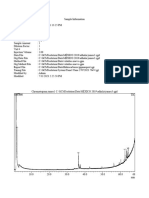
Download as pdf or txt
You might also like
- 1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyDocument50 pages1.1 Read The Data and Do Exploratory Data Analysis. Describe The Data BrieflyP Venkata Krishna Rao100% (19)
- National Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamDocument22 pagesNational Institute of Technology, Tiruchirappalli MBA Trimester Examination, Basic Data Analytic Marathon ExamArjun Jinumon PootharaNo ratings yet
- PCA Problem Statement With AnswerDocument22 pagesPCA Problem Statement With AnswerSBS MoviesNo ratings yet
- USL - 21070126112 - ColaboratoryDocument3 pagesUSL - 21070126112 - ColaboratoryVihan ChoradaNo ratings yet
- TP RegressionDocument1 pageTP RegressionMOHAMED EL BACHIR BERRIOUA100% (1)
- Import As Import As From Import As Import As Import AsDocument3 pagesImport As Import As From Import As Import As Import AsDeepesh YadavNo ratings yet
- Statistical Data Analysis - Ipynb - ColaboratoryDocument6 pagesStatistical Data Analysis - Ipynb - ColaboratoryVarad KulkarniNo ratings yet
- Using Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)Document29 pagesUsing Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)David EsparzaArellanoNo ratings yet
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Fmsa315 - s11 - A.ipynb - Fernández - ConstanzaDocument6 pagesFmsa315 - s11 - A.ipynb - Fernández - ConstanzaScribdTranslationsNo ratings yet
- Saadiq Khaliif DucaaleDocument3 pagesSaadiq Khaliif DucaalesaadiqdkhaliifNo ratings yet
- Granger Causality and VAR ModelsDocument1 pageGranger Causality and VAR ModelsManoj MNo ratings yet
- Linear RegressionDocument6 pagesLinear Regressionrxn114392No ratings yet
- Desarrollo Solemne 3 - ..Ipynb - ColaboratoryDocument4 pagesDesarrollo Solemne 3 - ..Ipynb - ColaboratoryCarola Araya100% (2)
- CG-MS Justicia SecundaDocument21 pagesCG-MS Justicia SecundaMiguel Rosas muozNo ratings yet
- Assignment 11Document7 pagesAssignment 11ankit mahto100% (1)
- Lecture7appendixa 12thsep2009Document31 pagesLecture7appendixa 12thsep2009Richa ShekharNo ratings yet
- Importing Necessary LibrariesDocument29 pagesImporting Necessary LibrariesMazhar MahadzirNo ratings yet
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Lab 4Document21 pagesLab 4glavchevanasikNo ratings yet
- Assigment 2 - Claudia Gilabert PrietoDocument7 pagesAssigment 2 - Claudia Gilabert Prietoclaudia gilabert prietoNo ratings yet
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- Linear Programming - Simplex Vs Interior-2-10Document9 pagesLinear Programming - Simplex Vs Interior-2-10Fan ClubNo ratings yet
- Python Course Cheat SheetDocument30 pagesPython Course Cheat SheetVinayNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Id Sepallengthcm Sepalwidthcm Petallengthcm Petalwidthcm Species 0 1 2 3 4Document4 pagesId Sepallengthcm Sepalwidthcm Petallengthcm Petalwidthcm Species 0 1 2 3 4Sebastian CallesNo ratings yet
- 20nov PDFDocument20 pages20nov PDFgianni moiNo ratings yet
- The Xtable Gallery: With Small Contributions From Others November 6, 2009Document19 pagesThe Xtable Gallery: With Small Contributions From Others November 6, 2009gpbaiNo ratings yet
- TrabajoDocument5 pagesTrabajoJAVIER OCHOANo ratings yet
- Assignment 1 - AnswerDocument13 pagesAssignment 1 - AnswerraniaNo ratings yet
