Download as pdf or txt
You might also like
- AB SG Unit 2 Progress Check MCQ Part BDocument7 pagesAB SG Unit 2 Progress Check MCQ Part Bsc100% (2)
- Unit 5 Polynomials PRACTICE Test (Ver.11-09-A)Document4 pagesUnit 5 Polynomials PRACTICE Test (Ver.11-09-A)Arthur Capawing100% (1)
- Notes FunctionsDocument2 pagesNotes FunctionsBathandwa ThembaNo ratings yet
- Enrichment Polya Problem ExcerptDocument8 pagesEnrichment Polya Problem ExcerptzosifhanwgcNo ratings yet
- Introduction To Fourier Analysis: 1.1 TextDocument7 pagesIntroduction To Fourier Analysis: 1.1 TextAshoka VanjareNo ratings yet
- Introduction To Fourier Analysis: 1.1 TextDocument70 pagesIntroduction To Fourier Analysis: 1.1 TextAshoka VanjareNo ratings yet
- Function ConceptDocument12 pagesFunction ConceptÊlkîn BrnâlNo ratings yet
- Absalg 1Document136 pagesAbsalg 1Jason Andres Diaz SuarezNo ratings yet
- English For Mathematics-ThuyDocument34 pagesEnglish For Mathematics-ThuyChiến TrầnNo ratings yet
- Inyection and Surjection PDFDocument3 pagesInyection and Surjection PDFsoviNo ratings yet
- Math1059 - CalculusDocument98 pagesMath1059 - CalculusRaya Mancheva100% (1)
- Functions OntoDocument11 pagesFunctions OntoMuhammad WaqasNo ratings yet
- Lesson 1 - Gen MathDocument11 pagesLesson 1 - Gen MathAaliyah MabalotNo ratings yet
- Functions and GraphsDocument4 pagesFunctions and GraphsS.m. ChandrashekarNo ratings yet
- ch00 Ma1300Document5 pagesch00 Ma1300rimskysNo ratings yet
- CH 00Document5 pagesCH 00Nanxiang ChenNo ratings yet
- Functions: 4.1 Definition of Functions As MappingsDocument10 pagesFunctions: 4.1 Definition of Functions As MappingsMehwish FatimaNo ratings yet
- Elementary FunctionsDocument6 pagesElementary FunctionsHoàng Thành NguyễnNo ratings yet
- CS30L7 HandoutDocument7 pagesCS30L7 HandoutRace CariNo ratings yet
- Study Notes 3 - Functions:: Domain Codomain Rule 1 - 1 OntoDocument3 pagesStudy Notes 3 - Functions:: Domain Codomain Rule 1 - 1 OntoYoni MacNo ratings yet
- MTS 241 (First)Document16 pagesMTS 241 (First)Bello TaiwoNo ratings yet
- MTS 241...Document21 pagesMTS 241...Bello TaiwoNo ratings yet
- TEMA 0. Review On CalculusDocument12 pagesTEMA 0. Review On CalculusMaría VelaNo ratings yet
- MODULE 1 CE Math107EDocument12 pagesMODULE 1 CE Math107EAxl TorrilloNo ratings yet
- University of Zimbabwe: Mte 101 Engineering Mathematics 1Document21 pagesUniversity of Zimbabwe: Mte 101 Engineering Mathematics 1makjnrNo ratings yet
- Homework 10 SolutionsDocument3 pagesHomework 10 SolutionsadaNo ratings yet
- Difference Calculus: N K 1 3 M X 1 N y 1 2 N K 0 KDocument9 pagesDifference Calculus: N K 1 3 M X 1 N y 1 2 N K 0 KAline GuedesNo ratings yet
- Functions Sheet SolutionsDocument12 pagesFunctions Sheet SolutionsAhmedbacha AbdelkaderNo ratings yet
- Functional EqnsDocument7 pagesFunctional Eqnskhanh truongNo ratings yet
- Function and PolynomialsDocument8 pagesFunction and PolynomialsJaishree RamNo ratings yet
- Algebra-6 FULLDocument22 pagesAlgebra-6 FULLRaman SharmaNo ratings yet
