
Assignment 3 - Data Comms
Assignment 3 - Data Comms
You might also like
- Case Analysis 1 - EG398 - ECEP423Document2 pagesCase Analysis 1 - EG398 - ECEP423Eugene Embalzado Jr.100% (1)
- Individual Assignmnt IA5 v2 - Earned ValueDocument4 pagesIndividual Assignmnt IA5 v2 - Earned ValuerssarinNo ratings yet
- Innovation Taboo CardsDocument80 pagesInnovation Taboo CardsCarlos GuerreroNo ratings yet
- Unit VIIDocument8 pagesUnit VIIabdul jawadNo ratings yet
- Networking GroupDocument17 pagesNetworking GroupNimetullah HayNo ratings yet
- Acn Unit 5Document33 pagesAcn Unit 5Naidu ThamminainaNo ratings yet
- ISO/OSI Network ModelDocument19 pagesISO/OSI Network ModelRaazia MirNo ratings yet
- CN Unit 5Document20 pagesCN Unit 5chatkall46No ratings yet
- Unit 1-Intoduction To WWW & HTML FinalDocument67 pagesUnit 1-Intoduction To WWW & HTML Finalirfancrush96No ratings yet
- Network Support LayersDocument3 pagesNetwork Support LayersAbdelrhman AhmedNo ratings yet
- PDF DocumentDocument5 pagesPDF DocumentBritney PitttersonNo ratings yet
- Chapter 4.4 Application LayersDocument22 pagesChapter 4.4 Application Layersabebemako302No ratings yet
- NetworksDocument63 pagesNetworksilykillit325No ratings yet
- Chapter - 1 - Introduction To WWWDocument27 pagesChapter - 1 - Introduction To WWWsagarmethaNo ratings yet
- HTTP & TCP - IpDocument3 pagesHTTP & TCP - IpBitupan KalitaNo ratings yet
- Computer Networks:: OSI Reference ModelDocument11 pagesComputer Networks:: OSI Reference ModelMasterNo ratings yet
- The OSI Model: How Network Protocols WorkDocument5 pagesThe OSI Model: How Network Protocols WorkRafena MustaphaNo ratings yet
- D. The Tcp/Ip Reference Model: ProtocolDocument7 pagesD. The Tcp/Ip Reference Model: ProtocolEcho greenNo ratings yet
- Network LabDocument8 pagesNetwork LabTanusri GhoshNo ratings yet
- Website Design-2 Explain The Architecture of The Web Page ContentsDocument5 pagesWebsite Design-2 Explain The Architecture of The Web Page ContentsMilan AntonyNo ratings yet
- Lecture TwoDocument47 pagesLecture TwomikiNo ratings yet
- ProtocolsDocument24 pagesProtocolsToni-ann WillisNo ratings yet
- Lecture 2Document8 pagesLecture 2jasmhmyd205No ratings yet
- 1 CURS Application Layer Functionality and ProtocolsDocument16 pages1 CURS Application Layer Functionality and ProtocolsRazvan EulNo ratings yet
- Application LayerDocument15 pagesApplication LayerTamanna ShenoyNo ratings yet
- Networking Short NotesDocument7 pagesNetworking Short NotestonyNo ratings yet
- Technical Interview Questions and AnswerDocument9 pagesTechnical Interview Questions and AnswerBadrinath KadamNo ratings yet
- Assignment 1Document18 pagesAssignment 1Kushal BajracharyaNo ratings yet
- Network ProtocolsDocument13 pagesNetwork ProtocolspallaB ghoshNo ratings yet
- Application layer and protocolsDocument8 pagesApplication layer and protocolsharshvardhansutarNo ratings yet
- An Introduction To Web Hosting (ICT212)Document31 pagesAn Introduction To Web Hosting (ICT212)progiestudio100% (1)
- An Introduction To Internet ProgrammingpdfDocument27 pagesAn Introduction To Internet ProgrammingpdfMaxipincoNo ratings yet
- Class XII (As Per CBSE Board) : Computer ScienceDocument18 pagesClass XII (As Per CBSE Board) : Computer ScienceSuchit KumarNo ratings yet
- Client-Server Network: Local Area Networks (Lans) FTP DnsDocument8 pagesClient-Server Network: Local Area Networks (Lans) FTP DnsPopa AlinNo ratings yet
