
FALLSEM2022-23_CBS1009_ETH_VL2022230104326_2022-11-15_Reference-Material-II
FALLSEM2022-23_CBS1009_ETH_VL2022230104326_2022-11-15_Reference-Material-II
You might also like
- EFSETDocument2 pagesEFSETLilik23% (13)
- 1 Sol PDFDocument4 pages1 Sol PDFsyed.imamNo ratings yet
- Projectile MotionDocument3 pagesProjectile MotionGrace KimNo ratings yet
- FALLSEM2022-23_CBS1009_ETH_VL2022230104326_2022-11-15_Reference-Material-IDocument3 pagesFALLSEM2022-23_CBS1009_ETH_VL2022230104326_2022-11-15_Reference-Material-Iyashwantparihar1702No ratings yet
- Quantum Phase Space Symmetry and Sterile NeutrinosDocument25 pagesQuantum Phase Space Symmetry and Sterile NeutrinosRavo Tokiniaina RanaivosonNo ratings yet
- Vasin 2020Document7 pagesVasin 2020Chatchawan PanraksaNo ratings yet
- Inverse Problem For A Space-Time Generalized Diffusion EquationDocument12 pagesInverse Problem For A Space-Time Generalized Diffusion EquationkamranNo ratings yet
- Determinant and Adjoint of Fuzzy Neutrosophic Soft MatricesDocument17 pagesDeterminant and Adjoint of Fuzzy Neutrosophic Soft MatricesMia AmaliaNo ratings yet
- Chapter 8 - Granger - Causality - Among - Graphs - 4Document5 pagesChapter 8 - Granger - Causality - Among - Graphs - 4Lídia de JesusNo ratings yet
- A New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayDocument6 pagesA New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayWaj DINo ratings yet
- Tensor Analysis - Copy To PDFDocument45 pagesTensor Analysis - Copy To PDFKAVYASKUMAR SKUMARNo ratings yet
- Lecture 1Document6 pagesLecture 1Bredley SilvaNo ratings yet
- WK11 13Document22 pagesWK11 13steven20040616No ratings yet
- Lecture 9 PRINCIPAL COMPONENTSDocument7 pagesLecture 9 PRINCIPAL COMPONENTSTasin Safwath ChowdhuryNo ratings yet
- MA1511 2021S1 Chapter 3 Vector-Valued FunctionsDocument22 pagesMA1511 2021S1 Chapter 3 Vector-Valued FunctionsJustin NgNo ratings yet
- Additional Notes 2 - Correlation and Stationary Time SeriesDocument7 pagesAdditional Notes 2 - Correlation and Stationary Time SeriesrheatrishasantosNo ratings yet
- Wavelength and Wave Period Relationship With Wave Amplitude: A Velocity Potential FormulationDocument7 pagesWavelength and Wave Period Relationship With Wave Amplitude: A Velocity Potential FormulationIJAERS JOURNALNo ratings yet
- Laboratory 5: Discrete Fourier Transform: Instructor: MR Ammar Naseer EE UET New CampusDocument9 pagesLaboratory 5: Discrete Fourier Transform: Instructor: MR Ammar Naseer EE UET New CampusWaleed SaeedNo ratings yet
- Euler Approximation For A Class of Singular Multi-Dimensional Sdes Driven by An Additive Fractional NoiseDocument14 pagesEuler Approximation For A Class of Singular Multi-Dimensional Sdes Driven by An Additive Fractional NoiseTiến Đạt TrầnNo ratings yet
- Stochastic Differential Equations With Multi-MarkoDocument12 pagesStochastic Differential Equations With Multi-MarkoِAhmed Jebur AliNo ratings yet
- Subtraction and Division of Neutrosophic NumbersDocument8 pagesSubtraction and Division of Neutrosophic NumbersMia AmaliaNo ratings yet
