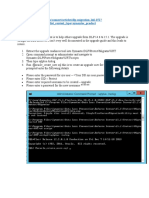
Download as pdf or txt
You might also like
- INFA Scenario Based Q N A - 16 PagesDocument16 pagesINFA Scenario Based Q N A - 16 Pageskumar.sena4633No ratings yet
- Informatica MCQDocument5 pagesInformatica MCQPayal dasNo ratings yet
- Exp4_BDI_60004200124Document11 pagesExp4_BDI_60004200124neelgabani69No ratings yet
- Bda Exp-6Document10 pagesBda Exp-6Mohit GangwaniNo ratings yet
- HiveDocument2 pagesHivescribd.unguided000No ratings yet
- Unit-5 1Document29 pagesUnit-5 1gowthami reddyNo ratings yet
- Hadoop HiveDocument61 pagesHadoop HivemustaqNo ratings yet
- WarehousingDocument100 pagesWarehousingKarthik SakaraboyinaNo ratings yet
- Introduction To HiveDocument28 pagesIntroduction To Hivefab vifNo ratings yet
- Hive - A Warehousing Solution Over A Map-Reduce FrameworkDocument4 pagesHive - A Warehousing Solution Over A Map-Reduce FrameworkSatyanarayan PatelNo ratings yet
- Unit 2 NotesDocument15 pagesUnit 2 NotessanchitghareNo ratings yet
- Unit Iv Part - 1Document60 pagesUnit Iv Part - 1Nithya NaraparajuNo ratings yet
- HIVE Data TypesDocument6 pagesHIVE Data TypesSravanthNo ratings yet
- Unit 3-1Document41 pagesUnit 3-1sahuakshat286No ratings yet
- Report On Hive of ApacheDocument3 pagesReport On Hive of ApacheGsoft LabsNo ratings yet
- SolutionsDocument3 pagesSolutionsDeepak PardhiNo ratings yet
- Hive Pig PDFDocument20 pagesHive Pig PDFKeerti CoolpadNote3LiteNo ratings yet
- Apache Hive: Prashant GuptaDocument61 pagesApache Hive: Prashant GuptaNaveen ReddyNo ratings yet
- Bda Unit 5 NotesDocument23 pagesBda Unit 5 NotesAishwarya RayasamNo ratings yet
- Ibiz HiveDocument27 pagesIbiz Hivesridr8No ratings yet
- Chapter 5 HiveDocument69 pagesChapter 5 HiveKomalNo ratings yet
- HiveDocument23 pagesHiveShantanu SharmaNo ratings yet
- BDA Cie 2 AnswersDocument15 pagesBDA Cie 2 Answersit.was.spamNo ratings yet
- SQL and Nosql Programming With SparkDocument63 pagesSQL and Nosql Programming With SparkHuy NguyễnNo ratings yet
- Hive Interview Questions AnswersDocument6 pagesHive Interview Questions AnswersrksekharNo ratings yet
- HIVE-Processing Structured Data in Hadoop: March 2017Document5 pagesHIVE-Processing Structured Data in Hadoop: March 2017ronics123No ratings yet
- DSS_U4_HIVE_rev1.1Document23 pagesDSS_U4_HIVE_rev1.1mbhavya5867No ratings yet
- HiveDocument12 pagesHivemustafaalj2002No ratings yet
- Hive Is A Data Warehouse Infrastructure Tool To Process Structured Data in HadoopDocument30 pagesHive Is A Data Warehouse Infrastructure Tool To Process Structured Data in HadooparavindNo ratings yet
- Hive2 PDFDocument8 pagesHive2 PDFRavi MistryNo ratings yet
- Unit 5 Nosql DatabasesDocument9 pagesUnit 5 Nosql Databasesrajianand2No ratings yet
- BDA Unit 2 Q&ADocument14 pagesBDA Unit 2 Q&AviswakranthipalagiriNo ratings yet
- Apache HiveDocument3 pagesApache Hivekual21No ratings yet
