
Ruby Conf 2006: I18N, M17N, Unicode, and All That
Ruby Conf 2006: I18N, M17N, Unicode, and All That
You might also like
- Plano Motor ElectricoDocument1 pagePlano Motor ElectricoRogger H-c0% (1)
- MySQL Cluster TutorialDocument64 pagesMySQL Cluster TutorialOleksiy Kovyrin100% (3)
- Book UploadDocument270 pagesBook Uploadchuan88100% (20)
- Monti, Esquiline & San Lorenzo: Via VEDocument1 pageMonti, Esquiline & San Lorenzo: Via VEgatoNo ratings yet
- Economic Outlook 2011 - SchrodersDocument38 pagesEconomic Outlook 2011 - SchrodersArifin ManurungNo ratings yet
- Gucci FactureDocument1 pageGucci FactureflorianduplouyNo ratings yet
- Drawing2 ModelDocument1 pageDrawing2 ModelBilal HaiderNo ratings yet
- Drawing2 ModelDocument1 pageDrawing2 ModelBilal HaiderNo ratings yet
- Arpanet Information Brochure 1978Document30 pagesArpanet Information Brochure 1978binkyfishNo ratings yet
- TRUCKHUYUDocument1 pageTRUCKHUYUNgoc NguyenNo ratings yet
- Vintage Stereo Catalog 1977Document192 pagesVintage Stereo Catalog 1977jdap2000-1100% (2)
- Employability Skills 2nd Sem Final-148Document1 pageEmployability Skills 2nd Sem Final-148SAVITA MAURYANo ratings yet
- THANMAY1Document1 pageTHANMAY1bo himNo ratings yet
- CalculationDocument2 pagesCalculationrajith_lovezoneNo ratings yet
- Amblyopia, A Multidisciplinary ApproachDocument161 pagesAmblyopia, A Multidisciplinary ApproachTatianaGutuNo ratings yet
- Ke Baratan: Keterangan GambarDocument1 pageKe Baratan: Keterangan GambarNerossi Nya JonathanNo ratings yet
- LuxemburgoDocument30 pagesLuxemburgoBeatriz C. MeloNo ratings yet
- Diagram 6Document1 pageDiagram 6Tue TranNo ratings yet
- Book 1Document2 pagesBook 1paapuhomeNo ratings yet
- 19312241024.tugas Managemen FasilitasDocument2 pages19312241024.tugas Managemen FasilitasKhoirunnisa NisaNo ratings yet
- Quality Audit 2024Document29 pagesQuality Audit 2024Kaycee Murtz MendozaNo ratings yet
- Mapa de FlujosDocument1 pageMapa de FlujosEylen Johana Garcia LopezNo ratings yet
- Sander 3Document4 pagesSander 3Ibram PurnamaNo ratings yet
- Vidrio 2Document1 pageVidrio 2Diego SubiaNo ratings yet
- 7th To 12thDocument15 pages7th To 12thClarence MoretteNo ratings yet
- Dim Plato 160 y 200 Fundicion - Idwpapeltec SasDocument1 pageDim Plato 160 y 200 Fundicion - Idwpapeltec Sasluis acostaNo ratings yet
- ledakh-spiti-drive-direction1.ramkyDocument4 pagesledakh-spiti-drive-direction1.ramkyAjay RajpurohitNo ratings yet
- Celian Hill & San Giovanni: Via C La Ud IaDocument1 pageCelian Hill & San Giovanni: Via C La Ud IagatoNo ratings yet
- Lixadeira FitaDocument4 pagesLixadeira Fitaluizcarlosf8493No ratings yet
- Designed by Checked by Approved by Date DateDocument4 pagesDesigned by Checked by Approved by Date DateBogdan OvidiuNo ratings yet
- Templates For MPS and GPADocument8 pagesTemplates For MPS and GPARubilen Papasin SatinitiganNo ratings yet
- Tugas Statistika: 09211750054009 - CECILIA STEPHANIEDocument20 pagesTugas Statistika: 09211750054009 - CECILIA STEPHANIEiichimaru3No ratings yet
- Part2 PDFDocument1 pagePart2 PDFWilmer A. VargasNo ratings yet
- Part 2Document1 pagePart 2Wilmer A. VargasNo ratings yet
- Part2 PDFDocument1 pagePart2 PDFWilmer A. VargasNo ratings yet
- Book 1Document3 pagesBook 1Alice ZhangNo ratings yet
- Part 11 V3 Feuille1Document1 pagePart 11 V3 Feuille1gaaloul ghaithNo ratings yet
- A-A (1: 1) A B: Dise o de Aprobado Por FechaDocument1 pageA-A (1: 1) A B: Dise o de Aprobado Por Fechajosue sulca carrilloNo ratings yet
- Sim Bología: T Opot or - C O O R 2Document1 pageSim Bología: T Opot or - C O O R 2Domenica TobarNo ratings yet
- Surat Tugas PMMDocument7 pagesSurat Tugas PMMpulau kaungNo ratings yet
- MS Word 4 (Insert/chart ) : Bat Dulam Suren DorjDocument1 pageMS Word 4 (Insert/chart ) : Bat Dulam Suren DorjNaraa JaminNo ratings yet
