Download as pdf or txt
You might also like
- Stay Safe Women Security Android App Project ReportDocument43 pagesStay Safe Women Security Android App Project ReportBhagyaraj Nadar83% (36)
- TV Cabling SolutionDocument76 pagesTV Cabling SolutionNymphetamine AnhNo ratings yet
- Aztech MWR647 Easy Start GuideDocument20 pagesAztech MWR647 Easy Start GuideVincent 2020No ratings yet
- BDA3Document7 pagesBDA3nikithakatta0No ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends ImplementsDocument7 pagesImport Import Import Import Import Import Import Import Public Class Extends ImplementsSARAVANANNo ratings yet
- MapReduce ExampleDocument3 pagesMapReduce ExampleRavi ChanderNo ratings yet
- Exp 4 Word CountDocument4 pagesExp 4 Word Countmunish kumar agarwalNo ratings yet
- CS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011Document13 pagesCS246 TA Session: Hadoop Tutorial: Peyman Kazemian 1/11/2011smitanair143No ratings yet
- Part B Assignment - No - 1Document6 pagesPart B Assignment - No - 1opscoldyNo ratings yet
- Import Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsDocument6 pagesImport Import Import Import Import Import Import Import Public Class Extends Implements Public Void ThrowsSARAVANANNo ratings yet
- DSBDA GRP B PrintDocument21 pagesDSBDA GRP B PrinttmhrrsmordeNo ratings yet
- Run WordcountDocument3 pagesRun WordcountKhushi PatilNo ratings yet
- Practical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inDocument61 pagesPractical-1: Aim: Hadoop Configuration and Single Node Cluster Setup and Perform File Management Task inParthNo ratings yet
- Experiment No: 1: Create Different Entities DynamicallyDocument43 pagesExperiment No: 1: Create Different Entities Dynamicallyvinay DeshmukhNo ratings yet
- 6 - Simple WordcountDocument2 pages6 - Simple WordcountXavier TxANo ratings yet
- WordCount Program Hadoop Task 2Document7 pagesWordCount Program Hadoop Task 220261A6757 VIJAYAGIRI ANIL KUMARNo ratings yet
- WordcountDocument3 pagesWordcount21020279 Trần Diệu AnhNo ratings yet
- BDA Lab 8 ManualDocument7 pagesBDA Lab 8 ManualMydah NasirNo ratings yet
- Developing A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanDocument22 pagesDeveloping A Simple Map-Reduce Program For Hadoop: Big Data Course CS6350 Professor: Dr. Latifur KhanKaushal PrajapatiNo ratings yet
- BDT Lab ManualDocument48 pagesBDT Lab ManualVishnu Vardhan HNo ratings yet
- Word Count Program To Demonstrate The Use of Map and Reduce TasksDocument5 pagesWord Count Program To Demonstrate The Use of Map and Reduce Tasksriya kNo ratings yet
- Hadoop Streaming Hadoop Pipes Swig: 4 Inputs and OutputsDocument1 pageHadoop Streaming Hadoop Pipes Swig: 4 Inputs and Outputsp001No ratings yet
- Experiment: Word Count in HadoopDocument12 pagesExperiment: Word Count in HadoopSAMINA ATTARINo ratings yet
- Bda Final 11janDocument7 pagesBda Final 11janG dileep KumarNo ratings yet
- Step 2 - First MapReduce ProgramDocument25 pagesStep 2 - First MapReduce ProgramSantosh Kumar DesaiNo ratings yet
- Assignment 2-033Document13 pagesAssignment 2-033DHARSHANA C PNo ratings yet
- Hadoop Training in HyderabadDocument49 pagesHadoop Training in HyderabadkellytechnologiesNo ratings yet
- Big Data - ASSIGNMENT 2Document15 pagesBig Data - ASSIGNMENT 2DHARSHANA C PNo ratings yet
- Lab ManualDocument86 pagesLab Manualpthuynh709No ratings yet