- Ids Final SolDocument16 pagesIds Final SolHumayun RazaNo ratings yet
- Generating A Primes Using PartitionsDocument9 pagesGenerating A Primes Using PartitionskuayakuiNo ratings yet
- Rabino Lineth B Activity-8 ConsyslabDocument13 pagesRabino Lineth B Activity-8 ConsyslabLineth RabinoNo ratings yet
- Lab 3. Linear Regression 230223Document7 pagesLab 3. Linear Regression 230223ruso100% (1)
- Estadística Univariable - 20160210 - Jupyter NotebookDocument7 pagesEstadística Univariable - 20160210 - Jupyter NotebookTiffani Cano PatricioNo ratings yet
- Logistics RegressionDocument5 pagesLogistics RegressionNazakat ali100% (1)
- Assignment 1 Sol 2022Document4 pagesAssignment 1 Sol 2022Inès ChougraniNo ratings yet
- Modelo BMDocument5 pagesModelo BMRafael CombitaNo ratings yet
- EAD AssignmentDocument51 pagesEAD AssignmentSaumyaa YadavNo ratings yet
- Applied Numerical Methods Wmatlab For Engineers and Scientists 3rd Edition Chapra Solutions ManualDocument25 pagesApplied Numerical Methods Wmatlab For Engineers and Scientists 3rd Edition Chapra Solutions ManualJosephCraiggmax100% (56)
- Results 1Document4 pagesResults 1Đặng Thu TrúcNo ratings yet
- Tugas-Bank-Campaign (1) .Ipynb - ColaboratoryDocument29 pagesTugas-Bank-Campaign (1) .Ipynb - ColaboratoryAlexander TiopanNo ratings yet
- Ranch 2Document3 pagesRanch 2ELNo ratings yet
- Regressao Linear Simples - Ipynb - ColaboratoryDocument2 pagesRegressao Linear Simples - Ipynb - ColaboratoryGestão Financeira Fatec Bragança100% (1)
- Structure of The Report-S2Document15 pagesStructure of The Report-S2anitaNo ratings yet
- Ejemplo 2 Regresión Lineal Multiple DesarrolladoDocument14 pagesEjemplo 2 Regresión Lineal Multiple DesarrolladoLuis Enrique Tuñoque GutiérrezNo ratings yet
- Simple Linear RegressionDocument5 pagesSimple Linear Regression2023005No ratings yet
- GRCBDDocument7 pagesGRCBDkasuwedaNo ratings yet
- Ta Percobaan %konsentrasi Awal (G/L)Document13 pagesTa Percobaan %konsentrasi Awal (G/L)andriNo ratings yet
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- Statistics and Probality PerezDocument9 pagesStatistics and Probality PerezRizza Erika PillaNo ratings yet
- Setting The Data As Time-SeriesDocument3 pagesSetting The Data As Time-SeriesSNo ratings yet
- Measure of AssociationDocument5 pagesMeasure of AssociationAbha goyalNo ratings yet
- AlphaDecayPanelData LZJ 20210730Document3 pagesAlphaDecayPanelData LZJ 20210730Zuojie LiuNo ratings yet
- ML Project - Jupyter NotebookDocument5 pagesML Project - Jupyter NotebookJAISURYA S B.Sc.AIDANo ratings yet
- Exercise - For StatementDocument3 pagesExercise - For StatementAnis NadhirahNo ratings yet
- Probabilidad F Z CHI2Document7 pagesProbabilidad F Z CHI2robinsonjimena8No ratings yet
- DALab_Part-B_BCU&BUDocument12 pagesDALab_Part-B_BCU&BU8daudio02No ratings yet
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- SHS Stat Prob Q4 W2Document10 pagesSHS Stat Prob Q4 W2Jhie GacotNo ratings yet
- Introduction To Econometrics (3 Updated Edition, Global Edition)Document8 pagesIntroduction To Econometrics (3 Updated Edition, Global Edition)gfdsa123tryaggNo ratings yet
- Econometrics 2012 ExamDocument9 pagesEconometrics 2012 ExamLuca SomigliNo ratings yet
- Lec 06 Feature Selection and ExtractionDocument43 pagesLec 06 Feature Selection and ExtractionAugusto MongeNo ratings yet