- Lucru Individual InfoDocument3 pagesLucru Individual InfoАлёнка ШтефанкоNo ratings yet
- MIS Regional - Revision Coming SoonDocument21 pagesMIS Regional - Revision Coming SoonPrabhakar SvNo ratings yet
- Personnel File Audit Checklist 1Document2 pagesPersonnel File Audit Checklist 1Davy Arnold KombilaNo ratings yet
- Eje 1Document1 pageEje 1Stiven MitisNo ratings yet
- Determination of Particle Size Distribution - Sieve AnalysisDocument25 pagesDetermination of Particle Size Distribution - Sieve Analysisblast.scribdNo ratings yet
- TD TP 1Document8 pagesTD TP 1Andrei ImashauNo ratings yet
- Truckhuyu 2Document1 pageTruckhuyu 2Đức Nguyễn VănNo ratings yet
- Truckhuyu 1Document1 pageTruckhuyu 1Đức Nguyễn VănNo ratings yet
- Via de Gig Lid 'O Ro: Largo ChigiDocument1 pageVia de Gig Lid 'O Ro: Largo ChigigatoNo ratings yet
- Anexo 7Document1 pageAnexo 7christianNo ratings yet
- Astro ChakraDocument1 pageAstro ChakraAmarprit RaenooNo ratings yet
- Sensibilidad NaftaDocument755 pagesSensibilidad NaftaJean Carlos Quispe De La CruzNo ratings yet
- Book 1Document2 pagesBook 1Genevieve Galariana De RodaNo ratings yet
- R 152a Diagrama de Refrigerante P-HDocument1 pageR 152a Diagrama de Refrigerante P-HJose LuisNo ratings yet
- Via de Gli An Nibald I Via Del Faguta Le: Via D El Bo Sche TtoDocument1 pageVia de Gli An Nibald I Via Del Faguta Le: Via D El Bo Sche TtogatoNo ratings yet
- Kalmus Model 210LC Instruction ManualDocument17 pagesKalmus Model 210LC Instruction ManualrdzoetenNo ratings yet
- Afar Test Bank Afar Test BankDocument257 pagesAfar Test Bank Afar Test BankJaceNo ratings yet
- Tapak Atas Kiri OrdinateDocument1 pageTapak Atas Kiri OrdinateAbdcareem MohdNo ratings yet
- Chart Title: Tra Fco Ay Se CR Uz An Pu BL Ico LL en o Ma LL Uv Io So Ed or Mi Do S Ev en Tu Al EsDocument3 pagesChart Title: Tra Fco Ay Se CR Uz An Pu BL Ico LL en o Ma LL Uv Io So Ed or Mi Do S Ev en Tu Al EsJoshua Vinicio LascanoNo ratings yet
- 25 May 24 - Work PlanDocument1 page25 May 24 - Work PlanBreezy Buzy OnNo ratings yet
- Deploying IP UnicastDocument83 pagesDeploying IP UnicastOleksiy KovyrinNo ratings yet
- Interview With Stana KaticDocument5 pagesInterview With Stana KaticOleksiy KovyrinNo ratings yet
- MySQL and SSD: Usage PatternsDocument29 pagesMySQL and SSD: Usage PatternsOleksiy KovyrinNo ratings yet
- Metadata Locking and Deadlock Detection in MySQL 5.5Document14 pagesMetadata Locking and Deadlock Detection in MySQL 5.5Oleksiy KovyrinNo ratings yet
- Granular Archival and Nearline Storage Using MySQL, S3 and SQS PresentationDocument28 pagesGranular Archival and Nearline Storage Using MySQL, S3 and SQS PresentationOleksiy KovyrinNo ratings yet
- MySQL and Linux Tuning - Better TogetherDocument26 pagesMySQL and Linux Tuning - Better TogetherOleksiy Kovyrin100% (1)
- A Code Stub Generator For MySQL and Drizzle Plugins PresentationDocument29 pagesA Code Stub Generator For MySQL and Drizzle Plugins PresentationOleksiy KovyrinNo ratings yet
- Lessons Learned: Scaling A Social NetworkDocument52 pagesLessons Learned: Scaling A Social NetworkOleksiy KovyrinNo ratings yet
- Dynamic ColumnsDocument18 pagesDynamic ColumnsOleksiy KovyrinNo ratings yet
- Large Datasets in MySQL On Amazon EC2Document30 pagesLarge Datasets in MySQL On Amazon EC2Oleksiy KovyrinNo ratings yet
- Forecasting MySQL Performance and ScalabilityDocument41 pagesForecasting MySQL Performance and ScalabilityOleksiy Kovyrin100% (1)
- Automated, Non-Stop MySQL Operations and Failover PresentationDocument46 pagesAutomated, Non-Stop MySQL Operations and Failover PresentationOleksiy Kovyrin100% (1)
- Data in The Cloud PresentationDocument13 pagesData in The Cloud PresentationOleksiy KovyrinNo ratings yet
- Bottom-Up Database BenchmarkingDocument43 pagesBottom-Up Database BenchmarkingOleksiy KovyrinNo ratings yet
