Download as pdf or txt
You might also like
- Jenkins Course Slides PDFDocument96 pagesJenkins Course Slides PDFkamal.tejnani5613100% (2)
- Red Hat OpenShift Training Workshop SlidesDocument95 pagesRed Hat OpenShift Training Workshop Slideskaralyh100% (1)
- 00 Jenkins NotesDocument12 pages00 Jenkins NotesVijay Rangareddy KadiriNo ratings yet
- JenkinsDocument5 pagesJenkinsAnuNo ratings yet
- Answers To Jenkins Interview QuestionsDocument3 pagesAnswers To Jenkins Interview QuestionsPappu KhanNo ratings yet
- JenDocument16 pagesJenAnkit AgrawalNo ratings yet
- Jenkins PPTDocument24 pagesJenkins PPTthecoinmaniac hodl100% (1)
- JenkinsDocument19 pagesJenkinsAnushka RawatNo ratings yet
- DevOps Cours JenkinsDocument44 pagesDevOps Cours Jenkinsahdy kefiNo ratings yet
- Jenkin Interview Questions For Beginners:: 1. Describe About Some Characteristics of JenkinsDocument11 pagesJenkin Interview Questions For Beginners:: 1. Describe About Some Characteristics of Jenkinspavan kumarNo ratings yet
- Jenkins Notes 1700451057Document30 pagesJenkins Notes 1700451057Samarth HandurNo ratings yet
- Q1. What Is Jenkins?: Once You Have Defined Jenkins Give An Example, You Can Refer The Below Mentioned Use CaseDocument7 pagesQ1. What Is Jenkins?: Once You Have Defined Jenkins Give An Example, You Can Refer The Below Mentioned Use CaseRicardo OrtizuNo ratings yet
- Jenkins LabDocument11 pagesJenkins LabMukesh GildaNo ratings yet
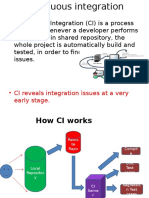
- CI Reveals Integration Issues at A Very Early StageDocument13 pagesCI Reveals Integration Issues at A Very Early Stageragavendira100% (1)
- Introduction To Jenkins and Continuous Integration: Jenkins Tutorial - Table of ContentDocument12 pagesIntroduction To Jenkins and Continuous Integration: Jenkins Tutorial - Table of ContentGade BalajiNo ratings yet
- JenkinsDocument13 pagesJenkinsvlj47633No ratings yet
- U Nit 4 Lecture-2Document13 pagesU Nit 4 Lecture-2piyushsisodiya2001No ratings yet
- Introduction To Jenkins - SpringPeopleDocument12 pagesIntroduction To Jenkins - SpringPeopleSpringPeople100% (1)
- Jenkins: SDL - KHTPDocument42 pagesJenkins: SDL - KHTPnader100% (1)
- Unit 1.1 CI CD - Dharani PDFDocument19 pagesUnit 1.1 CI CD - Dharani PDFDivyanshi SharmaNo ratings yet
- Jenkins Interview QuestionsDocument11 pagesJenkins Interview QuestionsshauiiaNo ratings yet
- JenkinsDocument11 pagesJenkinskanmaniprsnlNo ratings yet
- Rubina Pradhan: Dev0psDocument4 pagesRubina Pradhan: Dev0psVishal JainNo ratings yet
- Jenkins Introduction: Jenkins Is The "Leading Open Source Automation Server."Document40 pagesJenkins Introduction: Jenkins Is The "Leading Open Source Automation Server."sivajiNo ratings yet
- Jenkins Interview Questions: Click HereDocument21 pagesJenkins Interview Questions: Click HereChandrakantShindeNo ratings yet
- Jenkins Interview Questions (1)Document9 pagesJenkins Interview Questions (1)swaleheen08No ratings yet
- Bams CollegeDocument9 pagesBams CollegePrashant PhadNo ratings yet
- JenkinsDocument36 pagesJenkinsCuong DoNo ratings yet
- 4.1. What Is Jenkins?Document3 pages4.1. What Is Jenkins?Licht ZoraNo ratings yet
- UNIT 5 Part1Document101 pagesUNIT 5 Part1Mahammad SHAIKNo ratings yet
- UNIT 5 Part1Document90 pagesUNIT 5 Part1Abhishek KumarNo ratings yet
- CI and ToolsDocument34 pagesCI and ToolsValentin DumitriucNo ratings yet
