Download as pdf or txt
You might also like
- Project 4 C++Document2 pagesProject 4 C++Jahangir AssaNo ratings yet
- MSODocument2 pagesMSOJoseph AnésNo ratings yet
- Practicum Project Proposal 2Document2 pagesPracticum Project Proposal 2Simone a0% (1)
- BE AIDS R 20 V VI Sem Syllabus CompressedDocument59 pagesBE AIDS R 20 V VI Sem Syllabus CompresseddinakarcNo ratings yet
- Soft Computing Laboratory Lab ManualDocument32 pagesSoft Computing Laboratory Lab Manualayeni100% (1)
- sk360 One PagerDocument2 pagessk360 One PagernikhilcyberlinksNo ratings yet
- Asip Project Rollno 43Document20 pagesAsip Project Rollno 43Muarif ShaikhNo ratings yet
- OOP ReportDocument25 pagesOOP Reporthuy01234055137No ratings yet
- Microcontroller Prototypes With ArduinoDocument355 pagesMicrocontroller Prototypes With Arduinohen2877100% (3)
- Utkarsh Resume3rd OctoberDocument1 pageUtkarsh Resume3rd OctoberUtkarsh AgrawalNo ratings yet
- Courses: Web DevelopmentDocument1 pageCourses: Web DevelopmentMohamed AymanNo ratings yet
- Mayank Ahuja: EducationDocument2 pagesMayank Ahuja: EducationMayank AhujaNo ratings yet
- JPR ProjectDocument26 pagesJPR ProjectShriram Sonwane100% (3)
- B. Tech. 2nd Year SyllabusDocument44 pagesB. Tech. 2nd Year SyllabusishitatayNo ratings yet
- PDFFFDocument20 pagesPDFFFridhi guptaNo ratings yet
- Design and Analysis of Gantry Robot For Pick and Place Mechanism WithDocument8 pagesDesign and Analysis of Gantry Robot For Pick and Place Mechanism WithHaider AliNo ratings yet
- Oops ProjectDocument20 pagesOops Projectvishalpanchal2k24No ratings yet
- ASWINRAJKTDocument48 pagesASWINRAJKTmuneerakottarath99No ratings yet
- Mad Project ReportDocument49 pagesMad Project ReportSatvik R kundargiNo ratings yet
- 3 Ejercicio - Entrenamiento y Evaluación de Un Modelo de Regresión - Training - Microsoft Learn - PDF InglesDocument19 pages3 Ejercicio - Entrenamiento y Evaluación de Un Modelo de Regresión - Training - Microsoft Learn - PDF Inglesacxel david castillo casasNo ratings yet
- Online Hotel Reservation SystemDocument87 pagesOnline Hotel Reservation SystemAwaneesh Vikram SinghNo ratings yet
- AI Facial Recognition SystemDocument54 pagesAI Facial Recognition SystemcontactchrisyellenNo ratings yet
- Abhishek 36 Project11Document8 pagesAbhishek 36 Project11Abhishek KumarNo ratings yet
- SEO Kumar Group SDocument191 pagesSEO Kumar Group SSanjeewan MangarNo ratings yet
- Microcontroller Prototypes With Arduino and A 3D Printer Dimosthenis E Bolanakis Full ChapterDocument67 pagesMicrocontroller Prototypes With Arduino and A 3D Printer Dimosthenis E Bolanakis Full Chaptertammie.bown829100% (6)
- Chirag Gupta's ResumeDocument1 pageChirag Gupta's ResumeChirag GuptaNo ratings yet
- VenkAT 2318264 6thsem ProjectDocument87 pagesVenkAT 2318264 6thsem ProjectANU GRAPHICSNo ratings yet
- MCA 2023-24 SyllabusDocument40 pagesMCA 2023-24 Syllabussunny sharmaNo ratings yet
- 5th Sem DEPMDocument100 pages5th Sem DEPMSuryaCharanPaidipalliNo ratings yet
- Jerin C FinalDocument129 pagesJerin C FinalSarath S NairNo ratings yet
- 0901 AD211056 ShanDocument9 pages0901 AD211056 ShanChandan JatNo ratings yet
- Lecture Notes w4 - Estimation and TrackingDocument25 pagesLecture Notes w4 - Estimation and Tracking홍석영No ratings yet