- Week 5 - EViews Practice NoteDocument16 pagesWeek 5 - EViews Practice NoteChip choiNo ratings yet
- Stochastics NotesDocument19 pagesStochastics Notesvishalmundhe494No ratings yet
- An Exact Derivation of The Thomas Precession RateDocument11 pagesAn Exact Derivation of The Thomas Precession RateALEX sponsoredNo ratings yet
- Lecture 4Document5 pagesLecture 4Kaveesha JayasuriyaNo ratings yet
- Com Solved Proble4ms IDocument6 pagesCom Solved Proble4ms INatyBNo ratings yet
- Finite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationDocument6 pagesFinite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Ajms 482 23Document7 pagesAjms 482 23BRNSS Publication Hub InfoNo ratings yet
- Module 3Document78 pagesModule 3MEGHANA R 20BEC1042No ratings yet
- Matrix-Based RSA Encryption of Streaming Data Prendergast 20210804Document15 pagesMatrix-Based RSA Encryption of Streaming Data Prendergast 20210804Mohammed Nadeemullah NNo ratings yet
- 4.2 The Mean Value Theorem - Mathematics LibreTextsDocument9 pages4.2 The Mean Value Theorem - Mathematics LibreTextsloooNo ratings yet
- Chapter CFDDocument6 pagesChapter CFDAnonymous XzqXVMjNo ratings yet
- 3 - WQU - 622 CTSP - M3 - CompiledContentDocument31 pages3 - WQU - 622 CTSP - M3 - CompiledContentJoe Ng100% (1)
- 5 Matrix Form of Linear Transformations, Column and Row Space of A MatrixDocument19 pages5 Matrix Form of Linear Transformations, Column and Row Space of A MatrixKaveesha JayasuriyaNo ratings yet
- WQU - Econometrics - Module2 - Compiled ContentDocument73 pagesWQU - Econometrics - Module2 - Compiled ContentYumiko Huang100% (1)
- MA1511 Chapter 3Document20 pagesMA1511 Chapter 3Kang Le LimNo ratings yet
- MATERIAL DE ESTUDIO HUMANIDADES UNI 2024Document4 pagesMATERIAL DE ESTUDIO HUMANIDADES UNI 2024Johnny PalomaresNo ratings yet
- Estimation of Mean Vector and Variance Covariance Matrix PDFDocument7 pagesEstimation of Mean Vector and Variance Covariance Matrix PDFMohammed AdelNo ratings yet
- Tarea 1Document6 pagesTarea 1jorge esteban guerraNo ratings yet
- ECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounDocument23 pagesECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounKen ZhengNo ratings yet
- Week 8 SlidesDocument82 pagesWeek 8 Slides5s5tbgtfyqNo ratings yet
- Some Properties of M-Accretive Operators in Normed Spaces: Christina Kartika SariDocument8 pagesSome Properties of M-Accretive Operators in Normed Spaces: Christina Kartika SariSakti AnupindiNo ratings yet
- 3D Dynamics - 0103 - Fundamentals of Kinematics - Motion Path KinematicsDocument7 pages3D Dynamics - 0103 - Fundamentals of Kinematics - Motion Path Kinematicssangram6957No ratings yet
- Interduction: Trapezoidal RuleDocument5 pagesInterduction: Trapezoidal RuleanandNo ratings yet
- Skew NessDocument13 pagesSkew NessBibek GaireNo ratings yet
- 2 - WQU - CTSP - Module 2 - Compiled - Content PDFDocument48 pages2 - WQU - CTSP - Module 2 - Compiled - Content PDFJoe NgNo ratings yet
- Foundation of Appurtenance and Inclusion Equations For Constructing The Operations of Neutrosophic Numbers Needed in Neutrosophic StatisticsDocument17 pagesFoundation of Appurtenance and Inclusion Equations For Constructing The Operations of Neutrosophic Numbers Needed in Neutrosophic StatisticsScience DirectNo ratings yet
