Download as pdf or txt
You might also like
- 2014 WMI Kindergarten Questions Part 1Document5 pages2014 WMI Kindergarten Questions Part 1dwi ayu83% (6)
- WQD7006 Exam Part2Document3 pagesWQD7006 Exam Part2AdamZain788100% (1)
- ID3 Algorithm For Decision TreesDocument16 pagesID3 Algorithm For Decision TreesYiping HuangNo ratings yet
- Classification and Regression Trees (CART)Document6 pagesClassification and Regression Trees (CART)Pravin PanduNo ratings yet
- Decision Tree - IIDocument30 pagesDecision Tree - IIMaha LakshmiNo ratings yet
- 4.decision TreeDocument68 pages4.decision TreesharadNo ratings yet
- EXP-3-To Implement CART Decision Tree Algorithm.docxDocument14 pagesEXP-3-To Implement CART Decision Tree Algorithm.docxbadgujarvarad800No ratings yet
- Decision TreeDocument5 pagesDecision TreePriyanka pawarNo ratings yet
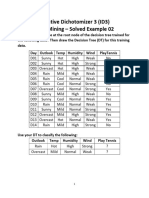
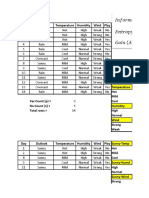
- DM DT Solved Example 02 - UnlockedDocument3 pagesDM DT Solved Example 02 - UnlockedJawaher AlbaddawiNo ratings yet
- (Lec 6) Decision Tree MLDocument26 pages(Lec 6) Decision Tree MLMuhtasim Jawad NafiNo ratings yet
- R. Vishnu PriyaDocument16 pagesR. Vishnu PriyaAlok KumarNo ratings yet
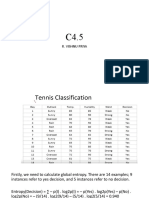
- 3.1 C 4.5 Algorithm-19Document10 pages3.1 C 4.5 Algorithm-19nayan jainNo ratings yet
- AT3 - Decision Tree ExampleDocument17 pagesAT3 - Decision Tree ExampleramadeviNo ratings yet
- Machine LearningDocument52 pagesMachine LearningaimahsiddNo ratings yet
- Seminar 3Document43 pagesSeminar 3manojmani380No ratings yet
- Decision Tree (Class 37-38) 169692509554958626652505a71d481Document45 pagesDecision Tree (Class 37-38) 169692509554958626652505a71d48123mb0072No ratings yet
- Decision TreeDocument6 pagesDecision TreeshubhNo ratings yet
- Classification: Decision TreesDocument30 pagesClassification: Decision TreesAshish TiwariNo ratings yet
- Data Minig Haris Arshad BSSEDocument9 pagesData Minig Haris Arshad BSSEArsh SyedNo ratings yet
- Sunny HOT High Sunny HOT High HOT High HighDocument3 pagesSunny HOT High Sunny HOT High HOT High HighSamuel TobinkNo ratings yet
- Machine LearningDocument27 pagesMachine Learningsahibpctebca21aNo ratings yet
- Decision Tree - JKDocument17 pagesDecision Tree - JKPranav KasliwalNo ratings yet
- Decision Tree: - Construct A Decision Tree To Classify "Golf PlayDocument17 pagesDecision Tree: - Construct A Decision Tree To Classify "Golf PlayAyaz HussainNo ratings yet
- Module 3-Decision Tree LearningDocument33 pagesModule 3-Decision Tree Learningramya100% (1)
- 7-Decision Trees LearningDocument51 pages7-Decision Trees Learningyshu1No ratings yet
- Part Five - Extra PDFDocument27 pagesPart Five - Extra PDFNashowan100% (1)
- Decision TreeDocument19 pagesDecision TreeIwan YuniantoNo ratings yet
- Bayes Algorithm: Ex1Document8 pagesBayes Algorithm: Ex1Thao PhamNo ratings yet
- 15-381 Spring 2007 Assignment 6: LearningDocument14 pages15-381 Spring 2007 Assignment 6: LearningsandeepanNo ratings yet
- Decision Tree TutorialDocument9 pagesDecision Tree TutorialMuhammad UsmanNo ratings yet
- Ngày: outlook = sunny, temperature = cool, humidity = high, wind = strong => chơi tennis không 1. Xét trên toàn tập dữ liệu H (S) = * Nếu chọn outlook: Outlook: sunnyDocument4 pagesNgày: outlook = sunny, temperature = cool, humidity = high, wind = strong => chơi tennis không 1. Xét trên toàn tập dữ liệu H (S) = * Nếu chọn outlook: Outlook: sunnyMinh Trí0% (1)
