Download as pdf or txt
You might also like
- Lab Manual OF Big Data Analtyics Lab (Bca04207) : BCA General II Year IV Semester Academic Session 2021-22Document79 pagesLab Manual OF Big Data Analtyics Lab (Bca04207) : BCA General II Year IV Semester Academic Session 2021-22Megha GargNo ratings yet
- OR6205 M5 Practice ExamDocument3 pagesOR6205 M5 Practice ExamMohan BollaNo ratings yet
- Exp 6Document6 pagesExp 6jayNo ratings yet
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- SVM K NN MLP With Sklearn Jupyter NoteBoDocument22 pagesSVM K NN MLP With Sklearn Jupyter NoteBoAhm TharwatNo ratings yet
- Lecture 21Document138 pagesLecture 21Tev WallaceNo ratings yet
- Cau1 Rom Import From Import Import Import As Import As From ImportDocument4 pagesCau1 Rom Import From Import Import Import As Import As From ImportKenny LongNo ratings yet
- Ai Last 5Document4 pagesAi Last 5Bad BoyNo ratings yet
- ML2 Practical ListDocument80 pagesML2 Practical ListYash AminNo ratings yet
- Assignment 3Document7 pagesAssignment 3Haisam AbbasNo ratings yet
- Ml-A2 CodeDocument5 pagesMl-A2 CodeBECOC362Atharva UtekarNo ratings yet
- Experiment 7 Support Vector Machine (SVM)Document2 pagesExperiment 7 Support Vector Machine (SVM)Garam khoonNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- Deep-Learning-Keras-Tensorflow - 1.1.1 Perceptron and Adaline - Ipynb at Master Leriomaggio - Deep-Learning-Keras-TensorflowDocument11 pagesDeep-Learning-Keras-Tensorflow - 1.1.1 Perceptron and Adaline - Ipynb at Master Leriomaggio - Deep-Learning-Keras-Tensorflowme andan buscandoNo ratings yet
- Assignment No 8Document17 pagesAssignment No 8264 HAMNA AMIRNo ratings yet
- 2.3 Aiml RishitDocument7 pages2.3 Aiml Rishitheex.prosNo ratings yet
- Intro Cluster Problem PythonDocument13 pagesIntro Cluster Problem Pythongabrielrichter2021No ratings yet
- Is Lab 7Document7 pagesIs Lab 7Aman BansalNo ratings yet
- Is Lab 7Document7 pagesIs Lab 7Aman BansalNo ratings yet
- EXP 08 (ML) - ShriDocument2 pagesEXP 08 (ML) - ShriDSE 04. Chetana BhoirNo ratings yet
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- Import As Import As Import As: 'Social - Network - Ads - CSV'Document2 pagesImport As Import As Import As: 'Social - Network - Ads - CSV'lucansitumeang21No ratings yet
- Using Any Data, Apply The Concept of Logistic Regression.Document4 pagesUsing Any Data, Apply The Concept of Logistic Regression.19-361 Sai PrathikNo ratings yet
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- Home WorkDocument12 pagesHome Worksandeepssn47No ratings yet
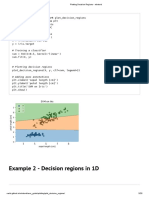
- Plotting Decision Regions - MlxtendDocument5 pagesPlotting Decision Regions - Mlxtendakhi016733No ratings yet
- Implementing Custom Randomsearchcv: 'Red' 'Blue'Document1 pageImplementing Custom Randomsearchcv: 'Red' 'Blue'Tayub khan.ANo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- Week 8. GMMDocument11 pagesWeek 8. GMMrevaldianggaraNo ratings yet
- Online Payment Fraud Detection Using Machine LearningDocument2 pagesOnline Payment Fraud Detection Using Machine LearningDev Ranjan RautNo ratings yet
- R19C076 - Chanukya Gowda K - Mlda - Assignment-2Document19 pagesR19C076 - Chanukya Gowda K - Mlda - Assignment-2Chanukya Gowda kNo ratings yet
- K-Nearest Neighbor On Python Ken OcumaDocument9 pagesK-Nearest Neighbor On Python Ken OcumaAliyha Dionio100% (2)
- Logistic - Regression - Ipynb - ColaboratoryDocument3 pagesLogistic - Regression - Ipynb - ColaboratoryAgi TasyaNo ratings yet
- Cardio Screen RFDocument27 pagesCardio Screen RFThe Mind100% (1)
- Ai ML ProgramsDocument34 pagesAi ML ProgramsYasar BilalNo ratings yet
- Az Her and TahirDocument2 pagesAz Her and Tahirsyedosmanali040No ratings yet
- P03 Confidence RegionDocument7 pagesP03 Confidence RegionYANDRAPU MANOJ NAIDU 20MDT1017No ratings yet
- DbscanDocument5 pagesDbscanMuhammad GattanNo ratings yet
- DM Slip SolutionsDocument24 pagesDM Slip Solutions09.Khadija Gharatkar100% (1)
- CodesDocument6 pagesCodesVamshi KrishnaNo ratings yet
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (2)
- Naive BayesDocument7 pagesNaive Bayesdamasodra33No ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- EigenvaluesDocument5 pagesEigenvaluesyashsonone25No ratings yet
- Naive - Bayes - Ipynb - ColabDocument3 pagesNaive - Bayes - Ipynb - ColabAgi TasyaNo ratings yet
- EE 559 HW2Code PDFDocument7 pagesEE 559 HW2Code PDFAliNo ratings yet