- 2024-06-15_logDocument24 pages2024-06-15_logdeyondmadNo ratings yet
- SynopsisDocument9 pagesSynopsisKiran SidhuNo ratings yet
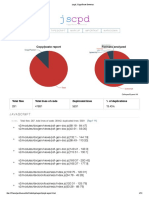
- JSCPD, Copy - Paste DetectorDocument28 pagesJSCPD, Copy - Paste DetectorPardha SaradhiNo ratings yet
- Darcet 2023 Vision Transformers Need RegistersDocument16 pagesDarcet 2023 Vision Transformers Need Registerscuong.huy.ptr.3No ratings yet
- Data SciDocument10 pagesData Sciharsat2030No ratings yet
- Development of UVM Based Reusabe Verification Environment For SHA-3 Cryptographic CoreDocument5 pagesDevelopment of UVM Based Reusabe Verification Environment For SHA-3 Cryptographic CoreEditor IJRITCC100% (1)
- Chirag Gupta's ResumeDocument1 pageChirag Gupta's ResumeChirag GuptaNo ratings yet
- Python Record FinalDocument81 pagesPython Record FinalBgmi 1No ratings yet
- Mounika Daa - 230724 - 160023Document12 pagesMounika Daa - 230724 - 160023KARTHIKEYAN SNo ratings yet
- Mini Project Report FormatDocument16 pagesMini Project Report Formatdhdw kwhdhwNo ratings yet
- Syllabus of 4btech CSEDocument12 pagesSyllabus of 4btech CSEshuklasumit719No ratings yet
- Exp-1 2 PDFDocument2 pagesExp-1 2 PDFAjayNo ratings yet
- 2024-05-27 77742890 LogDocument97 pages2024-05-27 77742890 LogJaveria HassanNo ratings yet
- CodetantraDocument51 pagesCodetantrapratik ghosh0% (1)
- Diabetic Retinopathy Detection Using Deep Learning: January 2022Document8 pagesDiabetic Retinopathy Detection Using Deep Learning: January 2022Hello ThereNo ratings yet
- Design of A Pid Auto Tuning Controller UDocument5 pagesDesign of A Pid Auto Tuning Controller USudh Desi ContentsNo ratings yet
- Sol9618 w23 QP 23Document20 pagesSol9618 w23 QP 23Sanan AlamNo ratings yet
- MT ReportDocument14 pagesMT Reportraagsha05No ratings yet
- CaculatorDocument20 pagesCaculatorLUCIFER DEVILNo ratings yet
- Behavioral CloningDocument5 pagesBehavioral CloningTest UserNo ratings yet
- Vlsi Design LaboratoryDocument10 pagesVlsi Design Laboratoryabi00eceNo ratings yet
- Cse (Aiml) Ii Year R22Document52 pagesCse (Aiml) Ii Year R22ballakarivarun96No ratings yet
- CPE 014 Activity 5 1 PDFDocument9 pagesCPE 014 Activity 5 1 PDFshi unlockNo ratings yet
- Lab # 1 AVM: Logical or Conceptual View: Exercise 1Document3 pagesLab # 1 AVM: Logical or Conceptual View: Exercise 1Farjad AliNo ratings yet
- Experiment NO.-1.4: Course Code: Course Name: Internet of Things LabDocument2 pagesExperiment NO.-1.4: Course Code: Course Name: Internet of Things LabHarshitNo ratings yet
- JupyterLab UnetDocument26 pagesJupyterLab UnetRANIA_MKHININI_GAHARNo ratings yet
- Css CBLM Coc4Document57 pagesCss CBLM Coc4InfoTutorial 2020100% (1)
- NC Resume 24Document1 pageNC Resume 24vishwas.mishra1234No ratings yet
- Project Report - 32527Document51 pagesProject Report - 32527siddhesh ghosalkarNo ratings yet
- Multi-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignFrom EverandMulti-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignNo ratings yet
- Thermodynamic System: by Angela Casogoc Jenifer Gomez 12-STEM PythagorasDocument14 pagesThermodynamic System: by Angela Casogoc Jenifer Gomez 12-STEM PythagorasJenifer B. GomezNo ratings yet
- Economics Class 11 Unit 4-Economic-DevelopmentDocument0 pagesEconomics Class 11 Unit 4-Economic-Developmentwww.bhawesh.com.npNo ratings yet
