Download as pdf or txt
You might also like
- Catalogue-Mitutoyo-2022 Final Ok PDFDocument638 pagesCatalogue-Mitutoyo-2022 Final Ok PDFHuỳnh Quốc DũngNo ratings yet
- Oracle® Fusion Middleware: Upgrading Oracle Business IntelligenceDocument177 pagesOracle® Fusion Middleware: Upgrading Oracle Business IntelligencekirishpatelNo ratings yet
- Sudoku Game (C++)Document5 pagesSudoku Game (C++)Saddam HussainNo ratings yet
- Hybrid Estimation of Complex SystemsDocument14 pagesHybrid Estimation of Complex SystemsJuan Carlos AmezquitaNo ratings yet
- Mathematical Programming For Piecewise Linear Regression AnalysisDocument43 pagesMathematical Programming For Piecewise Linear Regression AnalysishongxinNo ratings yet
- How To Be A Bayesian in SasDocument9 pagesHow To Be A Bayesian in SasWenKai ZhangNo ratings yet
- Imprtant Hof-Wil-04-hybridDiagnosisDocument14 pagesImprtant Hof-Wil-04-hybridDiagnosisboucharebNo ratings yet
- Best Imputation Techniques For Missing Values PDFDocument32 pagesBest Imputation Techniques For Missing Values PDFRaghav RVNo ratings yet
- Forward-Backward Selection With Early DroppingDocument39 pagesForward-Backward Selection With Early DroppingCaballero Alférez Roy TorresNo ratings yet
- Machine Learning To Analyze Single-Case Data: A Proof of ConceptDocument18 pagesMachine Learning To Analyze Single-Case Data: A Proof of ConceptSamuel FonsecaNo ratings yet
- IJAIADocument8 pagesIJAIAAdam HansenNo ratings yet
- Variable Selection in Multivariable Regression Using SAS/IMLDocument20 pagesVariable Selection in Multivariable Regression Using SAS/IMLbinebow517No ratings yet
- Improving Floating Search Feature Selection Using Genetic AlgorithmDocument19 pagesImproving Floating Search Feature Selection Using Genetic AlgorithmGhifari PrameswariNo ratings yet
- Bayesian Modeling Using The MCMC ProcedureDocument22 pagesBayesian Modeling Using The MCMC ProcedureKian JahromiNo ratings yet
- An Overview of Software For Conducting Dimensionality Assessmentent in Multidiomensional ModelsDocument11 pagesAn Overview of Software For Conducting Dimensionality Assessmentent in Multidiomensional ModelsPaola PorrasNo ratings yet
- Kernels, Model Selection and Feature SelectionDocument5 pagesKernels, Model Selection and Feature SelectionGautam VashishtNo ratings yet
- 14 Aos1260Document31 pages14 Aos1260Swapnaneel BhattacharyyaNo ratings yet
- 12562-Article (PDF) - 27062-1-10-20210527Document22 pages12562-Article (PDF) - 27062-1-10-20210527JITUL MORANNo ratings yet
- Journal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxDocument31 pagesJournal of Statistical Software: Multiple Imputation With Diagnostics (Mi) in R: Opening Windows Into The Black BoxAbi ZuñigaNo ratings yet
- A Comparison of The Mahalanobis-Taguchi System To A Standard Statistical Method For Defect DetectionDocument9 pagesA Comparison of The Mahalanobis-Taguchi System To A Standard Statistical Method For Defect Detection김형진No ratings yet
- Evaluation of Failure Probability Via Surrogate ModelsDocument15 pagesEvaluation of Failure Probability Via Surrogate ModelsFei NiNo ratings yet
- A GMM Approach For Dealing With Missing DataDocument41 pagesA GMM Approach For Dealing With Missing DataraghidkNo ratings yet
- Zhang 2015Document53 pagesZhang 2015Afif RaharjoNo ratings yet
- Fea Ture Selection Neural Networks Philippe Leray and Patrick GallinariDocument22 pagesFea Ture Selection Neural Networks Philippe Leray and Patrick GallinariVbg DaNo ratings yet
