Download as pdf or txt
You might also like
- Linear Algebra Solution Manual by Peter OlverDocument350 pagesLinear Algebra Solution Manual by Peter OlverVirna Cristina Lazo78% (9)
- Elements of Strength of Material Timoshenko Young 5th EditionDocument194 pagesElements of Strength of Material Timoshenko Young 5th EditionShipali Parjapat100% (2)
- Minitab Solutions PDFDocument116 pagesMinitab Solutions PDFGabriel Gomez100% (1)
- Application of Linear Algebra in Image ProcessingDocument16 pagesApplication of Linear Algebra in Image ProcessingRakesh SrinivasaNo ratings yet
- 4016 Mathematics Topic 1: Numbers and AlgebraDocument7 pages4016 Mathematics Topic 1: Numbers and AlgebraMohammad AshfaqNo ratings yet
- Eco 570 AssignDocument10 pagesEco 570 AssignMaryam KhanNo ratings yet
- FSMQ Pareto ChartsDocument5 pagesFSMQ Pareto ChartsTrexie PalenciaNo ratings yet
- (Spanish Edition) Fred R. David-Conceptos de Administración Estratégica-Pearson (México) (2011)Document7 pages(Spanish Edition) Fred R. David-Conceptos de Administración Estratégica-Pearson (México) (2011)JuandeLa100% (1)
- 02Document11 pages02Omar EjeddiNo ratings yet
- Sample PC Mark-Up 1Document1 pageSample PC Mark-Up 1fusionndtNo ratings yet
- Dynamique &statique - 3Document11 pagesDynamique &statique - 3simaedouaaron067No ratings yet
- Introducing SigmaXL Version 5.3bDocument83 pagesIntroducing SigmaXL Version 5.3bYusranNo ratings yet
- Piper Plot and Stiff DiagramDocument9 pagesPiper Plot and Stiff DiagramhentadwyNo ratings yet
- Chapter Five - Correlation & Regression (STA408) - 230611 - 211949Document26 pagesChapter Five - Correlation & Regression (STA408) - 230611 - 211949BadnazNo ratings yet
- 02Document11 pages02BossNo ratings yet
- BizzX News Spring06 Vol.1 (1) : Performance Is EverythingDocument6 pagesBizzX News Spring06 Vol.1 (1) : Performance Is EverythingDave LivingstonNo ratings yet
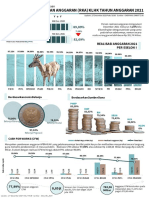
- Yqj6 - Bahan Tayang Progres Kinerja APBN TA. 2021 KLHK S.D 27 DES 2021Document2 pagesYqj6 - Bahan Tayang Progres Kinerja APBN TA. 2021 KLHK S.D 27 DES 2021Muhammad Rifki SetiawanNo ratings yet
- Angola Economic Outlook 2023Document23 pagesAngola Economic Outlook 2023Enrique GrNo ratings yet
- Statistical Quality ControlDocument40 pagesStatistical Quality ControlCancelynshrnpNo ratings yet
- Gati Case SolutionDocument3 pagesGati Case SolutionAkshaya Lakshminarasimhan100% (1)
- CREQ4CY23 India Office ReportDocument11 pagesCREQ4CY23 India Office Reportvenu4u498No ratings yet
- Behavioral Asset Allocation Revised Victoria 100921Document38 pagesBehavioral Asset Allocation Revised Victoria 100921Akanksha GuptaNo ratings yet
- Pareto Chart: Management Decisions Figure 1. Pareto GraphDocument3 pagesPareto Chart: Management Decisions Figure 1. Pareto GraphRoqaia AlwanNo ratings yet
- Ch03 Functions 3rd EdDocument60 pagesCh03 Functions 3rd EdShahril MohamadNo ratings yet
- Appointment of Cost Auditor For Financial Year 2022-23: Annexure - IDocument40 pagesAppointment of Cost Auditor For Financial Year 2022-23: Annexure - INitesh RamNo ratings yet
- Pareto Chart:: A Graph Will Automatically Build As You Enter Your Information Into The Table Below. Steps To FollowDocument10 pagesPareto Chart:: A Graph Will Automatically Build As You Enter Your Information Into The Table Below. Steps To FollowAmit R DwivediNo ratings yet
- Maintenance StrategyDocument47 pagesMaintenance Strategyapi-3732848100% (1)
- 17 Pareto Day 1Document24 pages17 Pareto Day 1m2z.marksmanNo ratings yet
- Pareto Principle: "The Vital Few and Trivial Many Rule" "Predictable Imbalance"Document24 pagesPareto Principle: "The Vital Few and Trivial Many Rule" "Predictable Imbalance"m2z.marksmanNo ratings yet