- An Introduction To Internet Programming PDFDocument27 pagesAn Introduction To Internet Programming PDFLaksana Dewa67% (3)
- FON Unit IV - IoTDocument29 pagesFON Unit IV - IoT21d41a0513No ratings yet
- Quizlet QuestionsDocument21 pagesQuizlet QuestionsMuhammed YasserNo ratings yet
- Unit 1 & 2 Web Design - MGTDocument274 pagesUnit 1 & 2 Web Design - MGTuxhihaitaxhi6No ratings yet
- Computer NetworkingDocument7 pagesComputer NetworkingOcampo Amy100% (1)
- Cisco Is Easy PDFDocument150 pagesCisco Is Easy PDFdrucker_smithNo ratings yet
- Network ProgrammingDocument23 pagesNetwork ProgrammingDesi babaNo ratings yet
- InternetDocument5 pagesInternethueychopper.briosoNo ratings yet
- Web Applications and The Internet: A Closer Look at The World Wide WebDocument20 pagesWeb Applications and The Internet: A Closer Look at The World Wide Webghar_dashNo ratings yet
- How OSI 7 Layer Model WorksDocument9 pagesHow OSI 7 Layer Model WorksRanjit SinghNo ratings yet
- Osi ModelDocument11 pagesOsi ModelMu Asif KhNo ratings yet
- The OSI Network Model StandardDocument10 pagesThe OSI Network Model Standardcheal_che2No ratings yet
- Computer Networks TCP IpDocument15 pagesComputer Networks TCP IpSudarshan KrishnaNo ratings yet
- ECE541 Data Networks 1: Application Layer Functionality and ProtocolsDocument27 pagesECE541 Data Networks 1: Application Layer Functionality and ProtocolsUnicorn54No ratings yet
- Assignment 1: Name: Satyarthsinh Gohil Regno: 16BCE1125 Course: Internet and Web Programming Faculty: Sandhya.P Slot: E2Document13 pagesAssignment 1: Name: Satyarthsinh Gohil Regno: 16BCE1125 Course: Internet and Web Programming Faculty: Sandhya.P Slot: E2ABHISHEK MISHRANo ratings yet
- Network ProtocolsDocument12 pagesNetwork ProtocolsELIANA NASHANo ratings yet
- Abstract On Socket ProgrammingDocument33 pagesAbstract On Socket Programmingyogesh_yadav2012100% (2)
- Interfaces: Medium Access ControlDocument6 pagesInterfaces: Medium Access ControlnaziaNo ratings yet
- Assignment-Cn: Syeda Pakiza ImranDocument5 pagesAssignment-Cn: Syeda Pakiza Imrannauman tariqNo ratings yet
- BSNLDocument14 pagesBSNLRavi SinghNo ratings yet
- Network Layers: The OSI Network Model StandardDocument4 pagesNetwork Layers: The OSI Network Model StandardPrasanna Venkatesan100% (1)
- 1.1. Background: Datagram CommunicationDocument8 pages1.1. Background: Datagram CommunicationPrithwish GhoshNo ratings yet
- Computer Network: IBPS SO (IT) Exam 2017Document19 pagesComputer Network: IBPS SO (IT) Exam 2017Narsimha Charya ManthangodeNo ratings yet
- Bryan Ye, Year 9 IPT, MR Simmonds, 2011 Communications Assessment TaskDocument28 pagesBryan Ye, Year 9 IPT, MR Simmonds, 2011 Communications Assessment TaskKevin ShenNo ratings yet
- Lecture 3Document15 pagesLecture 3Muhammad Tahir MehmoodNo ratings yet
- Network Layer Architecture and Types of ProtocolDocument3 pagesNetwork Layer Architecture and Types of ProtocolSuryanshNo ratings yet
- NC Mod 4Document40 pagesNC Mod 4Haritha BalakrishnanNo ratings yet
- Hacking Network Protocols: Unlocking the Secrets of Network Protocol AnalysisFrom EverandHacking Network Protocols: Unlocking the Secrets of Network Protocol AnalysisNo ratings yet
- Introduction to Internet & Web Technology: Internet & Web TechnologyFrom EverandIntroduction to Internet & Web Technology: Internet & Web TechnologyNo ratings yet