- Pintu MallickDocument5 pagesPintu MallickShweta SinghNo ratings yet
- What Is JenkinsDocument7 pagesWhat Is Jenkinsshradha11No ratings yet
- What & Why JenkinsDocument7 pagesWhat & Why JenkinsShuaib MohammedNo ratings yet
- DevOps Sample ResumeDocument3 pagesDevOps Sample ResumeSaiNo ratings yet
- Jenkins Interview QuestionsDocument3 pagesJenkins Interview Questionsssdasd sNo ratings yet
- Intro To JenkinsDocument31 pagesIntro To Jenkinsanarki85No ratings yet
- Module 3 - JenkinsDocument25 pagesModule 3 - JenkinsJeff DeepNo ratings yet
- Vijay Kumar.: Roles &responsibilitiesDocument4 pagesVijay Kumar.: Roles &responsibilitiesk maheshNo ratings yet
- DevOps Expt 5Document1 pageDevOps Expt 5Somnath MuleNo ratings yet
- Mahesh Narapareddy Contact: +91-9035222470Document5 pagesMahesh Narapareddy Contact: +91-9035222470Rushmitha LeburuNo ratings yet
- 1.1.1 Below Are The Advantages of Jenkins:: Continuous IntegrationDocument2 pages1.1.1 Below Are The Advantages of Jenkins:: Continuous Integrationrabindra biswalNo ratings yet
- Jenkin PresentationsDocument8 pagesJenkin PresentationskasimNo ratings yet
- JenkinsDocument39 pagesJenkinsSachin KuchhalNo ratings yet
- Associate Consultant: - : Git - : Maven - : Jenkins - : JiraDocument4 pagesAssociate Consultant: - : Git - : Maven - : Jenkins - : Jirauday kumarNo ratings yet
- Jenkins - Fundamentals - CloudBeesDocument14 pagesJenkins - Fundamentals - CloudBeesGOPI CNo ratings yet
- Sree Harsha. A: ObjectiveDocument4 pagesSree Harsha. A: ObjectiveSree Harsha Ananda RaoNo ratings yet
- Continuous Integration Overview: Integrate at Least DailyDocument12 pagesContinuous Integration Overview: Integrate at Least DailyscibyNo ratings yet
- Week 7 Sia Jenkins F2FDocument2 pagesWeek 7 Sia Jenkins F2Finfinitetsukoyomi24No ratings yet
- Kaushik 11years QA DevOps-1Document3 pagesKaushik 11years QA DevOps-1Shaik Mahammad AlthafNo ratings yet
- Introduction To JenkinsDocument13 pagesIntroduction To JenkinsManish Kumar RaiNo ratings yet
- Devops STRUCTUREDocument14 pagesDevops STRUCTUREmahendra bollaNo ratings yet
- Devops BooksDocument10 pagesDevops Bookshemanth-mokaNo ratings yet
- Dinesh Resume NEWDocument4 pagesDinesh Resume NEWDinesh DinuNo ratings yet
- GitHub For (CI-CD) DevOpsDocument5 pagesGitHub For (CI-CD) DevOpsabhinavsrivastavNo ratings yet
- 50 Jenkins Interview Questions and Answers 2023Document10 pages50 Jenkins Interview Questions and Answers 2023waseem chaudhriNo ratings yet
- Devops Part I - What Is Devops?: Len BassDocument33 pagesDevops Part I - What Is Devops?: Len BassDevendra GautamNo ratings yet
- Introductrion To Ci/CdDocument3 pagesIntroductrion To Ci/CdB VAMSI KRISHNA REDDYNo ratings yet
- Roja P: AWS/ Devops EngineerDocument5 pagesRoja P: AWS/ Devops EngineerRishikeshNo ratings yet
- Docker Tutorial - Intellipaat PDFDocument15 pagesDocker Tutorial - Intellipaat PDFadilmohdkhan1089No ratings yet
- Kubernetes in Action Second Edition p01 50Document50 pagesKubernetes in Action Second Edition p01 50cqgjuismnafjzcoqoaNo ratings yet
- Exam Ref 70 533 Implementing Microsoft AzureDocument1,038 pagesExam Ref 70 533 Implementing Microsoft Azureelahi elahiNo ratings yet
- Linux Scenario Based Interviews QuestionsDocument19 pagesLinux Scenario Based Interviews QuestionsjosephNo ratings yet
