings yet
- IC - Lez4-5-6 - Convolutional NetsDocument85 pagesIC - Lez4-5-6 - Convolutional NetsJorge Iván Sepúlveda HNo ratings yet
- Class 10Document15 pagesClass 10pmukundaNo ratings yet
- Convolutional Neural Network: Sudeshna Sarkar 22/2/17, 23/2/17, 24/2/17Document120 pagesConvolutional Neural Network: Sudeshna Sarkar 22/2/17, 23/2/17, 24/2/17Sreenivasareddy DevarapalliNo ratings yet
- VHDL Implementation of A Crossbar Packet SwitchDocument1 pageVHDL Implementation of A Crossbar Packet SwitchVikas TarvechaNo ratings yet
- CNN IitkgpDocument112 pagesCNN Iitkgpamrutamhetre9No ratings yet
- Multiuser OFDM With Adaptive Subcarrier, Bit, and Power AllocationDocument17 pagesMultiuser OFDM With Adaptive Subcarrier, Bit, and Power AllocationSimon SarwarNo ratings yet
- Doris Chan - Lacy Duster OrigDocument6 pagesDoris Chan - Lacy Duster Origtritidief100% (1)
- Problem B. Bitwise Xor: InputDocument12 pagesProblem B. Bitwise Xor: Inputfirst secondNo ratings yet
- Q1. (2 Marks) Compute The Output Volume and Total Parameters For The Given CNN Which Is A Slightly Modified Version of Lenet-5Document3 pagesQ1. (2 Marks) Compute The Output Volume and Total Parameters For The Given CNN Which Is A Slightly Modified Version of Lenet-5wellhellothere123No ratings yet
- Semi Autonomous Robotics Workshop: Presented by Sonesh Kumar Bhusanam Bharat & Abhishek KumarDocument50 pagesSemi Autonomous Robotics Workshop: Presented by Sonesh Kumar Bhusanam Bharat & Abhishek KumarTechniche'11No ratings yet
- Quadratic PlacementDocument16 pagesQuadratic PlacementrvrbangNo ratings yet
- 12a Timing OptimizationDocument29 pages12a Timing OptimizationSeshareddy KatamNo ratings yet
- Convolutional CodeDocument138 pagesConvolutional CodeSarun Nellooli100% (1)
- CH2 CNSDocument33 pagesCH2 CNSSARDAR PATELNo ratings yet
- GoogleNET and ResNet v4 With Nin and BiasDocument82 pagesGoogleNET and ResNet v4 With Nin and Bias5049 Harishchandra KumarNo ratings yet
- Secret Key CryptographyDocument32 pagesSecret Key Cryptographyvidhya_bineeshNo ratings yet
- Chapters 0 and 1Document29 pagesChapters 0 and 1Tulus PramujiNo ratings yet
- Teddy Hooded BlanketDocument4 pagesTeddy Hooded BlankettheelderbugNo ratings yet
- Unit IDocument98 pagesUnit IVENU VNo ratings yet
- Intro - Channel - Coding 2023Document16 pagesIntro - Channel - Coding 2023洪邦邦No ratings yet
- W03b-Modeling With LP - 2 - 2121385217Document37 pagesW03b-Modeling With LP - 2 - 2121385217k leeNo ratings yet
- Convolutional Neural NetworksDocument79 pagesConvolutional Neural NetworksLamis AhmadNo ratings yet
- 06 - Turan - Design of Primary SystemsDocument48 pages06 - Turan - Design of Primary Systemsall ofbestNo ratings yet
- Die Manufacturing NewDocument37 pagesDie Manufacturing NewaramacataNo ratings yet
- CNN Part 2Document15 pagesCNN Part 2pragathisai0912No ratings yet
- Degree Examination in EG3576 Communications Engineering 1 Answers Candidates Must Answer All FIVE Questions. - All Questions Carry 20 MarksDocument17 pagesDegree Examination in EG3576 Communications Engineering 1 Answers Candidates Must Answer All FIVE Questions. - All Questions Carry 20 MarksNguyen Phuoc HoNo ratings yet
- Delicate Crochet: 23 Light and Pretty Designs for Shawls, Tops and MoreFrom EverandDelicate Crochet: 23 Light and Pretty Designs for Shawls, Tops and MoreRating: 4 out of 5 stars4/5 (11)
- Article Publié #2-2022 Mois 8 12Document10 pagesArticle Publié #2-2022 Mois 8 12Ahmed OULAD EL FAKIRNo ratings yet
- TEST 1 ΑΠΟ ΑΣΚΗΣΗ 1-18Document11 pagesTEST 1 ΑΠΟ ΑΣΚΗΣΗ 1-18JerryNo ratings yet