- Government Engineering College, Modasa: B.E. - Computer Engineering (Semester - VII) 3170724 - Machine LearningDocument3 pagesGovernment Engineering College, Modasa: B.E. - Computer Engineering (Semester - VII) 3170724 - Machine LearningronakNo ratings yet
- Ics320part3 DecisionTreeLearningDocument29 pagesIcs320part3 DecisionTreeLearningPrateek BaldwaNo ratings yet
- ML Unit-2 Material WORDDocument25 pagesML Unit-2 Material WORDafreed khanNo ratings yet
- Decision Trees CLSDocument43 pagesDecision Trees CLSAshish TiwariNo ratings yet
- Contoh Perhitungan Decision TreeDocument2 pagesContoh Perhitungan Decision TreeIwan YuniantoNo ratings yet
- DT 03 Algorithm Behind Decion TreeDocument51 pagesDT 03 Algorithm Behind Decion TreeVijay ManiNo ratings yet
- AiML 4 3Document59 pagesAiML 4 3Nox MidNo ratings yet
- Ejercicio 44 de La Guía de EstudioDocument1 pageEjercicio 44 de La Guía de EstudioJavier MogrovejoNo ratings yet
- Experimental Report 3Document5 pagesExperimental Report 312TIn MInh Đức-No ratings yet
- Assignment 2 Updated AIMLDocument2 pagesAssignment 2 Updated AIMLVismitha GowdaNo ratings yet
- Decision - TreeDocument75 pagesDecision - Tree727721eucs170No ratings yet
- Data Mining All SlidesDocument206 pagesData Mining All SlidesAmanat ConstructionNo ratings yet
- Report-3 (8Document5 pagesReport-3 (812TIn MInh Đức-No ratings yet
- Selesaikan Dengan Logika ID3, Dari Sample Data Kriteriacuaca Untuk Permainan Bola BerikutDocument13 pagesSelesaikan Dengan Logika ID3, Dari Sample Data Kriteriacuaca Untuk Permainan Bola BerikutSasya NadiraNo ratings yet
- Week - 2 Day - 2 Machine Learning 2 - 3Document33 pagesWeek - 2 Day - 2 Machine Learning 2 - 3Aryush TripathiNo ratings yet
- AiML 4 3 SGDocument59 pagesAiML 4 3 SGngNo ratings yet
- Bản sao của Experimental Report 3Document10 pagesBản sao của Experimental Report 3Kiệt Như LêNo ratings yet
- Decision Tree LearningDocument16 pagesDecision Tree LearningAshish TiwariNo ratings yet
- Decision TreeDocument3 pagesDecision Treepriyanka bhasinNo ratings yet
- Lec 3&4Document20 pagesLec 3&4Hariharan RavichandranNo ratings yet
- Artificial Intelligence: Machine Learning Algorithms Id3 DbscanDocument30 pagesArtificial Intelligence: Machine Learning Algorithms Id3 Dbscanelgeneral0313No ratings yet
- Fisico Qui MicaDocument20 pagesFisico Qui MicaMatamoros De La Cruz JorgeNo ratings yet
- HK F3 Physics Notes - Total Internal ReflectionDocument5 pagesHK F3 Physics Notes - Total Internal ReflectionJohnNo ratings yet
- DM Chap4 Classification - IIIDocument60 pagesDM Chap4 Classification - IIIEngin ÖnerNo ratings yet
- Decision TreesDocument52 pagesDecision TreeslailaNo ratings yet
- Physical Sciences Pre-Midyear p1 Memo 2024Document12 pagesPhysical Sciences Pre-Midyear p1 Memo 2024Yolanda WillsonNo ratings yet
- Decision Tree.10.11Document31 pagesDecision Tree.10.11Oindrila SanyalNo ratings yet
- DM-Lecture Decision Trees (A)Document161 pagesDM-Lecture Decision Trees (A)Zain Ul AbedinNo ratings yet
- Session 4 - Multiple Linear RegressionDocument63 pagesSession 4 - Multiple Linear Regressionvoradhairya09No ratings yet
- Session 5 - Logistic RegressionDocument69 pagesSession 5 - Logistic Regressionvoradhairya09No ratings yet
- Session 3 - Linear RegressionDocument96 pagesSession 3 - Linear Regressionvoradhairya09No ratings yet