- Bsa 1 - Final Project ProposalDocument19 pagesBsa 1 - Final Project ProposalSherrymae ValenzuelaNo ratings yet
- CPBMJTT Baboon Strategic Management Plan 26 January 2023 Draft For Public CommentDocument22 pagesCPBMJTT Baboon Strategic Management Plan 26 January 2023 Draft For Public CommentMattNo ratings yet
- (Đề thi gồm 16 trang)Document16 pages(Đề thi gồm 16 trang)AstarothNo ratings yet
- Local Food PowerPoint TemplatesDocument48 pagesLocal Food PowerPoint TemplatesRizki NugrahaNo ratings yet
- Bonku BabuDocument2 pagesBonku BabuAbiya SajidNo ratings yet
- AS-Level Maths:: Statistics 1Document32 pagesAS-Level Maths:: Statistics 1Thomas Guo0% (1)
- 3D Finite Element Modeling of Precast Wall Panels Connection Under Monotonic LoadingDocument11 pages3D Finite Element Modeling of Precast Wall Panels Connection Under Monotonic Loadingabhishek kumarNo ratings yet
- Williamsk Portfolio Educ 6330Document29 pagesWilliamsk Portfolio Educ 6330api-328011965No ratings yet
- Line Distance Protection REL670: Course SEP671Document2 pagesLine Distance Protection REL670: Course SEP671budipppNo ratings yet
- 7 Chapter 3-MCEGoldDocument60 pages7 Chapter 3-MCEGoldPapun ScribdNo ratings yet
- كيفية إدارة الاجتماعDocument27 pagesكيفية إدارة الاجتماعAlfa99kNo ratings yet
- The Style and Narrative Techniques of Kushwant Singh's Writings: A Novelist and Writer: A Study of His Major NovelsDocument3 pagesThe Style and Narrative Techniques of Kushwant Singh's Writings: A Novelist and Writer: A Study of His Major Novels20309 KarthikNo ratings yet
- Kerjaya MatematikDocument20 pagesKerjaya MatematikRoszelan Majid100% (1)
- 3DS Thermoplastic-Manufacturing Whitepaper en FINALDocument12 pages3DS Thermoplastic-Manufacturing Whitepaper en FINALjaimeNo ratings yet
- Bongcalas, Rex Aino Assignment in HUM002 BSHRM 1A Jan. 8, 2018Document2 pagesBongcalas, Rex Aino Assignment in HUM002 BSHRM 1A Jan. 8, 2018Janel Castillo BalbiranNo ratings yet
- Danyal Education: Correct 117.9875 DecimalDocument20 pagesDanyal Education: Correct 117.9875 DecimalbrcraoNo ratings yet
- Curriculum JD Sustainable DevelopmentDocument52 pagesCurriculum JD Sustainable DevelopmentAmruchanNo ratings yet
- Difference Between Assimilation and AcculturationDocument3 pagesDifference Between Assimilation and AcculturationEj Rafael100% (2)
- Dier El-Medina Lesson PlanDocument2 pagesDier El-Medina Lesson PlanKiarna VisoiuNo ratings yet
- Moumita ResumeDocument2 pagesMoumita Resumemoumita2007No ratings yet
- ABB DCS 800XA Plant Explorer Workplace2Document13 pagesABB DCS 800XA Plant Explorer Workplace2Pramod Kumar GiriNo ratings yet
- Project Proposal: Department of EducationDocument2 pagesProject Proposal: Department of EducationAljan Hernandez ImperialNo ratings yet
- Case ReportDocument6 pagesCase Reportjae eNo ratings yet
- Faith and ReasonDocument3 pagesFaith and ReasonGabrielAmobiNo ratings yet
- Controlling The Solution of Linear Systems - FenicsprojectDocument6 pagesControlling The Solution of Linear Systems - FenicsprojectXu MoranNo ratings yet
- COA - C97-003Revised Estimated Useful Life in Computing Depreciation For Government PropDocument5 pagesCOA - C97-003Revised Estimated Useful Life in Computing Depreciation For Government PropJonnel AcobaNo ratings yet