- Scientific & Technical Report: The Essential Guide To Oil Filter Performance Testing StandardsDocument5 pagesScientific & Technical Report: The Essential Guide To Oil Filter Performance Testing StandardsTamrat AssefaNo ratings yet
- E-Crm Features and E-LoyaltyDocument238 pagesE-Crm Features and E-LoyaltyDouglas Percy White R.0% (1)
- UIA 2014 Abstract BookDocument280 pagesUIA 2014 Abstract BookAmira OsmanNo ratings yet
- LPT To SPT CorrelationDocument12 pagesLPT To SPT CorrelationFelipe Vera EgañaNo ratings yet
- Endterm - 1Document14 pagesEndterm - 1himanshubahmaniNo ratings yet
- WP Horizon-Erc-2022 enDocument75 pagesWP Horizon-Erc-2022 enEirini PanouNo ratings yet
- s00431 022 04409 8Document12 pagess00431 022 04409 8Marcela SinisterraNo ratings yet
- Agenda Item 10.2 - NWFP Statistics - APCAS27Document29 pagesAgenda Item 10.2 - NWFP Statistics - APCAS27ELLEN CLAUDINE CASTRO BARRETONo ratings yet
- 11 English Core Usp 2016 2017 Set A Sa 1Document12 pages11 English Core Usp 2016 2017 Set A Sa 1monika singh100% (1)
- Module 6 - Research in ChildDocument6 pagesModule 6 - Research in Childrushy121No ratings yet
- Risk ManagementDocument23 pagesRisk ManagementMensah StephenNo ratings yet
- Chapter 5 - Content and Contextual Analysis of Selected Primary Sources in Philippine HistoryDocument12 pagesChapter 5 - Content and Contextual Analysis of Selected Primary Sources in Philippine Historygaga gagagigoNo ratings yet
- Small Business Awareness and Adoption of State of The Art Technologies in Emerging and Developing Markets and Lessons From The COVID 19 PandemicDocument19 pagesSmall Business Awareness and Adoption of State of The Art Technologies in Emerging and Developing Markets and Lessons From The COVID 19 PandemickeithNo ratings yet
- Hallam Show. Constructions of Musical AbilityDocument8 pagesHallam Show. Constructions of Musical AbilityOksana TverdokhlebovaNo ratings yet
- Research in Daily Life IIDocument12 pagesResearch in Daily Life IIVitug LemmorNo ratings yet
- Figurative Language in The Song Lyrics of Passenger's Album "All The Little Lights"Document7 pagesFigurative Language in The Song Lyrics of Passenger's Album "All The Little Lights"Alvin AnnNo ratings yet
- Neal and GriffinDocument11 pagesNeal and GriffinIietAyu05No ratings yet
- Quality Indicators For Geriatric Emergency Care: Pecial OntributionDocument9 pagesQuality Indicators For Geriatric Emergency Care: Pecial OntributionPilar Diaz VasquezNo ratings yet
- RPS Manajemen Keuangan 1 - 2021 - EngDocument13 pagesRPS Manajemen Keuangan 1 - 2021 - EngAisyah RianiNo ratings yet
- Econometric S Lecture 45Document31 pagesEconometric S Lecture 45Khurram AzizNo ratings yet
- SDLC - Ws-Commonly Asked Interview Questions With AnswersDocument4 pagesSDLC - Ws-Commonly Asked Interview Questions With Answersdhaval88No ratings yet
- Kitchen Makeup AirDocument177 pagesKitchen Makeup AirShiyamraj ThamodharanNo ratings yet
- The Study-284-294Document11 pagesThe Study-284-294Jose María CotesNo ratings yet
- PchfHazard Analysis and Risk-Based Preventive Controls For Human Food: Guidance For Industry Guidance Full 01-17-2018Document306 pagesPchfHazard Analysis and Risk-Based Preventive Controls For Human Food: Guidance For Industry Guidance Full 01-17-2018nicole_diazrNo ratings yet
- ATTENTION - Divided Attention, Selective Attention, Dichotic Listening, Stroop Effect, Filter TheoryDocument3 pagesATTENTION - Divided Attention, Selective Attention, Dichotic Listening, Stroop Effect, Filter TheoryEshaNo ratings yet