- NLS Tools ForDocument21 pagesNLS Tools ForTylerNo ratings yet
- Journal of Statistical Software: Missmda: A Package For Handling Missing ValuesDocument31 pagesJournal of Statistical Software: Missmda: A Package For Handling Missing ValuesDoris Martinez CancinoNo ratings yet
- J13 Global Resolution of The Support Vector Machine Regression Parameters Selection Problem With LPCCDocument67 pagesJ13 Global Resolution of The Support Vector Machine Regression Parameters Selection Problem With LPCCSTLiNo ratings yet
- Catherine Truxillo, PH.D., Stephen Mcdaniel, and David Mcnamara, Sas Institute Inc., Cary, NCDocument9 pagesCatherine Truxillo, PH.D., Stephen Mcdaniel, and David Mcnamara, Sas Institute Inc., Cary, NCK.Kiran KumarNo ratings yet
- Feature Selection Based On Class-Dependent Densities For High-Dimensional Binary DataDocument13 pagesFeature Selection Based On Class-Dependent Densities For High-Dimensional Binary DataNabeel AsimNo ratings yet
- Feature SelectionDocument18 pagesFeature Selectiongabby209No ratings yet
- Analysis, and Result InterpretationDocument6 pagesAnalysis, and Result InterpretationDainikMitraNo ratings yet
- Kalman FilteringDocument67 pagesKalman Filteringravi_nstlNo ratings yet
- A Comparative Study of Multiple Imputation and Maximum Likelihood Methods of Imputing Missing Data in ADocument14 pagesA Comparative Study of Multiple Imputation and Maximum Likelihood Methods of Imputing Missing Data in Asegun aladeNo ratings yet
- Computational Statistics and Data Analysis: Kuo-Jung Lee, Martin Feldkircher, Yi-Chi ChenDocument19 pagesComputational Statistics and Data Analysis: Kuo-Jung Lee, Martin Feldkircher, Yi-Chi ChenMariella BogoniNo ratings yet
- Cb-Pattern Trees: Identifying Distributed Nodes Where Materialization Is AvailableDocument12 pagesCb-Pattern Trees: Identifying Distributed Nodes Where Materialization Is AvailableLewis TorresNo ratings yet
- Delac 01Document6 pagesDelac 01Sayantan ChakrabortyNo ratings yet
- Applications of Simulations in Social ResearchDocument3 pagesApplications of Simulations in Social ResearchPio FabbriNo ratings yet
- Stepwise RegressionDocument4 pagesStepwise Regressionharrison9No ratings yet
- TechDocument38 pagesTechKaruna SriNo ratings yet
- Influence of Selection On Structure Learning in Markov Network EDAs: An Empirical StudyDocument22 pagesInfluence of Selection On Structure Learning in Markov Network EDAs: An Empirical StudyMartin PelikanNo ratings yet
- From Explanations To Feature Selection: Assessing SHAP Values As Feature Selection MechanismDocument8 pagesFrom Explanations To Feature Selection: Assessing SHAP Values As Feature Selection MechanismasdsafdsNo ratings yet
- 3038-Article Text-5729-1-10-20210418Document6 pages3038-Article Text-5729-1-10-20210418II9I4005I Uni Andriani Sitohang (119140051 Uni A Sitohang)No ratings yet
- Unit V - Big Data ProgrammingDocument22 pagesUnit V - Big Data ProgrammingjasmineNo ratings yet
- Choosing Bankruptcy Predictors Using Discriminant Analysis, Logit Analysis, and Genetic AlgorithmsDocument20 pagesChoosing Bankruptcy Predictors Using Discriminant Analysis, Logit Analysis, and Genetic AlgorithmsŁukasz KarczewskiNo ratings yet
- Final Project ReportDocument18 pagesFinal Project ReportjstpallavNo ratings yet
- IMAMCI Lipschitz v8Document12 pagesIMAMCI Lipschitz v8Panagiotis PapageorgiouNo ratings yet
- 1 s2.0 S0004370213001082 MainDocument33 pages1 s2.0 S0004370213001082 MainParth ThakkarNo ratings yet