- Network IT ZationDocument15 pagesNetwork IT ZationArij SalehNo ratings yet
- Containerize Java A2c in AwsDocument20 pagesContainerize Java A2c in AwslluisNo ratings yet
- Red Hat Virtualization-4.3-Installing Red Hat Virtualization As A Self-Hosted Engine Using The Command Line-En-UsDocument86 pagesRed Hat Virtualization-4.3-Installing Red Hat Virtualization As A Self-Hosted Engine Using The Command Line-En-UsAvo AndrinantenainaNo ratings yet
- PPT-unit 4-303105103Document18 pagesPPT-unit 4-303105103akhilyadavjerri488No ratings yet
- Virtualization in Distributed System: A Brief OverviewDocument5 pagesVirtualization in Distributed System: A Brief OverviewBOHR International Journal of Computer Science (BIJCS)100% (1)
- DockerDocument9 pagesDockerTejas SawantNo ratings yet
- L3 01 Docker Howto Basic GuideDocument18 pagesL3 01 Docker Howto Basic GuideremotedeskepsmNo ratings yet
- Introduction To Kubernetes and Containers - The Kubernetes WorkshopDocument77 pagesIntroduction To Kubernetes and Containers - The Kubernetes WorkshopOLALEKAN ALEDARENo ratings yet
- Docker For Java Developers: Sergey Morenets, 2019Document67 pagesDocker For Java Developers: Sergey Morenets, 2019oyster66johnNo ratings yet
- Containerization in Cloud Computing For OS-level VirtualizationDocument13 pagesContainerization in Cloud Computing For OS-level VirtualizationSano ManjiroNo ratings yet
- Container Engine Vs Container RuntimeDocument10 pagesContainer Engine Vs Container RuntimeMohamed RahalNo ratings yet
- DWF13 Designing QorIQ Software SanJoseDocument73 pagesDWF13 Designing QorIQ Software SanJosenavid mirmotahharyNo ratings yet
- Docker NotesDocument15 pagesDocker NotesSiva AbburiNo ratings yet
- TM112-TMA-Spring21-22 عبدالعزيزDocument5 pagesTM112-TMA-Spring21-22 عبدالعزيزعزالدين صادق علي احمد الجلالNo ratings yet
- Full Chapter Monitoring Microservices and Containerized Applications Deployment Configuration and Best Practices For Prometheus and Alert Manager Navin Sabharwal PDFDocument54 pagesFull Chapter Monitoring Microservices and Containerized Applications Deployment Configuration and Best Practices For Prometheus and Alert Manager Navin Sabharwal PDFmichael.gill825100% (8)
- Kubernetes Vs DockerDocument9 pagesKubernetes Vs DockerjayNo ratings yet
- Foundations of Red Hat Cloud-NativeDocument60 pagesFoundations of Red Hat Cloud-NativeRodolfo VilNo ratings yet
- WS-011 Windows Server 2019 AdministrationDocument71 pagesWS-011 Windows Server 2019 AdministrationAlbert JeremyNo ratings yet
- Website Testing and DeploymentDocument34 pagesWebsite Testing and DeploymentSupriya YenniNo ratings yet
- Owasp DockerDocument25 pagesOwasp DockerJackNo ratings yet
- Platformsh Fleet Ops Alternative To KubernetesDocument19 pagesPlatformsh Fleet Ops Alternative To KubernetesaitlhajNo ratings yet
- 29 Jan 2023 WeekEnd IntellipaatDocument18 pages29 Jan 2023 WeekEnd IntellipaatSuresh GNo ratings yet
- Concept Page - Using Vagrant On Your Personal Computer - Holberton Intranet PDFDocument7 pagesConcept Page - Using Vagrant On Your Personal Computer - Holberton Intranet PDFJeffery James DoeNo ratings yet
- An Introduction To DockerDocument15 pagesAn Introduction To DockerPratham JaiswalNo ratings yet
- Unreal Engine Solutions CloudDocument13 pagesUnreal Engine Solutions CloudHumberto ParisiNo ratings yet