- Tutorial-Counting Words in File (S) Using Mapreduce: PrerequisitesDocument11 pagesTutorial-Counting Words in File (S) Using Mapreduce: PrerequisitessaiconzeNo ratings yet
- Map ReduceDocument3 pagesMap ReduceRiya JanaNo ratings yet
- Department of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3Document4 pagesDepartment of Computer Science and Engineering: Delhi Technological University Big Data Analysis Lab-BDA E3-G3IshanNo ratings yet
- Big data ManualDocument82 pagesBig data ManualrethinakumariNo ratings yet
- Eco System NotesDocument15 pagesEco System Noteszammy officialNo ratings yet
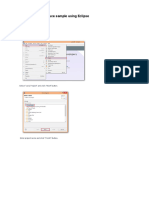
- Execute Java Map Reduce Sample Using EclipseDocument9 pagesExecute Java Map Reduce Sample Using EclipseArjun SNo ratings yet
- Prerequisites: Single Node Setup Cluster SetupDocument5 pagesPrerequisites: Single Node Setup Cluster Setupmartha quingaNo ratings yet
- ADA Lab ManualDocument34 pagesADA Lab Manualnalluri_08No ratings yet
- HadoopDocument51 pagesHadoopRavitej TadinadaNo ratings yet
- AsyncTask and LoadersDocument21 pagesAsyncTask and LoadersAlvaro MedinaNo ratings yet
- 85-87 Java Web Development With Eclipse WTPDocument6 pages85-87 Java Web Development With Eclipse WTPnnmmNo ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- Hadoop and Map ReduceDocument27 pagesHadoop and Map Reducearshpreetmundra14No ratings yet
- Information For Applications of WsDocument4 pagesInformation For Applications of WssatyanarayanaNo ratings yet
- Hadoop Administrator Training - Lab Hand BookDocument12 pagesHadoop Administrator Training - Lab Hand BookdebkrcNo ratings yet
- 85-87 Java Web Development With Eclipse WTP PREVODDocument7 pages85-87 Java Web Development With Eclipse WTP PREVODnnmmNo ratings yet
- Bda Unit-IiiDocument42 pagesBda Unit-IiirohithatimsiNo ratings yet
- BDALab Assn4Document9 pagesBDALab Assn4Deepti AgrawalNo ratings yet
- Hadoop WordCountDocument2 pagesHadoop WordCountkavya kavNo ratings yet
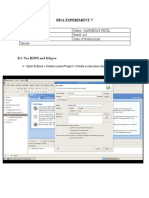
- Bda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeDocument8 pagesBda Experiment 7: Roll No. A-52 Name: Janmejay Patil Class: BE-A Batch: A3 Date of Experiment: Date of Submission GradeAlkaNo ratings yet
- BDA LabManualDocument20 pagesBDA LabManualposprojectzNo ratings yet
- My Web ServiceDocument19 pagesMy Web ServiceRavindra VangipuramNo ratings yet
- Big DataDocument23 pagesBig DataYashika SinghNo ratings yet
- Setting Up Eclipse:: Codelab 1 Introduction To The Hadoop Environment (Version 0.17.0)Document9 pagesSetting Up Eclipse:: Codelab 1 Introduction To The Hadoop Environment (Version 0.17.0)K V D SagarNo ratings yet
- To Count Using Map and Reduce Program: Wordcount - JavaDocument2 pagesTo Count Using Map and Reduce Program: Wordcount - JavaRamya DeviNo ratings yet
- Steps: /usr/lib/hadoop-0.20/ Usr/lib/hadoop-0.20/libDocument4 pagesSteps: /usr/lib/hadoop-0.20/ Usr/lib/hadoop-0.20/libKarthick JothivelNo ratings yet
- Jenkins Declarative PipelineDocument41 pagesJenkins Declarative PipelineRakesh MahtaNo ratings yet
- DOCS For ApacheDocument3 pagesDOCS For ApacheDileep Prabakar100% (1)
- Lecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)Document22 pagesLecture 23: Pig: Making Hadoop Easy (Slides Provided By: Alan Gates, Yahoo!Research)kumarNo ratings yet
- Java Naming and Directory InterfaceDocument16 pagesJava Naming and Directory InterfaceRaj AwatadeNo ratings yet