- M201, Real Analysis Fall 2019 Mid Term Exam Time: Two Hours Maximum Score: 45Document9 pagesM201, Real Analysis Fall 2019 Mid Term Exam Time: Two Hours Maximum Score: 45polar necksonNo ratings yet
- Group Theory and The Rubik's CubeDocument39 pagesGroup Theory and The Rubik's CubeKyle BotabaraNo ratings yet
- Lesson 4 Functions: 1. Basic ConceptsDocument6 pagesLesson 4 Functions: 1. Basic ConceptsmercedeslopezNo ratings yet
- Dyn 1Document7 pagesDyn 1HarshitNo ratings yet
- Discrete Structures L5: Functions and AlgorithmsDocument25 pagesDiscrete Structures L5: Functions and AlgorithmsSomaiah SulaimanNo ratings yet
- Proofs With Functions: 1 RecapDocument4 pagesProofs With Functions: 1 RecapDaphane Kate AureadaNo ratings yet
- Notes 2443 Week 1Document3 pagesNotes 2443 Week 1visaggan sivabalanNo ratings yet
- Module 1. Functions and Their GraphsDocument7 pagesModule 1. Functions and Their GraphsMori OugaiNo ratings yet
- 22 Reimann in DetailDocument75 pages22 Reimann in DetailManovki WasadeNo ratings yet
- 1.1 The Cartesian Coordinate SpaceDocument4 pages1.1 The Cartesian Coordinate SpaceArunabh SinghNo ratings yet
- Differentiation and Its Application Department of Mathematics NOVEMBER, 2012 Table of ContentDocument35 pagesDifferentiation and Its Application Department of Mathematics NOVEMBER, 2012 Table of ContentFSahuNo ratings yet
- Chp. (1) Function ConceptsDocument32 pagesChp. (1) Function Conceptsahmed e.aliNo ratings yet
- Diff - Calc - Module-1-Functions Limits ContinuityDocument17 pagesDiff - Calc - Module-1-Functions Limits ContinuityCiline FranciscoNo ratings yet
- Oscar de Witt 17-17Document1 pageOscar de Witt 17-17chengpeckNo ratings yet
- Functions: Definition 1.2.1Document17 pagesFunctions: Definition 1.2.1Javian CampbellNo ratings yet
- Darius Grinberg Mathematical Reasoning SeriesDocument14 pagesDarius Grinberg Mathematical Reasoning SeriesBrandon JayNo ratings yet
- Introduction: in Nearly Every Physical Phenomenon We Observe That One Quantity DependsDocument10 pagesIntroduction: in Nearly Every Physical Phenomenon We Observe That One Quantity DependsbushraNo ratings yet
- 1.partial DifferentiationDocument23 pages1.partial DifferentiationPratyush SrivastavaNo ratings yet
- 9 Ffields PDFDocument9 pages9 Ffields PDFAakankshaChhaviNo ratings yet
- The Quest For Functions. Functional Equations For The Beginners - Vaderlind P. (2005) PDFDocument46 pagesThe Quest For Functions. Functional Equations For The Beginners - Vaderlind P. (2005) PDFKanchit SaehoNo ratings yet
- Chapter 3Document25 pagesChapter 3minoufisli1No ratings yet
- Multi VarDocument17 pagesMulti VarDaniel CesareNo ratings yet
- Functions and Graphs HSNDocument16 pagesFunctions and Graphs HSNapi-298592212No ratings yet
- (Lecture Notes) Chapter 3.1 3.3Document70 pages(Lecture Notes) Chapter 3.1 3.34n63l4641No ratings yet
- Functions Class 12Document60 pagesFunctions Class 12Gunasekar GopalNo ratings yet
- Module-1 AbstractDocument11 pagesModule-1 AbstractMark Rolando Semaña TabbuNo ratings yet
- CalculusDocument8 pagesCalculusAngela Laine HiponiaNo ratings yet