- Section 2.3 Venn Diagrams and Set OperationsDocument15 pagesSection 2.3 Venn Diagrams and Set OperationsEugene Embalzado Jr.No ratings yet
- Assignment 1 - EG398 - ECEP423Document5 pagesAssignment 1 - EG398 - ECEP423Eugene Embalzado Jr.No ratings yet
- Marikina Polytechnic College Graduate School Accomplishment Report Student's Tasks/Outputs (Include Pictures/screenshots of Submitted Work)Document2 pagesMarikina Polytechnic College Graduate School Accomplishment Report Student's Tasks/Outputs (Include Pictures/screenshots of Submitted Work)Eugene Embalzado Jr.No ratings yet
- PhET - Energy Forms & Changes Virtual LabDocument4 pagesPhET - Energy Forms & Changes Virtual LabEugene Embalzado Jr.No ratings yet
- Chapter 18: Electrical Properties: Issues To Address..Document27 pagesChapter 18: Electrical Properties: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Issues To Address... : Chapter 15 - 1Document27 pagesIssues To Address... : Chapter 15 - 1Eugene Embalzado Jr.No ratings yet
- P1 Assignment - EG389BAC EEDF323 - 321LDocument11 pagesP1 Assignment - EG389BAC EEDF323 - 321LEugene Embalzado Jr.No ratings yet
- Chapter 21: Optical Properties: Issues To Address..Document31 pagesChapter 21: Optical Properties: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Issues To Address..Document12 pagesIssues To Address..Eugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 9 - Ethernet AnswersDocument1 pageNetwork Fundamentals Chapter 9 - Ethernet AnswersEugene Embalzado Jr.No ratings yet
- Chapter 16: Composites: Issues To Address..Document23 pagesChapter 16: Composites: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 7 - Data Link LayerDocument4 pagesNetwork Fundamentals Chapter 7 - Data Link LayerEugene Embalzado Jr.No ratings yet
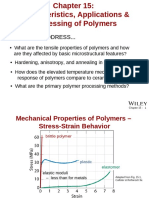
- Polymer Structures: Issues To Address..Document34 pagesPolymer Structures: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Issues To Address... : - How Do Materials Respond To The Application of Heat - How Do We Define and Measure..Document17 pagesIssues To Address... : - How Do Materials Respond To The Application of Heat - How Do We Define and Measure..Eugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 9 - EthernetDocument4 pagesNetwork Fundamentals Chapter 9 - EthernetEugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 10 - Planning and Cabling NetworksDocument6 pagesNetwork Fundamentals Chapter 10 - Planning and Cabling NetworksEugene Embalzado Jr.No ratings yet
- Problem Set in AC and DCDocument3 pagesProblem Set in AC and DCEugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 8 - OSI Physical LayerDocument5 pagesNetwork Fundamentals Chapter 8 - OSI Physical LayerEugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 10 - Planning and Cabling Networks AnswersDocument3 pagesNetwork Fundamentals Chapter 10 - Planning and Cabling Networks AnswersEugene Embalzado Jr.No ratings yet
- Pre Test in Acoustics Broadcasting and Wireless TechnologiesDocument7 pagesPre Test in Acoustics Broadcasting and Wireless TechnologiesEugene Embalzado Jr.No ratings yet
- DIFEQUA Lesson 1.2Document13 pagesDIFEQUA Lesson 1.2Eugene Embalzado Jr.No ratings yet
- Radio Communications Systems II - Session 2 - AdU - Post Test 2Document3 pagesRadio Communications Systems II - Session 2 - AdU - Post Test 2Eugene Embalzado Jr.No ratings yet
