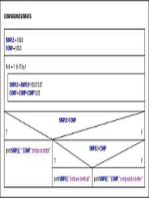
Download as pdf or txt
You might also like
- Catalogue-Mitutoyo-2022 Final Ok PDFDocument638 pagesCatalogue-Mitutoyo-2022 Final Ok PDFHuỳnh Quốc DũngNo ratings yet
- Software Testing Principles and PracticesDocument674 pagesSoftware Testing Principles and PracticesTiago Martins100% (1)
- Hobart Handler 175 220 VAC MIG Welder User Manual O944 - HobDocument48 pagesHobart Handler 175 220 VAC MIG Welder User Manual O944 - HobrbastaNo ratings yet
- Artificial Intelligence and Machine LearningDocument19 pagesArtificial Intelligence and Machine LearningHIRAL AMARNATH YADAVNo ratings yet
- Problems, Problem Spaces and SearchDocument11 pagesProblems, Problem Spaces and Searchsi89No ratings yet
- Chapter-2 Search and Constraint Specifications: Intelligent SystemDocument15 pagesChapter-2 Search and Constraint Specifications: Intelligent SystemBhargavNo ratings yet
- Artificial IntelligenceDocument106 pagesArtificial IntelligenceCharith RcNo ratings yet
- Problems, Problem Spaces and Search: 1 Prof. L. B. Damahe, CT, YCCEDocument58 pagesProblems, Problem Spaces and Search: 1 Prof. L. B. Damahe, CT, YCCEyoutube channelNo ratings yet
- Artificial Intelligence WINTER 2021 SOLU.Document15 pagesArtificial Intelligence WINTER 2021 SOLU.VivekNo ratings yet
- Chapter 2 Problem State Space Search - Heuristic Search TechniquesDocument56 pagesChapter 2 Problem State Space Search - Heuristic Search TechniquesImran SNo ratings yet
- Syllabus: What Is Artificial Intelligence? ProblemsDocument66 pagesSyllabus: What Is Artificial Intelligence? ProblemsUdupiSri groupNo ratings yet
- Ai Chapter 2Document24 pagesAi Chapter 2d2gb6whnd9No ratings yet
- Unit 2 - Part 1Document67 pagesUnit 2 - Part 1Priyal PatelNo ratings yet
- P, P S A S: Roblems Roblem Paces ND EarchDocument52 pagesP, P S A S: Roblems Roblem Paces ND EarchPrakhar PathakNo ratings yet
- Unit 2a PROBLEM SOLVING TECHNIQUES - Uninformed Search PDFDocument65 pagesUnit 2a PROBLEM SOLVING TECHNIQUES - Uninformed Search PDFMadhav ChaudharyNo ratings yet
- Artificial Intelligence SUMMER 2022 SOLU.Document14 pagesArtificial Intelligence SUMMER 2022 SOLU.VivekNo ratings yet
- Artificial Intelligence Module-1 Chapter 2 & 3: AI/JB/ISE/SIT/2019-20Document100 pagesArtificial Intelligence Module-1 Chapter 2 & 3: AI/JB/ISE/SIT/2019-20Charith RcNo ratings yet
- Problems, Problem Spaces and SearchDocument54 pagesProblems, Problem Spaces and SearchTania CENo ratings yet
- AI ProblemsDocument46 pagesAI ProblemsLini IckappanNo ratings yet
- Problems, Problem Space N Search (Lecture 6-11)Document86 pagesProblems, Problem Space N Search (Lecture 6-11)Roshan Mishra100% (1)
- L2 Prob Solving 07Document30 pagesL2 Prob Solving 07Aman VermaNo ratings yet
- Unit 1 - Ai - KCS071Document32 pagesUnit 1 - Ai - KCS071Minal SinghNo ratings yet
- Unit I-AiDocument31 pagesUnit I-Aigunalan gNo ratings yet
- FAI - Unit-2 - State Space Search & Heuristic Search TechniquesDocument19 pagesFAI - Unit-2 - State Space Search & Heuristic Search TechniquesSR SRNo ratings yet
- Unit-2: Problems, State Space Search & HeuristicDocument64 pagesUnit-2: Problems, State Space Search & Heuristic131 nancyNo ratings yet
- What Is Artificial IntelligenceDocument18 pagesWhat Is Artificial IntelligenceRajkumar DharmarajNo ratings yet
- Unit - 2 AiDocument66 pagesUnit - 2 Aichandru kNo ratings yet
- Production System State-Space Formulation: Representation of Problem and Its SolutionDocument29 pagesProduction System State-Space Formulation: Representation of Problem and Its SolutionVishal SinghNo ratings yet