- Activity 5Document28 pagesActivity 5Hermis Ramil TabhebzNo ratings yet
- Genevive Alcantara Martin (MABC 503) Worksheet #10 (Chi - Square Test of Independence)Document2 pagesGenevive Alcantara Martin (MABC 503) Worksheet #10 (Chi - Square Test of Independence)RheyJun Paguinto AnchetaNo ratings yet
- How To Control Confounders in StatisticDocument5 pagesHow To Control Confounders in StatisticFrancescoBarberoNo ratings yet
- Study Guide 01Document4 pagesStudy Guide 01ldlewisNo ratings yet
- QCC EwmaDocument50 pagesQCC EwmaAtoaBQNo ratings yet
- Assignment - Marks 60 (6X10 60) Statistics For Management Subject Code - MB0044Document12 pagesAssignment - Marks 60 (6X10 60) Statistics For Management Subject Code - MB0044Niyatitejas ParekhNo ratings yet
- Notes 2 - Scatterplots and CorrelationDocument6 pagesNotes 2 - Scatterplots and Correlationkjogu giyvgNo ratings yet
- Which Control Charts To Use WhereDocument115 pagesWhich Control Charts To Use Whereanbarasuar1964No ratings yet
- Sample Data Sets For Linear Regression1Document6 pagesSample Data Sets For Linear Regression1Thảo NguyễnNo ratings yet
- Central Limit TheoremDocument14 pagesCentral Limit TheoremRakesh Kumar ChaudharyNo ratings yet
- Review of Educational Research 1975 Gardner 43 57Document15 pagesReview of Educational Research 1975 Gardner 43 57Roy Umaña CarrilloNo ratings yet
- 2-11 ANOVA Analysis of VarianceDocument81 pages2-11 ANOVA Analysis of Varianceankit7588No ratings yet
- Jama Ioannidis 2018 VP 180015Document2 pagesJama Ioannidis 2018 VP 180015dbbircsNo ratings yet
- Local Media7248226037668021614Document4 pagesLocal Media7248226037668021614Ken Ken GorianoNo ratings yet
- Sampling ProcedureDocument15 pagesSampling Procedurevanne cando100% (1)
- Coefficient of Variation - Definition, Formula, Interpretation, Examples & FAQsDocument19 pagesCoefficient of Variation - Definition, Formula, Interpretation, Examples & FAQsteam TSOTARENo ratings yet
- Module 8 Computing The Point Estimate of A Population MeanDocument33 pagesModule 8 Computing The Point Estimate of A Population MeanJohn Lloyd LucabanNo ratings yet
- Rural Livelihood Diversification in Rice-Based Areas of BangladeshDocument29 pagesRural Livelihood Diversification in Rice-Based Areas of Bangladeshirri_social_sciences100% (1)
- 3.0 Numerical Descriptive MeasuresDocument115 pages3.0 Numerical Descriptive MeasuresTanish AgrawalNo ratings yet
- STAT3Document21 pagesSTAT3Gate Keeper of GrungeNo ratings yet
- Data Management With Voice OverDocument38 pagesData Management With Voice OverMarjorie NepomucenoNo ratings yet
- Multiple Linear RegressionDocument34 pagesMultiple Linear RegressionSrijanNo ratings yet
- Quarter 2: Practical Research 2Document40 pagesQuarter 2: Practical Research 2Marilou Iamztol RecamaraNo ratings yet
- Dukungan Anggota Keluarga Dan Activity of Daily Living (ADL) Pada Penderita Post Stroke Di Klinik Utama Graha Medika SalatigaDocument6 pagesDukungan Anggota Keluarga Dan Activity of Daily Living (ADL) Pada Penderita Post Stroke Di Klinik Utama Graha Medika SalatigaSindy ApriliaNo ratings yet
- Lesson 2: Finding The Mean and Variance of A Discrete Random VariableDocument9 pagesLesson 2: Finding The Mean and Variance of A Discrete Random VariableB - Clores, Mark RyanNo ratings yet