- Covalent Review and Training Center Electronics RM 203 929 Consuelo Bldg. N. Reyes St. Sampaloc Manila. (Near FEU) Contact # 09477357168 AC CircuitsDocument2 pagesCovalent Review and Training Center Electronics RM 203 929 Consuelo Bldg. N. Reyes St. Sampaloc Manila. (Near FEU) Contact # 09477357168 AC CircuitsEugene Embalzado Jr.No ratings yet
- CyberArk End of Life PolicyDocument5 pagesCyberArk End of Life PolicyAndrei SmnNo ratings yet
- Authentication SecurityDocument10 pagesAuthentication SecurityGanesh93% (14)
- Perception 1.18 Desktop PDFDocument161 pagesPerception 1.18 Desktop PDFAhmedRaafatNo ratings yet
- Iflash 1800 Partie 2Document45 pagesIflash 1800 Partie 2Fateh Azwi50% (2)
- Qdoc - Tips - Nokia Megaplexer Product DescriptionDocument16 pagesQdoc - Tips - Nokia Megaplexer Product DescriptionDesi AbroadNo ratings yet
- Rani Hod Forensic Challenge 2010 - Challenge-2 - SubmissionDocument18 pagesRani Hod Forensic Challenge 2010 - Challenge-2 - SubmissionPhan TrungNo ratings yet
- JNCIA NotesDocument28 pagesJNCIA NotesneoaltNo ratings yet
- Astra G Manual SrpskiDocument706 pagesAstra G Manual Srpskimetar123No ratings yet
- Experiment 1 - Introduction To Network DevicesDocument2 pagesExperiment 1 - Introduction To Network DevicesM ZahidNo ratings yet
- CO Transactions TestDocument5 pagesCO Transactions Testmarishca_c7949No ratings yet
- Unit - Ii IrsDocument10 pagesUnit - Ii IrsPERUMALLA SRAVANINo ratings yet
- Starting A VPS CompanyDocument22 pagesStarting A VPS CompanyM Imran AleeNo ratings yet
- Interrupts: ObjectivesDocument2 pagesInterrupts: ObjectivesxfytuczvwmjefjiagcNo ratings yet
- Company Organization ChartDocument4 pagesCompany Organization ChartDheyatNo ratings yet
- Unit9 PDEsDocument34 pagesUnit9 PDEssmileNo ratings yet
- Brochure Testo 340Document8 pagesBrochure Testo 340Borivoj StepanovNo ratings yet
- Wlan Soc Für Das Internet of Things Pi and More 7 Nico MaasDocument30 pagesWlan Soc Für Das Internet of Things Pi and More 7 Nico MaasdanielNo ratings yet
- DJI FlightHub 2 User Guide v2.0Document41 pagesDJI FlightHub 2 User Guide v2.0savaba8669No ratings yet
- User Manual HD5-20K LCDDocument36 pagesUser Manual HD5-20K LCDKhách Sạn Hoàng PhốNo ratings yet
- Efi Fiery Wof Prep Files FQ en UsDocument5 pagesEfi Fiery Wof Prep Files FQ en UsJufer88lemNo ratings yet
- 835 Mass Media Studies Ms t2Document3 pages835 Mass Media Studies Ms t2Vibhav Mehta100% (1)
- Structural Design Institute: The Knowledge Base in Structural EngineeringDocument25 pagesStructural Design Institute: The Knowledge Base in Structural EngineeringAnonymous DlVrxSbVk9100% (1)
- Adobe Lightroom 3 ReadMeDocument1 pageAdobe Lightroom 3 ReadMeMuhammad Shoaib SyedNo ratings yet
- Product Analysis and Customer Support: T24.Payments - InfoDocument7 pagesProduct Analysis and Customer Support: T24.Payments - Infosarmad raeesNo ratings yet
- DBS11426-10 User ManualDocument29 pagesDBS11426-10 User ManualtariktunadNo ratings yet
- VBMB - 002-1Document56 pagesVBMB - 002-1Seethalakshmi VNo ratings yet
- Gozambiajobs Yalelo Lusaka Full Time Ict SpecialistDocument4 pagesGozambiajobs Yalelo Lusaka Full Time Ict SpecialistjoanmubzNo ratings yet
- 207 Jva ProgramsDocument116 pages207 Jva ProgramsUtpal Kumar0% (1)
















































































