- Session 7 - Random ForestDocument8 pagesSession 7 - Random Forestvoradhairya09No ratings yet
- K.A. Worp - Trismegistos Online Publications 6Document78 pagesK.A. Worp - Trismegistos Online Publications 6fosco13No ratings yet
- Boolean OperationsDocument5 pagesBoolean OperationsKowsi MathiNo ratings yet
- Data Structures: Question 1. What Is Data Structure?Document36 pagesData Structures: Question 1. What Is Data Structure?Shreyas S RNo ratings yet
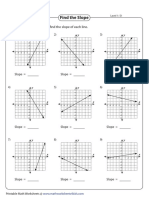
- Rise Over Run To Find Gradient With Given Graphs WSDocument2 pagesRise Over Run To Find Gradient With Given Graphs WSafzabbasi100% (1)
- The $25,000,000,000 Eigenvector: The Linear Algebra Behind GoogleDocument13 pagesThe $25,000,000,000 Eigenvector: The Linear Algebra Behind Googlebob sedgeNo ratings yet
- Cbse Solved Sample Papers For Class 9 Sa1 Maths 2015 16 Set 1Document16 pagesCbse Solved Sample Papers For Class 9 Sa1 Maths 2015 16 Set 1Ratul RanjanNo ratings yet
- 11 Chapter ModelDocument12 pages11 Chapter ModelKnighterrant VogabondNo ratings yet
- Eigenvalues and EigenvectorsDocument153 pagesEigenvalues and EigenvectorsBalayya BNo ratings yet
- Least Cost System Operation: Economic Dispatch 2: Smith College, EGR 325 March 10, 2006Document37 pagesLeast Cost System Operation: Economic Dispatch 2: Smith College, EGR 325 March 10, 2006DalessandroNo ratings yet
- Ch. 1 Digital Systems - TaggedDocument28 pagesCh. 1 Digital Systems - TaggedMaram AlsohimiNo ratings yet
- BREE J - Elastic-Plastic Behaviour of Thin Tubes Subjected To Internal PressureDocument14 pagesBREE J - Elastic-Plastic Behaviour of Thin Tubes Subjected To Internal PressureFrontonioNo ratings yet
- Circumference and Area of CirclesDocument43 pagesCircumference and Area of CirclesmaryroseNo ratings yet
- MS23 123Document7 pagesMS23 123BuiDucVinhNo ratings yet
- Cade MY: Vineet Loomba UnacademyDocument2 pagesCade MY: Vineet Loomba Unacademyanita rani paloNo ratings yet
- 2.1.4 The Coding SystemDocument35 pages2.1.4 The Coding SystemAmirul AminNo ratings yet
- Module: Linguistics: Linguistics Schools and MovementsDocument43 pagesModule: Linguistics: Linguistics Schools and MovementsMalak0% (1)
- Chapter 05Document88 pagesChapter 05Keith Tanaka MagakaNo ratings yet
- Moment of Inertia: I.E. P X (X) PXDocument6 pagesMoment of Inertia: I.E. P X (X) PXafzal taiNo ratings yet
- List of Triangle InequalitiesDocument21 pagesList of Triangle InequalitiesMagdy EssaftyNo ratings yet
- Beam Deflection CheckDocument7 pagesBeam Deflection Checkajith chandranNo ratings yet
- Emf David K Cheng PDFDocument9 pagesEmf David K Cheng PDFVarun Ramteke0% (2)
- L1 Conditional StatementsDocument17 pagesL1 Conditional StatementsCiprian PopNo ratings yet
- Ruin TheoryDocument29 pagesRuin TheoryAnonymous M8Bvu4FExNo ratings yet
- Elementary Mathematics Grade 6: Lesson GuideDocument11 pagesElementary Mathematics Grade 6: Lesson GuideGerald Jem BernandinoNo ratings yet
- Question Papers - Linear Prog. and ApplicationsDocument14 pagesQuestion Papers - Linear Prog. and ApplicationsshrutiNo ratings yet
- Running Head: Regression Analysis 1Document8 pagesRunning Head: Regression Analysis 1IbrahimNo ratings yet
- Gcse Maths Example Questions Chapter 5Document1 pageGcse Maths Example Questions Chapter 5JarishNo ratings yet
- DrapeDocument16 pagesDrapeEduardo Coello Flores100% (1)
- MOP Homework 2013Document7 pagesMOP Homework 2013NishantNo ratings yet