- 6.1NoSQL_ApacheHIVE_withA3Document45 pages6.1NoSQL_ApacheHIVE_withA3shubham agarwalNo ratings yet
- Introduction To HIVEDocument8 pagesIntroduction To HIVEKajalNo ratings yet
- Session 3.1Document29 pagesSession 3.1dhurgadeviNo ratings yet
- Experiment No 2Document9 pagesExperiment No 2Aman JainNo ratings yet
- Unit 4Document189 pagesUnit 4Rajesh Kumar RakasulaNo ratings yet
- Unit 4Document36 pagesUnit 4Radhamani VNo ratings yet
- 04 Bigdata HiveDocument22 pages04 Bigdata HiveRohit UppalNo ratings yet
- Unit 3Document75 pagesUnit 3qwNo ratings yet
- Hive Slides-2Document25 pagesHive Slides-2Somasekhar GantiNo ratings yet
- Hadoop ClusterDocument23 pagesHadoop ClusterAnoushka RaoNo ratings yet
- Data Warehousing & Analytics On Hadoop: Joydeep Sen Sarma, Ashish Thusoo Facebook Data TeamDocument19 pagesData Warehousing & Analytics On Hadoop: Joydeep Sen Sarma, Ashish Thusoo Facebook Data TeamChris HarrisNo ratings yet
- 1 &2 - The Big Data Technology Landscape MyppyDocument25 pages1 &2 - The Big Data Technology Landscape MyppyShushanth munnaNo ratings yet
- Introduction to HiveDocument8 pagesIntroduction to Hivejyotsnas99No ratings yet
- Chapter 7Document84 pagesChapter 7View PresentNo ratings yet
- u-2 P-2Document32 pagesu-2 P-2Domakonda NehaNo ratings yet
- Unit VDocument6 pagesUnit VS.GOPINATH5035No ratings yet
- HIVEDocument24 pagesHIVEIskander DenguezliNo ratings yet
- Bda 06Document15 pagesBda 06HARSH NAGNo ratings yet
- 2 HadoopDocument20 pages2 HadoopYASH PRAJAPATINo ratings yet
- Unit 5 NotesDocument66 pagesUnit 5 NotesMalathy S100% (3)
- Deepshikha Agrawal Pushp B.Sc. (IT), MBA (IT) Certification-Hadoop, Spark, Scala, Python, Tableau, ML (Assistant Professor JLBS)Document47 pagesDeepshikha Agrawal Pushp B.Sc. (IT), MBA (IT) Certification-Hadoop, Spark, Scala, Python, Tableau, ML (Assistant Professor JLBS)Ashita PunjabiNo ratings yet
- Bda Lab 1Document9 pagesBda Lab 1Mohit GangwaniNo ratings yet
- Homework 5 (25 11 2022)Document3 pagesHomework 5 (25 11 2022)Prabha KNo ratings yet
- Database Fundamental SQL ServerDocument138 pagesDatabase Fundamental SQL Serverkalyanram19858017No ratings yet
- HiveDocument65 pagesHiveApurvaNo ratings yet
- Hive: A Data Warehouse On Hadoop: On Facebook Team's PaperDocument14 pagesHive: A Data Warehouse On Hadoop: On Facebook Team's PaperVijay ReddyNo ratings yet
- Assignment Day 10: Task 1Document8 pagesAssignment Day 10: Task 1marina duttaNo ratings yet
- Dbms Lab Assignments-6Document3 pagesDbms Lab Assignments-6parveenNo ratings yet
- Microsoft SQL ServerDocument5 pagesMicrosoft SQL ServerVipul kumar JhaNo ratings yet
- DLP Upgrade 14.6 - 15.1Document12 pagesDLP Upgrade 14.6 - 15.1atiffitaNo ratings yet
- Class 12 Computer Science Practical Report Files 2022 2023Document40 pagesClass 12 Computer Science Practical Report Files 2022 2023sahil.hitesh1979No ratings yet