Download as docx, pdf, or txt
You might also like
- Case Analysis 1 - EG398 - ECEP423Document2 pagesCase Analysis 1 - EG398 - ECEP423Eugene Embalzado Jr.100% (1)
- Individual Assignmnt IA5 v2 - Earned ValueDocument4 pagesIndividual Assignmnt IA5 v2 - Earned ValuerssarinNo ratings yet
- Innovation Taboo CardsDocument80 pagesInnovation Taboo CardsCarlos GuerreroNo ratings yet
- Unit VIIDocument8 pagesUnit VIIabdul jawadNo ratings yet
- Networking GroupDocument17 pagesNetworking GroupNimetullah HayNo ratings yet
- Acn Unit 5Document33 pagesAcn Unit 5Naidu ThamminainaNo ratings yet
- ISO/OSI Network ModelDocument19 pagesISO/OSI Network ModelRaazia MirNo ratings yet
- CN Unit 5Document20 pagesCN Unit 5chatkall46No ratings yet
- Unit 1-Intoduction To WWW & HTML FinalDocument67 pagesUnit 1-Intoduction To WWW & HTML Finalirfancrush96No ratings yet
- Network Support LayersDocument3 pagesNetwork Support LayersAbdelrhman AhmedNo ratings yet
- PDF DocumentDocument5 pagesPDF DocumentBritney PitttersonNo ratings yet
- Chapter 4.4 Application LayersDocument22 pagesChapter 4.4 Application Layersabebemako302No ratings yet
- NetworksDocument63 pagesNetworksilykillit325No ratings yet
- Chapter - 1 - Introduction To WWWDocument27 pagesChapter - 1 - Introduction To WWWsagarmethaNo ratings yet
- HTTP & TCP - IpDocument3 pagesHTTP & TCP - IpBitupan KalitaNo ratings yet
- Computer Networks:: OSI Reference ModelDocument11 pagesComputer Networks:: OSI Reference ModelMasterNo ratings yet
- The OSI Model: How Network Protocols WorkDocument5 pagesThe OSI Model: How Network Protocols WorkRafena MustaphaNo ratings yet
- D. The Tcp/Ip Reference Model: ProtocolDocument7 pagesD. The Tcp/Ip Reference Model: ProtocolEcho greenNo ratings yet
- Network LabDocument8 pagesNetwork LabTanusri GhoshNo ratings yet
- Website Design-2 Explain The Architecture of The Web Page ContentsDocument5 pagesWebsite Design-2 Explain The Architecture of The Web Page ContentsMilan AntonyNo ratings yet
- Lecture TwoDocument47 pagesLecture TwomikiNo ratings yet
- ProtocolsDocument24 pagesProtocolsToni-ann WillisNo ratings yet
- Lecture 2Document8 pagesLecture 2jasmhmyd205No ratings yet
- 1 CURS Application Layer Functionality and ProtocolsDocument16 pages1 CURS Application Layer Functionality and ProtocolsRazvan EulNo ratings yet
- Application LayerDocument15 pagesApplication LayerTamanna ShenoyNo ratings yet
- Networking Short NotesDocument7 pagesNetworking Short NotestonyNo ratings yet
- Technical Interview Questions and AnswerDocument9 pagesTechnical Interview Questions and AnswerBadrinath KadamNo ratings yet
- Assignment 1Document18 pagesAssignment 1Kushal BajracharyaNo ratings yet
- Network ProtocolsDocument13 pagesNetwork ProtocolspallaB ghoshNo ratings yet
- Application layer and protocolsDocument8 pagesApplication layer and protocolsharshvardhansutarNo ratings yet
- An Introduction To Web Hosting (ICT212)Document31 pagesAn Introduction To Web Hosting (ICT212)progiestudio100% (1)
- An Introduction To Internet ProgrammingpdfDocument27 pagesAn Introduction To Internet ProgrammingpdfMaxipincoNo ratings yet
- Class XII (As Per CBSE Board) : Computer ScienceDocument18 pagesClass XII (As Per CBSE Board) : Computer ScienceSuchit KumarNo ratings yet