- Prob13: 1 EE16A Homework 13Document23 pagesProb13: 1 EE16A Homework 13Michael ARKNo ratings yet
- Big Data MergedDocument7 pagesBig Data MergedIngame IdNo ratings yet
- ML ClassificationDocument54 pagesML Classificationmgs181101No ratings yet
- ML Lab....... 3-Converted NewDocument27 pagesML Lab....... 3-Converted NewHanisha BavanaNo ratings yet
- LAB-4 ReportDocument21 pagesLAB-4 Reportjithentar.cs21No ratings yet
- 20-SE-66 ML Assign 2Document4 pages20-SE-66 ML Assign 2Muhammad Ali EjazNo ratings yet
- Nadya Faudilla - 1806198471 - Geologi Komputasi 5 Dan 6 - Jupyter NotebookDocument9 pagesNadya Faudilla - 1806198471 - Geologi Komputasi 5 Dan 6 - Jupyter NotebookEmir RakhimNo ratings yet
- ML Ex8Document2 pagesML Ex8yefigoh133No ratings yet
- AIDocument33 pagesAIJagmeet Singh LubanaNo ratings yet
- Is Lab Aman Agarwal PDFDocument8 pagesIs Lab Aman Agarwal PDFAman BansalNo ratings yet
- Lab-5 ReportDocument11 pagesLab-5 Reportjithentar.cs21No ratings yet
- CodeDocument6 pagesCodeKeerti GulatiNo ratings yet
- 7 - 201904121342. Lampiran SkripsiDocument65 pages7 - 201904121342. Lampiran SkripsiilfisyafaNo ratings yet
- SodapdfDocument1 pageSodapdfNathon MineNo ratings yet
- Advance AI and ML LABDocument16 pagesAdvance AI and ML LABPriyanka PriyaNo ratings yet
- Operations Research 1 The Two-Phase Simplex Method: Dr. Özgür KabakDocument16 pagesOperations Research 1 The Two-Phase Simplex Method: Dr. Özgür KabakAshish RanjanNo ratings yet
- Cuestionarios IADocument17 pagesCuestionarios IAManuel DomínguezNo ratings yet
- BE LP3 Q2 41239 ML MiniProjectDocument6 pagesBE LP3 Q2 41239 ML MiniProjectWow BollywoodNo ratings yet
- Blaeser Algorithms and Data StructuresDocument109 pagesBlaeser Algorithms and Data StructuresMaia OsadzeNo ratings yet
- ClosestDocument2 pagesClosestBengt HörbergNo ratings yet
- SJF Scheduling - SRTF - CPU SchedulingDocument9 pagesSJF Scheduling - SRTF - CPU SchedulingKushal Roy ChowdhuryNo ratings yet
- LPP Solution Using Simplex MethodDocument56 pagesLPP Solution Using Simplex Methodrohit4567867% (3)
- Parser FinalDocument19 pagesParser FinalsauravthehijackerNo ratings yet
- mcs-021 Assignment 21Document21 pagesmcs-021 Assignment 21jiveeNo ratings yet
- Assembly Language Assignment No 3 (BCSM-S19-055, BCSM-S19-015, BCSM - f18-079)Document7 pagesAssembly Language Assignment No 3 (BCSM-S19-055, BCSM-S19-015, BCSM - f18-079)Waqar GhafoorNo ratings yet
- CS632 Lecture 07Document50 pagesCS632 Lecture 07Muhammad AbubakarNo ratings yet
- Flight Management SystemDocument10 pagesFlight Management SystemVaishnav BhorNo ratings yet
- CS 106B Class NotesDocument14 pagesCS 106B Class NotesChengineNo ratings yet
- Or TP Optimal SolutionDocument14 pagesOr TP Optimal SolutionManas JainNo ratings yet
- 24 8 18 POR Question Bank Unit I II IIIDocument10 pages24 8 18 POR Question Bank Unit I II IIIddownload 1No ratings yet
- Shortest Path Between Two Nodes On A Potential Railway System in CyprusDocument14 pagesShortest Path Between Two Nodes On A Potential Railway System in CyprusErdogan KayganNo ratings yet
- HiiiDocument2 pagesHiiiMohd JaffarNo ratings yet
- Subject: Data Structures and Algorithms (In Java) Number of Question: 50 Multiple Choice QuestionDocument12 pagesSubject: Data Structures and Algorithms (In Java) Number of Question: 50 Multiple Choice QuestionBinh ChâuNo ratings yet
- Machine Learning Classification Bootcamp CheatsheetDocument7 pagesMachine Learning Classification Bootcamp CheatsheetNikolas MenaNo ratings yet
- Lecture4 - Indexing and Searching IDocument56 pagesLecture4 - Indexing and Searching IpriyankaprakasanNo ratings yet
- MTH601 ExamplesDocument2 pagesMTH601 ExamplesMuzammil SiddiqueNo ratings yet
- OsDocument9 pagesOsanon_48973018No ratings yet
- Operations Research Solved MCQs (Set-1)Document5 pagesOperations Research Solved MCQs (Set-1)singhnimmi478No ratings yet
- 300 Embedded Programming Problems by Yashwanth Naidu TDocument85 pages300 Embedded Programming Problems by Yashwanth Naidu TSai Krishna K VNo ratings yet
- Sir Kashif Chapter 3Document93 pagesSir Kashif Chapter 3Noman Qadir LeghariNo ratings yet
- Mean Shift ClusterDocument10 pagesMean Shift ClusterSoumyajit JagdevNo ratings yet
- 2d Pattern MatchingDocument35 pages2d Pattern MatchingHanan KasimNo ratings yet
- Decision TreeDocument12 pagesDecision TreeshrikrishnaNo ratings yet