- BayesplotDocument1 pageBayesplotEdgardo Alfredo Torres DahburaNo ratings yet
- Book 5 - Dark Sun ScreenDocument8 pagesBook 5 - Dark Sun ScreenTadas BotyriusNo ratings yet
- Costing Style ChangeDocument11 pagesCosting Style ChangeSalil SheikhNo ratings yet
- Jan. 25, 2010 Homework 1 Solutions 6.094: Introduction To MatlabDocument10 pagesJan. 25, 2010 Homework 1 Solutions 6.094: Introduction To MatlabAbelo AgarNo ratings yet
- BizzX News Winter07 Vol. 2 (1) : Values, Valuations and PerformanceDocument6 pagesBizzX News Winter07 Vol. 2 (1) : Values, Valuations and PerformanceDave LivingstonNo ratings yet
- Wide 0Document3 pagesWide 0gg hhNo ratings yet
- RegressionDocument34 pagesRegressiondianeadoukeNo ratings yet
- Pareto ChartDocument4 pagesPareto ChartArief FirmansyahNo ratings yet
- Data Interpretation 2Document132 pagesData Interpretation 2bNo ratings yet
- White Paper Methods For Deformulating DrugsDocument8 pagesWhite Paper Methods For Deformulating DrugsmtmpivvsNo ratings yet
- Pricing Mechanisms - Paul Hastings - PWCDocument8 pagesPricing Mechanisms - Paul Hastings - PWCcontactpulkitagarwalNo ratings yet
- Pareto Principle: "The Vital Few and Trivial Many Rule"Document24 pagesPareto Principle: "The Vital Few and Trivial Many Rule"Muhammad Saleem BuluNo ratings yet
- Strain Rosette ReganganDocument16 pagesStrain Rosette ReganganAnnisa Arifandita MifshellaNo ratings yet
- 7 0 0 4 MBA (Sem I) Theory Examination 2017-18 Business StatisticsDocument3 pages7 0 0 4 MBA (Sem I) Theory Examination 2017-18 Business StatisticsNishant TripathiNo ratings yet
- HW1 SolutionsDocument10 pagesHW1 SolutionsAlberto CaceresNo ratings yet
- Chapter 17 PowerPointDocument29 pagesChapter 17 PowerPointfitriawasilatulastifahNo ratings yet
- Investment Analysis On The PH D Course in TEMAP (Term Paper in SNU) (2006)Document25 pagesInvestment Analysis On The PH D Course in TEMAP (Term Paper in SNU) (2006)akoo100% (1)
- AncillaryServices JDMDocument62 pagesAncillaryServices JDMKiran TejaNo ratings yet
- 2.3 Pareto Charts SlidesDocument2 pages2.3 Pareto Charts Slidesal_snowNo ratings yet
- Mal 04 WorkSheetDocument1 pageMal 04 WorkSheetmr sNo ratings yet
- DEFINITIONDocument7 pagesDEFINITIONhappijennycambelleNo ratings yet
- Abstract 1323 Bjorn SteigerwaldDocument3 pagesAbstract 1323 Bjorn SteigerwaldgestesoNo ratings yet
- STARDUST-Trombón 2Document1 pageSTARDUST-Trombón 2Pewa CisnerosNo ratings yet
- Built in Functions 3rd EdDocument60 pagesBuilt in Functions 3rd EdShahril MohamadNo ratings yet
- HW4 Solutions: Problem 6.2Document8 pagesHW4 Solutions: Problem 6.2Souleymane CoulibalyNo ratings yet
- Micrologic 2.0 A Trip Unit Characteristic Trip Curve No. 613-9Document1 pageMicrologic 2.0 A Trip Unit Characteristic Trip Curve No. 613-9Diki NugrahaNo ratings yet
- B3-201-2018 - Developing and Using Justifiable Asset Health Indices For Tactical and Strategic Risk ManagementDocument10 pagesB3-201-2018 - Developing and Using Justifiable Asset Health Indices For Tactical and Strategic Risk ManagementNamLeNo ratings yet
- Propoly Price ListDocument68 pagesPropoly Price ListFzl ChowNo ratings yet
- Modifying Factors and Optimized Cut-Off Grade DetermonationDocument1 pageModifying Factors and Optimized Cut-Off Grade DetermonationВиталий ДроздовNo ratings yet
- Ts LinearDocument4 pagesTs LinearHajera UnnisaNo ratings yet
- Hymsong-Alto Saxophone 1Document1 pageHymsong-Alto Saxophone 1DOIRIN ElizeNo ratings yet
- Budget 2020-21: An Analysis by Research and Policy Integration For Development (Rapid)Document54 pagesBudget 2020-21: An Analysis by Research and Policy Integration For Development (Rapid)Ahmed AliNo ratings yet