- Client-Server Network: Local Area Networks (Lans) FTP DnsDocument8 pagesClient-Server Network: Local Area Networks (Lans) FTP DnsPopa AlinNo ratings yet
- An Introduction To Internet Programming PDFDocument27 pagesAn Introduction To Internet Programming PDFLaksana Dewa67% (3)
- FON Unit IV - IoTDocument29 pagesFON Unit IV - IoT21d41a0513No ratings yet
- Quizlet QuestionsDocument21 pagesQuizlet QuestionsMuhammed YasserNo ratings yet
- Unit 1 & 2 Web Design - MGTDocument274 pagesUnit 1 & 2 Web Design - MGTuxhihaitaxhi6No ratings yet
- Computer NetworkingDocument7 pagesComputer NetworkingOcampo Amy100% (1)
- Cisco Is Easy PDFDocument150 pagesCisco Is Easy PDFdrucker_smithNo ratings yet
- Network ProgrammingDocument23 pagesNetwork ProgrammingDesi babaNo ratings yet
- InternetDocument5 pagesInternethueychopper.briosoNo ratings yet
- Web Applications and The Internet: A Closer Look at The World Wide WebDocument20 pagesWeb Applications and The Internet: A Closer Look at The World Wide Webghar_dashNo ratings yet
- How OSI 7 Layer Model WorksDocument9 pagesHow OSI 7 Layer Model WorksRanjit SinghNo ratings yet
- Osi ModelDocument11 pagesOsi ModelMu Asif KhNo ratings yet
- The OSI Network Model StandardDocument10 pagesThe OSI Network Model Standardcheal_che2No ratings yet
- Computer Networks TCP IpDocument15 pagesComputer Networks TCP IpSudarshan KrishnaNo ratings yet
- ECE541 Data Networks 1: Application Layer Functionality and ProtocolsDocument27 pagesECE541 Data Networks 1: Application Layer Functionality and ProtocolsUnicorn54No ratings yet
- Assignment 1: Name: Satyarthsinh Gohil Regno: 16BCE1125 Course: Internet and Web Programming Faculty: Sandhya.P Slot: E2Document13 pagesAssignment 1: Name: Satyarthsinh Gohil Regno: 16BCE1125 Course: Internet and Web Programming Faculty: Sandhya.P Slot: E2ABHISHEK MISHRANo ratings yet
- Network ProtocolsDocument12 pagesNetwork ProtocolsELIANA NASHANo ratings yet
- Abstract On Socket ProgrammingDocument33 pagesAbstract On Socket Programmingyogesh_yadav2012100% (2)
- Interfaces: Medium Access ControlDocument6 pagesInterfaces: Medium Access ControlnaziaNo ratings yet
- Assignment-Cn: Syeda Pakiza ImranDocument5 pagesAssignment-Cn: Syeda Pakiza Imrannauman tariqNo ratings yet
- BSNLDocument14 pagesBSNLRavi SinghNo ratings yet
- Network Layers: The OSI Network Model StandardDocument4 pagesNetwork Layers: The OSI Network Model StandardPrasanna Venkatesan100% (1)
- 1.1. Background: Datagram CommunicationDocument8 pages1.1. Background: Datagram CommunicationPrithwish GhoshNo ratings yet
- Computer Network: IBPS SO (IT) Exam 2017Document19 pagesComputer Network: IBPS SO (IT) Exam 2017Narsimha Charya ManthangodeNo ratings yet
- Bryan Ye, Year 9 IPT, MR Simmonds, 2011 Communications Assessment TaskDocument28 pagesBryan Ye, Year 9 IPT, MR Simmonds, 2011 Communications Assessment TaskKevin ShenNo ratings yet
- Lecture 3Document15 pagesLecture 3Muhammad Tahir MehmoodNo ratings yet
- Network Layer Architecture and Types of ProtocolDocument3 pagesNetwork Layer Architecture and Types of ProtocolSuryanshNo ratings yet
- NC Mod 4Document40 pagesNC Mod 4Haritha BalakrishnanNo ratings yet
- Hacking Network Protocols: Unlocking the Secrets of Network Protocol AnalysisFrom EverandHacking Network Protocols: Unlocking the Secrets of Network Protocol AnalysisNo ratings yet