- 18CS71-Artificial Intelligence Question BankDocument5 pages18CS71-Artificial Intelligence Question BankMANAS DUTTANo ratings yet
- 3-Problem, Production SystemDocument21 pages3-Problem, Production SystemEAGLE FFNo ratings yet
- Problem SolvingDocument10 pagesProblem SolvingAnup MaharjanNo ratings yet
- Artificial Intelligence (6CS6.2) Unit 1. A Introduction To Artificial IntelligenceDocument52 pagesArtificial Intelligence (6CS6.2) Unit 1. A Introduction To Artificial Intelligencevishakha_18No ratings yet
- IAT-I Question Paper With Solution of 18CS71 Artificial Intelligence and Machine Learning Oct-2022-Dr. Paras Nath SinghDocument7 pagesIAT-I Question Paper With Solution of 18CS71 Artificial Intelligence and Machine Learning Oct-2022-Dr. Paras Nath SinghBrundaja D NNo ratings yet
- Introduction To AI Lecture 3: Uninformed Search: Heshaam Faili Hfaili@ece - Ut.ac - Ir University of TehranDocument64 pagesIntroduction To AI Lecture 3: Uninformed Search: Heshaam Faili Hfaili@ece - Ut.ac - Ir University of Tehranlamba5No ratings yet
- Searching TechniquesDocument99 pagesSearching Techniquesjaspreetkaur20004No ratings yet
- UNIT - 2:problem Solving: State-Space Search and Control StrategiesDocument55 pagesUNIT - 2:problem Solving: State-Space Search and Control StrategiesRakeshNo ratings yet
- Chapter 3-Problem Solving by Searching Part 1Document80 pagesChapter 3-Problem Solving by Searching Part 1Dewanand GiriNo ratings yet
- Chapitre 2Document80 pagesChapitre 2Chaima BelhediNo ratings yet
- Chapter 3 Problem Solving AgentsDocument69 pagesChapter 3 Problem Solving Agentshamba AbebeNo ratings yet
- AI Module2Document7 pagesAI Module2tushar67No ratings yet
- Cryptanalysis Cryptarithmetic ProblemDocument43 pagesCryptanalysis Cryptarithmetic ProblemAbhinish Swaroop50% (2)
- AI L-02-Problem SolvingDocument20 pagesAI L-02-Problem Solvingsikandar070308No ratings yet
- Problems, Problem Spaces and SearchDocument31 pagesProblems, Problem Spaces and Searchvirgulatiit21a1068No ratings yet
- Chapter 2 Problem SolvingDocument190 pagesChapter 2 Problem SolvingMegha GuptaNo ratings yet
- AI 0ML Assignment-2Document7 pagesAI 0ML Assignment-2Dileep KnNo ratings yet
- Chapter 2 Problem SolvingDocument205 pagesChapter 2 Problem SolvingheadaidsNo ratings yet
- AI Problems & State Space: J. Felicia LilianDocument32 pagesAI Problems & State Space: J. Felicia LilianAbhinav PanchumarthiNo ratings yet
- Defining The Problem As A State Space SearchDocument9 pagesDefining The Problem As A State Space SearchashNo ratings yet
- Problems, Problem Spaces, and SearchDocument111 pagesProblems, Problem Spaces, and SearchdollsicecreamNo ratings yet
- Session 10 Uninfomed Search StrategiesDocument24 pagesSession 10 Uninfomed Search StrategiesMarkapuri Santhoash kumarNo ratings yet
- Water Jug Problem in Artificial IntelligenceDocument2 pagesWater Jug Problem in Artificial IntelligenceAvinash AllaNo ratings yet
- Experiment No - 02Document4 pagesExperiment No - 02ayesha sheikhNo ratings yet
- State Space Search and Heuristic Search TechniquesDocument16 pagesState Space Search and Heuristic Search Techniques28Akshay LokhandeNo ratings yet
- Ai Mod2Document33 pagesAi Mod2SapnaNo ratings yet
- Artificial IntelligenceDocument480 pagesArtificial Intelligencekaustavkakoty4No ratings yet
- Aids - Co1 - Session 3&4Document25 pagesAids - Co1 - Session 3&4sunny bandelaNo ratings yet
- Lecture 4Document17 pagesLecture 4SOUMYODEEP NAYAK 22BCE10547No ratings yet
- Artificial IntelligenceDocument143 pagesArtificial IntelligenceBhuvaneshAngelsAngelsNo ratings yet
- Lecture AI Problems SpaceDocument33 pagesLecture AI Problems Spaceadragon64No ratings yet