- Week 2 Cross Product Line and Plane in 3-SpaceDocument4 pagesWeek 2 Cross Product Line and Plane in 3-SpaceBirru Asia RayaniNo ratings yet
- Statistical Inference 2 Note 02Document7 pagesStatistical Inference 2 Note 02ElelanNo ratings yet
- A Survey On The Dai-Liao Family of Nonlinear Conjugate Gradient MethodsDocument16 pagesA Survey On The Dai-Liao Family of Nonlinear Conjugate Gradient Methodsهشام محمد خضرNo ratings yet
- An Introduction To Eigenvalues and Eigenvectors: A Project ReportDocument16 pagesAn Introduction To Eigenvalues and Eigenvectors: A Project ReportUjjal Kumar NandaNo ratings yet
- cs6359_hw1_with_hints (1)Document2 pagescs6359_hw1_with_hints (1)karan katariaNo ratings yet
- TSWJJHJHJKHG6Document6 pagesTSWJJHJHJKHG6Abdelkader RabahNo ratings yet
- Chapter 5Document5 pagesChapter 5hussein mohammedNo ratings yet
- Absorber Design Part2 Interphase Mass Transfer Rev3Document19 pagesAbsorber Design Part2 Interphase Mass Transfer Rev3Loyibo EmmanuelNo ratings yet
- Matrix-Factorization (3) KPDocument5 pagesMatrix-Factorization (3) KPrigersa ersaNo ratings yet
- Some Fourier Theory For Time Series AnalysisDocument12 pagesSome Fourier Theory For Time Series AnalysisDaniela Guerrero PeñaNo ratings yet
- Reliability Analysis of Welds in Nuclear Power Plant Reactor VesselsDocument39 pagesReliability Analysis of Welds in Nuclear Power Plant Reactor VesselsPratik TagwaleNo ratings yet
- Understanding Vector Calculus: Practical Development and Solved ProblemsFrom EverandUnderstanding Vector Calculus: Practical Development and Solved ProblemsNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- Surface Chemistry in The Atomic Layer Deposition of TiN Films From TiCl4 and AmmoniaDocument8 pagesSurface Chemistry in The Atomic Layer Deposition of TiN Films From TiCl4 and AmmoniaThang NguyenNo ratings yet
- G 173 - 03 - Rze3mwDocument20 pagesG 173 - 03 - Rze3mwkranthi kumarNo ratings yet
- A Novel Arc Model For Very Fast Transient Overvoltage Simulation in A 252-kV Gas-Insulated SwitchgearDocument7 pagesA Novel Arc Model For Very Fast Transient Overvoltage Simulation in A 252-kV Gas-Insulated SwitchgearRoberto SuNo ratings yet
- DLP ProjectorDocument24 pagesDLP ProjectorKash SinghNo ratings yet
- A Reformulated Hardening Soil Model - BowerDocument19 pagesA Reformulated Hardening Soil Model - BowerVicente CapaNo ratings yet
- Grade 12 Gen Physics Module Week 2Document6 pagesGrade 12 Gen Physics Module Week 2leslie mermeloNo ratings yet
- B CoefficientDocument62 pagesB CoefficientmkdkdNo ratings yet
- Danfoss 1 NL73FT - Oc - R134a - 220v - 50hz - 08-2004 - Ed400q102Document2 pagesDanfoss 1 NL73FT - Oc - R134a - 220v - 50hz - 08-2004 - Ed400q102Hikmat KtkNo ratings yet
- Correction Taping DistancesDocument10 pagesCorrection Taping DistancesMaria Olivia GabionzaNo ratings yet
- UgušćivačiDocument3 pagesUgušćivačislavica_restauroNo ratings yet
- HYTEKDocument1 pageHYTEKHeather MurphyNo ratings yet