- Introduction to Internet & Web Technology: Internet & Web TechnologyFrom EverandIntroduction to Internet & Web Technology: Internet & Web TechnologyNo ratings yet
- Section 2.3 Venn Diagrams and Set OperationsDocument15 pagesSection 2.3 Venn Diagrams and Set OperationsEugene Embalzado Jr.No ratings yet
- Assignment 1 - EG398 - ECEP423Document5 pagesAssignment 1 - EG398 - ECEP423Eugene Embalzado Jr.No ratings yet
- Marikina Polytechnic College Graduate School Accomplishment Report Student's Tasks/Outputs (Include Pictures/screenshots of Submitted Work)Document2 pagesMarikina Polytechnic College Graduate School Accomplishment Report Student's Tasks/Outputs (Include Pictures/screenshots of Submitted Work)Eugene Embalzado Jr.No ratings yet
- PhET - Energy Forms & Changes Virtual LabDocument4 pagesPhET - Energy Forms & Changes Virtual LabEugene Embalzado Jr.No ratings yet
- Chapter 18: Electrical Properties: Issues To Address..Document27 pagesChapter 18: Electrical Properties: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Issues To Address... : Chapter 15 - 1Document27 pagesIssues To Address... : Chapter 15 - 1Eugene Embalzado Jr.No ratings yet
- P1 Assignment - EG389BAC EEDF323 - 321LDocument11 pagesP1 Assignment - EG389BAC EEDF323 - 321LEugene Embalzado Jr.No ratings yet
- Chapter 21: Optical Properties: Issues To Address..Document31 pagesChapter 21: Optical Properties: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Issues To Address..Document12 pagesIssues To Address..Eugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 9 - Ethernet AnswersDocument1 pageNetwork Fundamentals Chapter 9 - Ethernet AnswersEugene Embalzado Jr.No ratings yet
- Chapter 16: Composites: Issues To Address..Document23 pagesChapter 16: Composites: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 7 - Data Link LayerDocument4 pagesNetwork Fundamentals Chapter 7 - Data Link LayerEugene Embalzado Jr.No ratings yet
- Polymer Structures: Issues To Address..Document34 pagesPolymer Structures: Issues To Address..Eugene Embalzado Jr.No ratings yet
- Issues To Address... : - How Do Materials Respond To The Application of Heat - How Do We Define and Measure..Document17 pagesIssues To Address... : - How Do Materials Respond To The Application of Heat - How Do We Define and Measure..Eugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 9 - EthernetDocument4 pagesNetwork Fundamentals Chapter 9 - EthernetEugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 10 - Planning and Cabling NetworksDocument6 pagesNetwork Fundamentals Chapter 10 - Planning and Cabling NetworksEugene Embalzado Jr.No ratings yet
- Problem Set in AC and DCDocument3 pagesProblem Set in AC and DCEugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 8 - OSI Physical LayerDocument5 pagesNetwork Fundamentals Chapter 8 - OSI Physical LayerEugene Embalzado Jr.No ratings yet
- Network Fundamentals Chapter 10 - Planning and Cabling Networks AnswersDocument3 pagesNetwork Fundamentals Chapter 10 - Planning and Cabling Networks AnswersEugene Embalzado Jr.No ratings yet
- Pre Test in Acoustics Broadcasting and Wireless TechnologiesDocument7 pagesPre Test in Acoustics Broadcasting and Wireless TechnologiesEugene Embalzado Jr.No ratings yet
- DIFEQUA Lesson 1.2Document13 pagesDIFEQUA Lesson 1.2Eugene Embalzado Jr.No ratings yet