- DSP Lab ReportDocument28 pagesDSP Lab ReportKaaviyaNo ratings yet
- LINEAR ALGEBRA AND COMPLEX ANALYSIS S3 B.Tech May 2019 R & S - Ktu QbankDocument2 pagesLINEAR ALGEBRA AND COMPLEX ANALYSIS S3 B.Tech May 2019 R & S - Ktu QbankSalim S HameedNo ratings yet
- Module Matrices NotesDocument22 pagesModule Matrices Noteschris brownNo ratings yet
- All About FunctionsDocument51 pagesAll About FunctionsEIy SantiasNo ratings yet
- Chapter 2Document18 pagesChapter 2Von Eric DamirezNo ratings yet
- Assignment 11 Answers Math 130 Linear AlgebraDocument3 pagesAssignment 11 Answers Math 130 Linear AlgebraCody SageNo ratings yet
- Complex Function DerivativesDocument3 pagesComplex Function DerivativesDennis TooNo ratings yet
- Dec 14 2009Document75 pagesDec 14 2009riponNo ratings yet
- 2223 Level LS Mathematics Algebra 4 Course Questions SolutionsDocument94 pages2223 Level LS Mathematics Algebra 4 Course Questions SolutionsFeras SrourNo ratings yet
- College Algebra 10th Edition Larson Solutions ManualDocument25 pagesCollege Algebra 10th Edition Larson Solutions ManualDebbieCollinsgoikm100% (67)
- Calculus II SyllabusDocument2 pagesCalculus II SyllabusMiliyon TilahunNo ratings yet
- Edexcel IAL P2 Exercise 6C (Solution)Document5 pagesEdexcel IAL P2 Exercise 6C (Solution)Kaif HasanNo ratings yet
- Lecture Notes On Linear Algebra - Kuwait UniDocument149 pagesLecture Notes On Linear Algebra - Kuwait Unimya queNo ratings yet
- Matrices and Matrix OperationsDocument12 pagesMatrices and Matrix OperationsAzhar SuharjiantoNo ratings yet
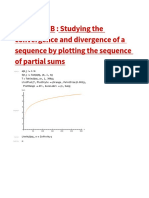
- Practical 2B: Studying The Convergence and Divergence of A Sequence by Plotting The Sequence of Partial SumsDocument3 pagesPractical 2B: Studying The Convergence and Divergence of A Sequence by Plotting The Sequence of Partial SumsPraveen KumarNo ratings yet
- Dynamic Interpretation of EignevlaueDocument25 pagesDynamic Interpretation of EignevlaueGareth VioNo ratings yet
- Integration: Self Learning Home Task (SLHT)Document4 pagesIntegration: Self Learning Home Task (SLHT)ZedNo ratings yet
- IDP Math-103 Integ-Calc Oliver 2s-22-23Document3 pagesIDP Math-103 Integ-Calc Oliver 2s-22-23YanieNo ratings yet
- Lesson 6 MatricesDocument4 pagesLesson 6 MatricesAbdihakim MohamedNo ratings yet
- Chapter 2 - Matrix AlgebraDocument89 pagesChapter 2 - Matrix AlgebraCao Bằng Thảo NguyênNo ratings yet
- Sample 8066Document11 pagesSample 8066RajibNo ratings yet
- Convex OptimizationDocument152 pagesConvex OptimizationnudalaNo ratings yet
- 1.induction & 2.matrixDocument76 pages1.induction & 2.matrixkurdkNo ratings yet
- John RainwaterDocument4 pagesJohn RainwaterAlHazredNo ratings yet
- 2-03-Hilbert SpaceDocument16 pages2-03-Hilbert SpaceMalik Haseeb Malik HaseebNo ratings yet
- Chap4 - Functions, Pigeonhole PrincipleDocument31 pagesChap4 - Functions, Pigeonhole PrincipleDorian GreyNo ratings yet
- PS7 SolnDocument3 pagesPS7 SolnJivnesh Sandhan50% (2)
- Survey of Finite Element Shape FunctionsDocument9 pagesSurvey of Finite Element Shape FunctionsvtalatsNo ratings yet