- Astm D 4052-11Document8 pagesAstm D 4052-11UmarFidaNo ratings yet
- Redes EjemplosDocument17 pagesRedes EjemplosRodrigo VelazquesNo ratings yet
- DatasheetDocument2 pagesDatasheetJORGENo ratings yet
- Damengineering BookDocument109 pagesDamengineering BookPenelope MalilweNo ratings yet
- Passive DNAPL Recovery - A Fact SheetDocument1 pagePassive DNAPL Recovery - A Fact SheetNYCer 007No ratings yet
- Book TotDocument39 pagesBook TotwentropremNo ratings yet
- Unit - I: Two Mark Questions & AnswersDocument8 pagesUnit - I: Two Mark Questions & Answerssmg26thmayNo ratings yet
- Sample: Exhibit 1 Exhibit 1Document1 pageSample: Exhibit 1 Exhibit 1jessy eghNo ratings yet
- 2 Motion in A Circle: Answers To Exam Practice QuestionsDocument4 pages2 Motion in A Circle: Answers To Exam Practice QuestionsKoe ChoNo ratings yet
- PH Dan Larutan PenyanggaDocument38 pagesPH Dan Larutan PenyanggaSri Novita YandaNo ratings yet
- Heat Reflecting PaintsDocument13 pagesHeat Reflecting PaintsEsau AguillónNo ratings yet
- Unsolved Problems (Math)Document2 pagesUnsolved Problems (Math)Chan FamilyNo ratings yet
- John Paul V. Tobias: PRC LICENSE NO.: 0149412 PTR NO: 4505447 Issued At: Licab, Nueva EcijaDocument3 pagesJohn Paul V. Tobias: PRC LICENSE NO.: 0149412 PTR NO: 4505447 Issued At: Licab, Nueva EcijaAnonymous QUkf702No ratings yet
- Use of Bead MillsDocument2 pagesUse of Bead MillsbalupostNo ratings yet
- AUDIDocument4 pagesAUDINagesh ReddyNo ratings yet
- Display ImageDocument1 pageDisplay Imageshreyasghosh515No ratings yet

























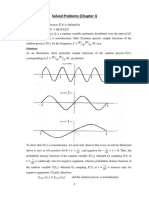































































Download as pdf or txt
You might also like
- EFSETDocument2 pagesEFSETLilik23% (13)
- 1 Sol PDFDocument4 pages1 Sol PDFsyed.imamNo ratings yet
- Projectile MotionDocument3 pagesProjectile MotionGrace KimNo ratings yet
- FALLSEM2022-23_CBS1009_ETH_VL2022230104326_2022-11-15_Reference-Material-IDocument3 pagesFALLSEM2022-23_CBS1009_ETH_VL2022230104326_2022-11-15_Reference-Material-Iyashwantparihar1702No ratings yet
- Quantum Phase Space Symmetry and Sterile NeutrinosDocument25 pagesQuantum Phase Space Symmetry and Sterile NeutrinosRavo Tokiniaina RanaivosonNo ratings yet
- Vasin 2020Document7 pagesVasin 2020Chatchawan PanraksaNo ratings yet
- Inverse Problem For A Space-Time Generalized Diffusion EquationDocument12 pagesInverse Problem For A Space-Time Generalized Diffusion EquationkamranNo ratings yet
- Determinant and Adjoint of Fuzzy Neutrosophic Soft MatricesDocument17 pagesDeterminant and Adjoint of Fuzzy Neutrosophic Soft MatricesMia AmaliaNo ratings yet
- Chapter 8 - Granger - Causality - Among - Graphs - 4Document5 pagesChapter 8 - Granger - Causality - Among - Graphs - 4Lídia de JesusNo ratings yet
- A New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayDocument6 pagesA New Exponentially Stable Sliding Mode Control Approach For A Class of Uncertain Discrete Systems With Time DelayWaj DINo ratings yet
- Tensor Analysis - Copy To PDFDocument45 pagesTensor Analysis - Copy To PDFKAVYASKUMAR SKUMARNo ratings yet