- Unit 2Document243 pagesUnit 2Gangadhar ReddyNo ratings yet
- Problem FormulationDocument11 pagesProblem FormulationAdri JovinNo ratings yet
- Monster Power - HTS3500 Manual PDFDocument42 pagesMonster Power - HTS3500 Manual PDFJose MondragonNo ratings yet
- 4936 Im Ap 02 10005Document7 pages4936 Im Ap 02 10005mauroalexandreandreNo ratings yet
- Solidworks 2017 Intermediate SkillsDocument40 pagesSolidworks 2017 Intermediate SkillsMajd HusseinNo ratings yet
- Advanced Linux: Exercises: 0 Download and Unpack The Exercise Files (Do That First Time Only)Document6 pagesAdvanced Linux: Exercises: 0 Download and Unpack The Exercise Files (Do That First Time Only)Niran SpiritNo ratings yet
- 380 KV Underground Transmission LineDocument15 pages380 KV Underground Transmission LineMohmmad NawabNo ratings yet
- Hibon VTBDocument8 pagesHibon VTBr rNo ratings yet
- STK415-100-E: 2-Channel Power Switching Audio Power IC, 60W+60WDocument12 pagesSTK415-100-E: 2-Channel Power Switching Audio Power IC, 60W+60WedisonpcNo ratings yet
- RTU QuestionnaireDocument7 pagesRTU Questionnaireimadz853No ratings yet
- Strategic Management Course Outline SUKCM 0220Document4 pagesStrategic Management Course Outline SUKCM 0220Niswarth TolaNo ratings yet
- Introduction of Insulation CoordinationDocument5 pagesIntroduction of Insulation CoordinationTaher El NoamanNo ratings yet
- FB Test CaseDocument8 pagesFB Test CaseLionKingNo ratings yet
- Artist 22 Pro User Manual (Spanish)Document12 pagesArtist 22 Pro User Manual (Spanish)Jaime RománNo ratings yet
- MJD122 889583Document8 pagesMJD122 889583Mahmoud Elpop ElsalhNo ratings yet
- Mobil DTE 700 Series: High-Performance Turbine Oil For Gas and Steam TurbinesDocument2 pagesMobil DTE 700 Series: High-Performance Turbine Oil For Gas and Steam TurbinesSimon CloveNo ratings yet
- OFERTA TEHNIC PROFIL PR 63 RAL 7016 GEAM 24 MMDocument1 pageOFERTA TEHNIC PROFIL PR 63 RAL 7016 GEAM 24 MMLucianNo ratings yet
- Guide To Syncsort PDFDocument41 pagesGuide To Syncsort PDFblueniluxNo ratings yet
- Assistant Drill Rig Operator Interview Questions and Answers GuideDocument13 pagesAssistant Drill Rig Operator Interview Questions and Answers GuideBassam HSENo ratings yet
- Textbook Programming Language Concepts Peter Sestoft Ebook All Chapter PDFDocument51 pagesTextbook Programming Language Concepts Peter Sestoft Ebook All Chapter PDFcandace.conklin507100% (7)
- XPO Q2 2021 TranscriptDocument16 pagesXPO Q2 2021 Transcriptshivshankar HondeNo ratings yet
- MCQ Artificial Intelligence Class 10 Computer VisionDocument41 pagesMCQ Artificial Intelligence Class 10 Computer VisionpratheeshNo ratings yet
- Flyers DesignDocument4 pagesFlyers DesignRamdas M NambisanNo ratings yet
- Fujifilm X100vi Digital Camera in Silver Camera ResearchDocument2 pagesFujifilm X100vi Digital Camera in Silver Camera Researchapi-728188368No ratings yet
- Conditional Exercise 3 - ENGLISH PAGE DAYANA SARAGUAYO 3Document1 pageConditional Exercise 3 - ENGLISH PAGE DAYANA SARAGUAYO 3Dayana SaraguayoNo ratings yet
- Inheritance Quiz (CS)Document23 pagesInheritance Quiz (CS)AylaNo ratings yet
- Theory On Wiring Large SystemsDocument17 pagesTheory On Wiring Large SystemsoespanaNo ratings yet
- Acer Aspire 3610 - Wistron Morar - Rev SBDocument40 pagesAcer Aspire 3610 - Wistron Morar - Rev SBPer JensenNo ratings yet
- Project Report For Granite Tiling Plant: Market Position:-Present Granite Tile Manufacturers in IndiaDocument6 pagesProject Report For Granite Tiling Plant: Market Position:-Present Granite Tile Manufacturers in Indiaram_babu_59No ratings yet