- Radio Communications Systems II - Session 2 - AdU - Post Test 2Document3 pagesRadio Communications Systems II - Session 2 - AdU - Post Test 2Eugene Embalzado Jr.No ratings yet
- Covalent Review and Training Center Electronics RM 203 929 Consuelo Bldg. N. Reyes St. Sampaloc Manila. (Near FEU) Contact # 09477357168 AC CircuitsDocument2 pagesCovalent Review and Training Center Electronics RM 203 929 Consuelo Bldg. N. Reyes St. Sampaloc Manila. (Near FEU) Contact # 09477357168 AC CircuitsEugene Embalzado Jr.No ratings yet
- CyberArk End of Life PolicyDocument5 pagesCyberArk End of Life PolicyAndrei SmnNo ratings yet
- Authentication SecurityDocument10 pagesAuthentication SecurityGanesh93% (14)
- Perception 1.18 Desktop PDFDocument161 pagesPerception 1.18 Desktop PDFAhmedRaafatNo ratings yet
- Iflash 1800 Partie 2Document45 pagesIflash 1800 Partie 2Fateh Azwi50% (2)
- Qdoc - Tips - Nokia Megaplexer Product DescriptionDocument16 pagesQdoc - Tips - Nokia Megaplexer Product DescriptionDesi AbroadNo ratings yet
- Rani Hod Forensic Challenge 2010 - Challenge-2 - SubmissionDocument18 pagesRani Hod Forensic Challenge 2010 - Challenge-2 - SubmissionPhan TrungNo ratings yet
- JNCIA NotesDocument28 pagesJNCIA NotesneoaltNo ratings yet
- Astra G Manual SrpskiDocument706 pagesAstra G Manual Srpskimetar123No ratings yet
- Experiment 1 - Introduction To Network DevicesDocument2 pagesExperiment 1 - Introduction To Network DevicesM ZahidNo ratings yet
- CO Transactions TestDocument5 pagesCO Transactions Testmarishca_c7949No ratings yet
- Unit - Ii IrsDocument10 pagesUnit - Ii IrsPERUMALLA SRAVANINo ratings yet
- Starting A VPS CompanyDocument22 pagesStarting A VPS CompanyM Imran AleeNo ratings yet
- Interrupts: ObjectivesDocument2 pagesInterrupts: ObjectivesxfytuczvwmjefjiagcNo ratings yet
- Company Organization ChartDocument4 pagesCompany Organization ChartDheyatNo ratings yet
- Unit9 PDEsDocument34 pagesUnit9 PDEssmileNo ratings yet
- Brochure Testo 340Document8 pagesBrochure Testo 340Borivoj StepanovNo ratings yet
- Wlan Soc Für Das Internet of Things Pi and More 7 Nico MaasDocument30 pagesWlan Soc Für Das Internet of Things Pi and More 7 Nico MaasdanielNo ratings yet
- DJI FlightHub 2 User Guide v2.0Document41 pagesDJI FlightHub 2 User Guide v2.0savaba8669No ratings yet
- User Manual HD5-20K LCDDocument36 pagesUser Manual HD5-20K LCDKhách Sạn Hoàng PhốNo ratings yet
- Efi Fiery Wof Prep Files FQ en UsDocument5 pagesEfi Fiery Wof Prep Files FQ en UsJufer88lemNo ratings yet
- 835 Mass Media Studies Ms t2Document3 pages835 Mass Media Studies Ms t2Vibhav Mehta100% (1)
- Structural Design Institute: The Knowledge Base in Structural EngineeringDocument25 pagesStructural Design Institute: The Knowledge Base in Structural EngineeringAnonymous DlVrxSbVk9100% (1)
- Adobe Lightroom 3 ReadMeDocument1 pageAdobe Lightroom 3 ReadMeMuhammad Shoaib SyedNo ratings yet
- Product Analysis and Customer Support: T24.Payments - InfoDocument7 pagesProduct Analysis and Customer Support: T24.Payments - Infosarmad raeesNo ratings yet
- DBS11426-10 User ManualDocument29 pagesDBS11426-10 User ManualtariktunadNo ratings yet
- VBMB - 002-1Document56 pagesVBMB - 002-1Seethalakshmi VNo ratings yet
- Gozambiajobs Yalelo Lusaka Full Time Ict SpecialistDocument4 pagesGozambiajobs Yalelo Lusaka Full Time Ict SpecialistjoanmubzNo ratings yet
- 207 Jva ProgramsDocument116 pages207 Jva ProgramsUtpal Kumar0% (1)