- Lecture 1Document6 pagesLecture 1Bredley SilvaNo ratings yet
- WK11 13Document22 pagesWK11 13steven20040616No ratings yet
- Lecture 9 PRINCIPAL COMPONENTSDocument7 pagesLecture 9 PRINCIPAL COMPONENTSTasin Safwath ChowdhuryNo ratings yet
- MA1511 2021S1 Chapter 3 Vector-Valued FunctionsDocument22 pagesMA1511 2021S1 Chapter 3 Vector-Valued FunctionsJustin NgNo ratings yet
- Additional Notes 2 - Correlation and Stationary Time SeriesDocument7 pagesAdditional Notes 2 - Correlation and Stationary Time SeriesrheatrishasantosNo ratings yet
- Wavelength and Wave Period Relationship With Wave Amplitude: A Velocity Potential FormulationDocument7 pagesWavelength and Wave Period Relationship With Wave Amplitude: A Velocity Potential FormulationIJAERS JOURNALNo ratings yet
- Laboratory 5: Discrete Fourier Transform: Instructor: MR Ammar Naseer EE UET New CampusDocument9 pagesLaboratory 5: Discrete Fourier Transform: Instructor: MR Ammar Naseer EE UET New CampusWaleed SaeedNo ratings yet
- Euler Approximation For A Class of Singular Multi-Dimensional Sdes Driven by An Additive Fractional NoiseDocument14 pagesEuler Approximation For A Class of Singular Multi-Dimensional Sdes Driven by An Additive Fractional NoiseTiến Đạt TrầnNo ratings yet
- Stochastic Differential Equations With Multi-MarkoDocument12 pagesStochastic Differential Equations With Multi-MarkoِAhmed Jebur AliNo ratings yet
- Subtraction and Division of Neutrosophic NumbersDocument8 pagesSubtraction and Division of Neutrosophic NumbersMia AmaliaNo ratings yet
- Week 5 - EViews Practice NoteDocument16 pagesWeek 5 - EViews Practice NoteChip choiNo ratings yet
- Stochastics NotesDocument19 pagesStochastics Notesvishalmundhe494No ratings yet
- An Exact Derivation of The Thomas Precession RateDocument11 pagesAn Exact Derivation of The Thomas Precession RateALEX sponsoredNo ratings yet
- Lecture 4Document5 pagesLecture 4Kaveesha JayasuriyaNo ratings yet
- Com Solved Proble4ms IDocument6 pagesCom Solved Proble4ms INatyBNo ratings yet
- Finite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationDocument6 pagesFinite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Ajms 482 23Document7 pagesAjms 482 23BRNSS Publication Hub InfoNo ratings yet
- Module 3Document78 pagesModule 3MEGHANA R 20BEC1042No ratings yet
- Matrix-Based RSA Encryption of Streaming Data Prendergast 20210804Document15 pagesMatrix-Based RSA Encryption of Streaming Data Prendergast 20210804Mohammed Nadeemullah NNo ratings yet
- 4.2 The Mean Value Theorem - Mathematics LibreTextsDocument9 pages4.2 The Mean Value Theorem - Mathematics LibreTextsloooNo ratings yet
- Chapter CFDDocument6 pagesChapter CFDAnonymous XzqXVMjNo ratings yet
- 3 - WQU - 622 CTSP - M3 - CompiledContentDocument31 pages3 - WQU - 622 CTSP - M3 - CompiledContentJoe Ng100% (1)
- 5 Matrix Form of Linear Transformations, Column and Row Space of A MatrixDocument19 pages5 Matrix Form of Linear Transformations, Column and Row Space of A MatrixKaveesha JayasuriyaNo ratings yet
- WQU - Econometrics - Module2 - Compiled ContentDocument73 pagesWQU - Econometrics - Module2 - Compiled ContentYumiko Huang100% (1)