- Netflix Gives Users Exactly What They Want - Every Time: PersonalizationDocument2 pagesNetflix Gives Users Exactly What They Want - Every Time: Personalizationradhianie djanNo ratings yet
- QuizletDocument2 pagesQuizletakcrmNo ratings yet
- T24 MODEL BANK STBIB IntakeDocument21 pagesT24 MODEL BANK STBIB Intakepankaj aggarwalNo ratings yet
- Arcview 3.1/3.2: An OverviewDocument11 pagesArcview 3.1/3.2: An OverviewxeoxideNo ratings yet
- DataSunrise Database Security User GuideDocument445 pagesDataSunrise Database Security User Guidethameemul ansariNo ratings yet
- Oracle 23c 02Document185 pagesOracle 23c 02cpcNo ratings yet
- DBMS Lab Continuous Assessment - DBMS - Lab - Ca2 - Set-A&bDocument2 pagesDBMS Lab Continuous Assessment - DBMS - Lab - Ca2 - Set-A&bHrithikNo ratings yet
- SCC Online User GuideDocument9 pagesSCC Online User Guideraviprakash mNo ratings yet
- DBMS Course OutlineDocument14 pagesDBMS Course OutlineMohammed NouhNo ratings yet
- Electricity Bill Automation (ICT) Problem StatementDocument11 pagesElectricity Bill Automation (ICT) Problem StatementDulam TatajiNo ratings yet
- E96299-40 Oracle 19c Database Security GuideDocument1,167 pagesE96299-40 Oracle 19c Database Security GuideEdwin_KiaiNo ratings yet
- Data Analyst Chapter 2Document25 pagesData Analyst Chapter 2Andi Annisa DianputriNo ratings yet
- Product Analytics Interview Technical Evaluation Q&ADocument4 pagesProduct Analytics Interview Technical Evaluation Q&Ayjy34097No ratings yet
- Practice Set 5Document1 pagePractice Set 5Neil CuyosNo ratings yet
- Pankaj Shamrao Sawant: Software Test EngineerDocument2 pagesPankaj Shamrao Sawant: Software Test EngineervinaybhkulkarniNo ratings yet
- Exadata Database Machine: 12c Administration Workshop: Dauer 5 TageDocument2 pagesExadata Database Machine: 12c Administration Workshop: Dauer 5 TageGreene ChickaNo ratings yet
- IUCS - Leader Project ConfigurationDocument3 pagesIUCS - Leader Project Configurationabhay.shivhareNo ratings yet
- UNIT 5 Complete NotesDocument21 pagesUNIT 5 Complete Notesworks8606No ratings yet
- Data Modeling Interview QuestionsDocument2 pagesData Modeling Interview Questionsmailviraj11No ratings yet
- Document From NishadDocument46 pagesDocument From NishadPrivettt 888No ratings yet
- INDEXINGABSTRACTINGDocument103 pagesINDEXINGABSTRACTINGJeric CamayaNo ratings yet
- NDG Online NDG Linux Essentials Challenge C: Log File ArchivingDocument4 pagesNDG Online NDG Linux Essentials Challenge C: Log File ArchivingOmar Oughzal50% (2)
- ACFrOgCK8d qx6yIxOeRqfBi5-IzmTuxFV3MadZ0abymeKDqroisQWmlZDwwQPkY8jB8YEEJpIT0L95cAmqXTJdTB2JK2RoQLSSJjr2ZbwFBGlFW6kWhidXcYBqRPKJtDcnlRTNyRzqkt9J3t2nnDocument3 pagesACFrOgCK8d qx6yIxOeRqfBi5-IzmTuxFV3MadZ0abymeKDqroisQWmlZDwwQPkY8jB8YEEJpIT0L95cAmqXTJdTB2JK2RoQLSSJjr2ZbwFBGlFW6kWhidXcYBqRPKJtDcnlRTNyRzqkt9J3t2nnAbubakari SaidNo ratings yet
- How To Connect To MySQL Using PHPDocument3 pagesHow To Connect To MySQL Using PHPSsekabira DavidNo ratings yet