- Ram Dom ForestDocument32 pagesRam Dom ForestAna Gabriela Bohórquez QuingaNo ratings yet
- Interacting Multiple Model Methods in Target Tracking: A SurveyDocument21 pagesInteracting Multiple Model Methods in Target Tracking: A SurveynamithdevadigaNo ratings yet
- 14 PDFDocument15 pages14 PDFAnonymous cxNsEvNo ratings yet
- General-to-Specific Reductions of Vector Autoregressive ProcessesDocument20 pagesGeneral-to-Specific Reductions of Vector Autoregressive ProcessesAhmed H ElsayedNo ratings yet
- Multimodal Biometrics: Issues in Design and TestingDocument5 pagesMultimodal Biometrics: Issues in Design and TestingMamta KambleNo ratings yet
- A Purposeful Selection of Variables Macro For Logistic RegressionDocument5 pagesA Purposeful Selection of Variables Macro For Logistic RegressionrahulsukhijaNo ratings yet
- A Study On Visualizing Semantically Similar Frequent Patterns in Dynamic DatasetsDocument6 pagesA Study On Visualizing Semantically Similar Frequent Patterns in Dynamic DatasetsInternational Journal of computational Engineering research (IJCER)No ratings yet
- Using Deep Neural Networks To Automate Large Scale Statistical Analysis For Big Data ApplicationsDocument16 pagesUsing Deep Neural Networks To Automate Large Scale Statistical Analysis For Big Data Applicationsbhavanisankari sNo ratings yet
- Efficient Global Optimization of Expensive Black-Box FunctionsDocument38 pagesEfficient Global Optimization of Expensive Black-Box FunctionsBengt HörbergNo ratings yet
- High Dimensional Forecasting Via Interpretable Vector AutoregressionDocument52 pagesHigh Dimensional Forecasting Via Interpretable Vector AutoregressionAli MohadesNo ratings yet
- Variable Selection Via Nonconcave Penalized Likelihood and Its Oracle PropertiesDocument14 pagesVariable Selection Via Nonconcave Penalized Likelihood and Its Oracle Properties1206052611No ratings yet
- L.raffalovich@albany - Edu) .: Draft Copy - Not For Citation or Quotation Without The Authors' PermissionDocument16 pagesL.raffalovich@albany - Edu) .: Draft Copy - Not For Citation or Quotation Without The Authors' PermissionIrenataNo ratings yet
- Multivariate StatisticsDocument6 pagesMultivariate Statisticsbenjamin212No ratings yet
- Mixture Models and ApplicationsFrom EverandMixture Models and ApplicationsNizar BouguilaNo ratings yet
- final (1)Document16 pagesfinal (1)DEBORA NURAININo ratings yet
- garuda3450215Document14 pagesgaruda3450215DEBORA NURAININo ratings yet
- IJIRSS20236(1)128-136Document9 pagesIJIRSS20236(1)128-136DEBORA NURAININo ratings yet
- 8934-10404-1-PB (1)Document3 pages8934-10404-1-PB (1)DEBORA NURAININo ratings yet
- 536-Article Text-1696-1-10-20230729Document9 pages536-Article Text-1696-1-10-20230729DEBORA NURAININo ratings yet
- Daftar PustakaDocument11 pagesDaftar PustakaDEBORA NURAININo ratings yet
- 7395-28907-1-PBDocument12 pages7395-28907-1-PBDEBORA NURAININo ratings yet
- 84820100402Document11 pages84820100402DEBORA NURAININo ratings yet
- overview-and-evolution-of-the-addie-training-systemDocument13 pagesoverview-and-evolution-of-the-addie-training-systemDEBORA NURAININo ratings yet
- Ej 1127494Document24 pagesEj 1127494DEBORA NURAININo ratings yet
- A Need Assessment On Students' Career GuidanceDocument10 pagesA Need Assessment On Students' Career GuidanceDEBORA NURAININo ratings yet
- Needs Assessment Tool KitDocument10 pagesNeeds Assessment Tool KitDEBORA NURAININo ratings yet
- Needs Assessment From Theory To PracticeDocument11 pagesNeeds Assessment From Theory To PracticeDEBORA NURAININo ratings yet