- MA1511 Chapter 3Document20 pagesMA1511 Chapter 3Kang Le LimNo ratings yet
- MATERIAL DE ESTUDIO HUMANIDADES UNI 2024Document4 pagesMATERIAL DE ESTUDIO HUMANIDADES UNI 2024Johnny PalomaresNo ratings yet
- Estimation of Mean Vector and Variance Covariance Matrix PDFDocument7 pagesEstimation of Mean Vector and Variance Covariance Matrix PDFMohammed AdelNo ratings yet
- Tarea 1Document6 pagesTarea 1jorge esteban guerraNo ratings yet
- ECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounDocument23 pagesECE 3040 Lecture 9: Taylor Series Approximation II: © Prof. Mohamad HassounKen ZhengNo ratings yet
- Week 8 SlidesDocument82 pagesWeek 8 Slides5s5tbgtfyqNo ratings yet
- Some Properties of M-Accretive Operators in Normed Spaces: Christina Kartika SariDocument8 pagesSome Properties of M-Accretive Operators in Normed Spaces: Christina Kartika SariSakti AnupindiNo ratings yet
- 3D Dynamics - 0103 - Fundamentals of Kinematics - Motion Path KinematicsDocument7 pages3D Dynamics - 0103 - Fundamentals of Kinematics - Motion Path Kinematicssangram6957No ratings yet
- Interduction: Trapezoidal RuleDocument5 pagesInterduction: Trapezoidal RuleanandNo ratings yet
- Skew NessDocument13 pagesSkew NessBibek GaireNo ratings yet
- 2 - WQU - CTSP - Module 2 - Compiled - Content PDFDocument48 pages2 - WQU - CTSP - Module 2 - Compiled - Content PDFJoe NgNo ratings yet
- Foundation of Appurtenance and Inclusion Equations For Constructing The Operations of Neutrosophic Numbers Needed in Neutrosophic StatisticsDocument17 pagesFoundation of Appurtenance and Inclusion Equations For Constructing The Operations of Neutrosophic Numbers Needed in Neutrosophic StatisticsScience DirectNo ratings yet
- Week 2 Cross Product Line and Plane in 3-SpaceDocument4 pagesWeek 2 Cross Product Line and Plane in 3-SpaceBirru Asia RayaniNo ratings yet
- Statistical Inference 2 Note 02Document7 pagesStatistical Inference 2 Note 02ElelanNo ratings yet
- A Survey On The Dai-Liao Family of Nonlinear Conjugate Gradient MethodsDocument16 pagesA Survey On The Dai-Liao Family of Nonlinear Conjugate Gradient Methodsهشام محمد خضرNo ratings yet
- An Introduction To Eigenvalues and Eigenvectors: A Project ReportDocument16 pagesAn Introduction To Eigenvalues and Eigenvectors: A Project ReportUjjal Kumar NandaNo ratings yet
- cs6359_hw1_with_hints (1)Document2 pagescs6359_hw1_with_hints (1)karan katariaNo ratings yet
- TSWJJHJHJKHG6Document6 pagesTSWJJHJHJKHG6Abdelkader RabahNo ratings yet
- Chapter 5Document5 pagesChapter 5hussein mohammedNo ratings yet
- Absorber Design Part2 Interphase Mass Transfer Rev3Document19 pagesAbsorber Design Part2 Interphase Mass Transfer Rev3Loyibo EmmanuelNo ratings yet
- Matrix-Factorization (3) KPDocument5 pagesMatrix-Factorization (3) KPrigersa ersaNo ratings yet
- Some Fourier Theory For Time Series AnalysisDocument12 pagesSome Fourier Theory For Time Series AnalysisDaniela Guerrero PeñaNo ratings yet
- Reliability Analysis of Welds in Nuclear Power Plant Reactor VesselsDocument39 pagesReliability Analysis of Welds in Nuclear Power Plant Reactor VesselsPratik TagwaleNo ratings yet