- Charles Dickens Cuento de NavidadDocument32 pagesCharles Dickens Cuento de NavidadJavier CardenasNo ratings yet
- Aspects of the Dialogical Self: Extended proceedings of a symposium on the Second International Conference on the Dialogical Self (Ghent, Oct. 2002), including psycholonguistical, conversational, and educational contributionsFrom EverandAspects of the Dialogical Self: Extended proceedings of a symposium on the Second International Conference on the Dialogical Self (Ghent, Oct. 2002), including psycholonguistical, conversational, and educational contributionsMarie C BertauNo ratings yet
- Meta-Learning of Pooling Layers For Character RecoDocument16 pagesMeta-Learning of Pooling Layers For Character RecoNathaniel SauraNo ratings yet
- Davey Neil Gordon Thesis March 2018Document178 pagesDavey Neil Gordon Thesis March 2018Nathaniel SauraNo ratings yet
- Tomography 08 00075Document15 pagesTomography 08 00075Nathaniel SauraNo ratings yet
- Fferential Equations: Fast Neural Network Based Solving of Partial DiDocument6 pagesFferential Equations: Fast Neural Network Based Solving of Partial DiNathaniel SauraNo ratings yet
- Publi 6888Document9 pagesPubli 6888Nathaniel SauraNo ratings yet
- CoshxDocument4 pagesCoshxMirellea AndurayNo ratings yet
- Exercise Part IDocument16 pagesExercise Part ICo londota2No ratings yet
- Closed Forms For Numerical LoopsDocument29 pagesClosed Forms For Numerical LoopsTaolue ChenNo ratings yet
- Symmetric Matrices and Orthogonal DiagonalizationDocument15 pagesSymmetric Matrices and Orthogonal Diagonalizationpanna1No ratings yet
- Smta 1101Document1 pageSmta 1101VISVAA.JNo ratings yet
- Discrete MathematicsDocument45 pagesDiscrete MathematicsDilip KdNo ratings yet
- Maths 12Document4 pagesMaths 12zainabequbal8No ratings yet
- Linear AlgebraDocument3 pagesLinear AlgebraMehvish raniNo ratings yet
- Linear Algebra - P9 (Linear Transformations)Document41 pagesLinear Algebra - P9 (Linear Transformations)Росим ЁдалиNo ratings yet
- Tutorial 3Document2 pagesTutorial 3madanamohandrNo ratings yet
- Matrix Algebra For EngineersDocument189 pagesMatrix Algebra For EngineersPhilosopher DoctorNo ratings yet
- Matrices Determinants MSDocument42 pagesMatrices Determinants MSRenario Gule Hinampas Jr.No ratings yet
- Distance From A Point To A Line - WikipediaDocument9 pagesDistance From A Point To A Line - WikipediaDenes MarschalkoNo ratings yet
- Vectors and Force System (Lec 5-6) ME 122Document34 pagesVectors and Force System (Lec 5-6) ME 122Farhan AliNo ratings yet
- Mathematical Methods WK 1: Vectors: 1 Linear Vector SpacesDocument10 pagesMathematical Methods WK 1: Vectors: 1 Linear Vector SpacesW-d DomNo ratings yet
- Fe Math Review 2014Document19 pagesFe Math Review 2014Mahmoud Helmy100% (1)
- Iitjee MathsDocument78 pagesIitjee MathsSanjay GuptaNo ratings yet
- Statistical Methods in GeodesyDocument135 pagesStatistical Methods in GeodesytomskevinNo ratings yet
- Maths Class 12 Chapter WiseDocument166 pagesMaths Class 12 Chapter Wisesonikotnala81No ratings yet
- Solutions For Homework 1Document4 pagesSolutions For Homework 1Muhammad Fajar Agna FernandyNo ratings yet
- (CMBS-NSF 59) Grace Wahba - Spline Models For Observational Data-SIAM (1990)Document179 pages(CMBS-NSF 59) Grace Wahba - Spline Models For Observational Data-SIAM (1990)el.cadejoNo ratings yet
- Cramers Rule 3 by 3 Notes PDFDocument4 pagesCramers Rule 3 by 3 Notes PDFIsabella LagboNo ratings yet
- Matrix Algebra Basics: Based On Slides by Pam Perlich (U.Utah)Document18 pagesMatrix Algebra Basics: Based On Slides by Pam Perlich (U.Utah)mirika3shirinNo ratings yet
- Numerical Analysis ExercisesDocument160 pagesNumerical Analysis ExercisesA.BenhariNo ratings yet