- BDF Lab1Document6 pagesBDF Lab1shaliniiiiNo ratings yet
- PalakDocument10 pagesPalakDolly MehraNo ratings yet
- EX - NO.1 Aim: To Learn and Use Network CommandsDocument53 pagesEX - NO.1 Aim: To Learn and Use Network CommandsElakkiya100% (1)
- Management Become The Five M's ModelDocument4 pagesManagement Become The Five M's ModelNutan PrakashNo ratings yet
- Menus and Menu SetsDocument4 pagesMenus and Menu SetsSrinivas KachibhotlaNo ratings yet
- Lecture12 Application LayerDocument33 pagesLecture12 Application Layernguyenquanglinh01121999No ratings yet
- 4-25 Rear Final Drive: Exc - Limited Slip DiffDocument5 pages4-25 Rear Final Drive: Exc - Limited Slip Diffshupry yhantoNo ratings yet
- Tac68 01Document32 pagesTac68 01TateNo ratings yet
- Guard Phone For Apartment Unit: WarrantyDocument6 pagesGuard Phone For Apartment Unit: Warrantylokuras de la vidaNo ratings yet
- 11.0 Road Safety-AuditsDocument30 pages11.0 Road Safety-AuditsGerald Maginga0% (1)
- The Computer Society - The Age of Miracle Chips - Modern MechanixDocument5 pagesThe Computer Society - The Age of Miracle Chips - Modern MechanixAnonymous KafQqCkNo ratings yet
- SubscriberDocument449 pagesSubscribercityinslandinfoNo ratings yet
- Cybercrime Comparison Under Criminal Law in Some CountriesDocument10 pagesCybercrime Comparison Under Criminal Law in Some CountriesSetyo RahmaNo ratings yet
- 035.00.081 Service Manual Humification Module E3.1 in E3.0Document17 pages035.00.081 Service Manual Humification Module E3.1 in E3.0pensalfini xavierNo ratings yet
- Avigilon Acc7 Client enDocument221 pagesAvigilon Acc7 Client ensaqibNo ratings yet
- Ruth Rikowski - Digitisation PerspectivesDocument326 pagesRuth Rikowski - Digitisation PerspectiveslolivonlolaNo ratings yet
- Slim and Symmetrical. Every Presentation Will Command AttentionDocument2 pagesSlim and Symmetrical. Every Presentation Will Command AttentionraviezsoftNo ratings yet
- Ctcmanual PDFDocument46 pagesCtcmanual PDFalfonso mateosNo ratings yet
- Flex Circuits Design GuideDocument32 pagesFlex Circuits Design GuideSJLeemans100% (1)
- Sensores de BOSCHDocument210 pagesSensores de BOSCHCoronel-KilgoreNo ratings yet
- User ManualDocument240 pagesUser Manualangel4597No ratings yet
- Cisco It Aci Storage: Aci Plugin For Red Hat Openshift Container Architecture and Design GuideDocument9 pagesCisco It Aci Storage: Aci Plugin For Red Hat Openshift Container Architecture and Design GuideMahmoud RamadanNo ratings yet
- As-Built Survey PDFDocument2 pagesAs-Built Survey PDFKevinNo ratings yet
- Kaspersky Endpoint Security and Management: Technical TrainingDocument145 pagesKaspersky Endpoint Security and Management: Technical TrainingAlex CostacheNo ratings yet
- 2 - Database As A Service - Current Issues and Its Future - Zheng2018Document5 pages2 - Database As A Service - Current Issues and Its Future - Zheng2018Devita PriyadiNo ratings yet
- Rkill Process WhitelistDocument2 pagesRkill Process WhitelistAlekso GjakovskiNo ratings yet
- Apple Vs SamsungDocument6 pagesApple Vs SamsungAshish MyneniNo ratings yet
- Ieee-80 Standard Substation Grid Calculation ExamplesDocument16 pagesIeee-80 Standard Substation Grid Calculation ExamplesAditya PundirNo ratings yet
- POS ProductsDocument5 pagesPOS ProductsEricNo ratings yet
- TX 760d Installation ManualDocument43 pagesTX 760d Installation ManualzachNo ratings yet