- Understanding Vector Calculus: Practical Development and Solved ProblemsFrom EverandUnderstanding Vector Calculus: Practical Development and Solved ProblemsNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- Surface Chemistry in The Atomic Layer Deposition of TiN Films From TiCl4 and AmmoniaDocument8 pagesSurface Chemistry in The Atomic Layer Deposition of TiN Films From TiCl4 and AmmoniaThang NguyenNo ratings yet
- G 173 - 03 - Rze3mwDocument20 pagesG 173 - 03 - Rze3mwkranthi kumarNo ratings yet
- A Novel Arc Model For Very Fast Transient Overvoltage Simulation in A 252-kV Gas-Insulated SwitchgearDocument7 pagesA Novel Arc Model For Very Fast Transient Overvoltage Simulation in A 252-kV Gas-Insulated SwitchgearRoberto SuNo ratings yet
- DLP ProjectorDocument24 pagesDLP ProjectorKash SinghNo ratings yet
- A Reformulated Hardening Soil Model - BowerDocument19 pagesA Reformulated Hardening Soil Model - BowerVicente CapaNo ratings yet
- Grade 12 Gen Physics Module Week 2Document6 pagesGrade 12 Gen Physics Module Week 2leslie mermeloNo ratings yet
- B CoefficientDocument62 pagesB CoefficientmkdkdNo ratings yet
- Danfoss 1 NL73FT - Oc - R134a - 220v - 50hz - 08-2004 - Ed400q102Document2 pagesDanfoss 1 NL73FT - Oc - R134a - 220v - 50hz - 08-2004 - Ed400q102Hikmat KtkNo ratings yet
- Correction Taping DistancesDocument10 pagesCorrection Taping DistancesMaria Olivia GabionzaNo ratings yet
- UgušćivačiDocument3 pagesUgušćivačislavica_restauroNo ratings yet
- HYTEKDocument1 pageHYTEKHeather MurphyNo ratings yet
- Astm D 4052-11Document8 pagesAstm D 4052-11UmarFidaNo ratings yet
- Redes EjemplosDocument17 pagesRedes EjemplosRodrigo VelazquesNo ratings yet
- DatasheetDocument2 pagesDatasheetJORGENo ratings yet
- Damengineering BookDocument109 pagesDamengineering BookPenelope MalilweNo ratings yet
- Passive DNAPL Recovery - A Fact SheetDocument1 pagePassive DNAPL Recovery - A Fact SheetNYCer 007No ratings yet
- Book TotDocument39 pagesBook TotwentropremNo ratings yet
- Unit - I: Two Mark Questions & AnswersDocument8 pagesUnit - I: Two Mark Questions & Answerssmg26thmayNo ratings yet
- Sample: Exhibit 1 Exhibit 1Document1 pageSample: Exhibit 1 Exhibit 1jessy eghNo ratings yet
- 2 Motion in A Circle: Answers To Exam Practice QuestionsDocument4 pages2 Motion in A Circle: Answers To Exam Practice QuestionsKoe ChoNo ratings yet
- PH Dan Larutan PenyanggaDocument38 pagesPH Dan Larutan PenyanggaSri Novita YandaNo ratings yet
- Heat Reflecting PaintsDocument13 pagesHeat Reflecting PaintsEsau AguillónNo ratings yet
- Unsolved Problems (Math)Document2 pagesUnsolved Problems (Math)Chan FamilyNo ratings yet
- John Paul V. Tobias: PRC LICENSE NO.: 0149412 PTR NO: 4505447 Issued At: Licab, Nueva EcijaDocument3 pagesJohn Paul V. Tobias: PRC LICENSE NO.: 0149412 PTR NO: 4505447 Issued At: Licab, Nueva EcijaAnonymous QUkf702No ratings yet
- Use of Bead MillsDocument2 pagesUse of Bead MillsbalupostNo ratings yet
- AUDIDocument4 pagesAUDINagesh ReddyNo ratings yet
- Display ImageDocument1 pageDisplay Imageshreyasghosh515No ratings yet