- What Is A Mechanical Joint 22Document16 pagesWhat Is A Mechanical Joint 22Arjhay GironellaNo ratings yet
- 9-6 Error Messages ReferenceDocument2,536 pages9-6 Error Messages ReferenceHarish BandiNo ratings yet
- GOMO Complete Document February 2020 2 242Document1 pageGOMO Complete Document February 2020 2 242RICROD71No ratings yet
- ERP Life CycleDocument9 pagesERP Life CycleChintu Sisodia100% (1)
- SE Internal Examination Time Table - Sem - I - 2023-24Document1 pageSE Internal Examination Time Table - Sem - I - 2023-24Prathamesh BhavsarNo ratings yet
- Github ComDocument23 pagesGithub ComMamitianaNo ratings yet
- 33kV - Cap - Bank-SIKAP - Spec - FY 12-13 - 30.11.11-Cesc - 20 MVARDocument9 pages33kV - Cap - Bank-SIKAP - Spec - FY 12-13 - 30.11.11-Cesc - 20 MVARSatyajit RaiNo ratings yet
- Monster Power - HTS3500 Manual PDFDocument42 pagesMonster Power - HTS3500 Manual PDFJose MondragonNo ratings yet
- Messier-Bugatti-Dowty: World Leader in Landing and Braking SystemsDocument30 pagesMessier-Bugatti-Dowty: World Leader in Landing and Braking SystemsBeshir KhmekhemNo ratings yet
- Unit 6 PII MACHINE LEARNINGDocument43 pagesUnit 6 PII MACHINE LEARNINGSakshi ChoudharyNo ratings yet
- Quality Assurance Handbook 1677275668Document140 pagesQuality Assurance Handbook 1677275668r2mgt28ssvNo ratings yet
- Briggs & Stratton LLC - Briggs & Stratton Power Guide 2024Document65 pagesBriggs & Stratton LLC - Briggs & Stratton Power Guide 2024Benoît MARTINNo ratings yet
- Firfighting Operations 2Document606 pagesFirfighting Operations 2San Antonio Fire StationNo ratings yet
- PGL - Online 101.1 DraftDocument4 pagesPGL - Online 101.1 DraftZaeni AhmadNo ratings yet
- Textbook Programming Language Concepts Peter Sestoft Ebook All Chapter PDFDocument51 pagesTextbook Programming Language Concepts Peter Sestoft Ebook All Chapter PDFcandace.conklin507100% (7)
- CV - Willy Hari Rizki - Admin ProjectDocument1 pageCV - Willy Hari Rizki - Admin ProjectSatugaris HumanNo ratings yet
- Query and Transformation in DBMS: Done by Ruban Christu RajDocument10 pagesQuery and Transformation in DBMS: Done by Ruban Christu RajRuban Christu rajNo ratings yet
- Annexure 1b - State Tax Office - Major City - Above 1-5crDocument914 pagesAnnexure 1b - State Tax Office - Major City - Above 1-5crchulharesturant.2009.01No ratings yet
- Q2, WK 1 - Linear InequalitiesDocument3 pagesQ2, WK 1 - Linear InequalitiesRam BoncodinNo ratings yet
- Ansys Exercise PDFDocument14 pagesAnsys Exercise PDFRajesh Choudhary0% (1)
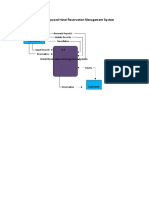
- Context Diagram of Proposed Hotel Reservation Management SystemDocument8 pagesContext Diagram of Proposed Hotel Reservation Management SystemJoffrey Montalla67% (3)
- Pump SpecificationDocument2 pagesPump Specificationedgar ricoNo ratings yet
- Smart Doctors Assistant - An Advanced Appointment Booking System For HospitalsDocument8 pagesSmart Doctors Assistant - An Advanced Appointment Booking System For HospitalsIJAR JOURNALNo ratings yet
- Ai&ml RecordDocument57 pagesAi&ml Recordhemapardeep8No ratings yet
- 2102 - PGA Labs Report - Internet First BrandsDocument31 pages2102 - PGA Labs Report - Internet First BrandsGanesh Mahidhar100% (1)
- Mechanical Properties of Glass PowderDocument11 pagesMechanical Properties of Glass PowderMR. ESHAN GHARPURENo ratings yet
- EEX 107.03 Evaluating Applied-Potential TestsDocument44 pagesEEX 107.03 Evaluating Applied-Potential TestsJellyn Base100% (1)