- Advanced Replication Monitoring PresentationDocument13 pagesAdvanced Replication Monitoring PresentationOleksiy Kovyrin100% (1)
- A Beginner's Guide To MariaDB PresentationDocument26 pagesA Beginner's Guide To MariaDB PresentationOleksiy Kovyrin67% (3)
- Linux and H/W Optimizations For MySQLDocument160 pagesLinux and H/W Optimizations For MySQLOleksiy Kovyrin100% (2)
- Top 10 Lessons Learned From Deploying Hadoop in A Private CloudDocument33 pagesTop 10 Lessons Learned From Deploying Hadoop in A Private Cloudwrite2bapunNo ratings yet
- Zipcar Incident ReportDocument2 pagesZipcar Incident ReportOleksiy KovyrinNo ratings yet
- Search Analytics With Flume and HBaseDocument24 pagesSearch Analytics With Flume and HBaseOleksiy KovyrinNo ratings yet
- Heres A Suggestion For A Cheap Breakfast in Aling Dory's CarinderiaDocument1 pageHeres A Suggestion For A Cheap Breakfast in Aling Dory's CarinderiaCecille M. ValenzuelaNo ratings yet
- Manual Mantenimiento Service Manual Sato Cl608 EsDocument56 pagesManual Mantenimiento Service Manual Sato Cl608 EsJosé Antonio VoyageNo ratings yet
- Digital Number System: Dr. Hazlina MD YusofDocument37 pagesDigital Number System: Dr. Hazlina MD YusofAmir SollehinNo ratings yet
- Codificacion. BCH PDFDocument5 pagesCodificacion. BCH PDFDaniela Cardenas LuboNo ratings yet
- 9010 Learner GuideDocument62 pages9010 Learner Guideflame mageNo ratings yet
- Number SystemsDocument35 pagesNumber SystemshasithrNo ratings yet
- Belanova - Rosa PastelDocument5 pagesBelanova - Rosa PastelRafael LeceaNo ratings yet
- Vlsi Iiest SBDocument45 pagesVlsi Iiest SBUshaRaniDashNo ratings yet
- A Simple Intro To The Hexadecimal SystemDocument11 pagesA Simple Intro To The Hexadecimal SystemiikshsdahfeNo ratings yet
- Thermal Control Board User Manual 1Document15 pagesThermal Control Board User Manual 1Nguyễn Quý NhậtNo ratings yet
- Delta Menurae AlphabetDocument1 pageDelta Menurae AlphabetAVLNo ratings yet
- DDS Assignment 1Document4 pagesDDS Assignment 1syedsalmanali91No ratings yet
- Fontselection in Latex PDFDocument29 pagesFontselection in Latex PDFHimanshuNo ratings yet
- PayloadDocument2 pagesPayloadargentynskiepesossNo ratings yet
- Perl TutorialDocument6 pagesPerl TutoriallearnwithvideotutorialsNo ratings yet
- Custom Number Formatting Codes PDFDocument1 pageCustom Number Formatting Codes PDFMukesh DakNo ratings yet
- Old English CalligraphyDocument9 pagesOld English Calligraphydonna faye OticNo ratings yet
- Write A Secret Message!: How To Talk Like A PilotDocument1 pageWrite A Secret Message!: How To Talk Like A PilotSyaima'a AripinNo ratings yet
- Telugu Translation Methods - Budaraju Radha KrishnaDocument69 pagesTelugu Translation Methods - Budaraju Radha KrishnabodhanaNo ratings yet
- MorseDocument2 pagesMorseIcha DacasthaNo ratings yet
- ??? Font Generator ? Copy Paste FriendlyDocument7 pages??? Font Generator ? Copy Paste FriendlySai SreeNo ratings yet
- Addition and Subtraction of Similar and Dissimilar FractionDocument20 pagesAddition and Subtraction of Similar and Dissimilar FractionRose-Salie OcdenNo ratings yet
- Digital Electronics AssignmentDocument22 pagesDigital Electronics AssignmentshanmugapriyaaNo ratings yet
- RPH M3Document15 pagesRPH M3MITCHELL WONG MoeNo ratings yet
- CSL 210: Data Structures With Applications: Module3: IIIT NagpurDocument11 pagesCSL 210: Data Structures With Applications: Module3: IIIT NagpurayushNo ratings yet
- Malayalam Orthographic Reforms - Impact On Language and Popular CultureDocument19 pagesMalayalam Orthographic Reforms - Impact On Language and Popular CultureHaikal Fatur Rozi MustofaNo ratings yet
- Visvesvaraya Technological University Belagavi, Karnataka-590 018Document2 pagesVisvesvaraya Technological University Belagavi, Karnataka-590 018Rajath KamathNo ratings yet
- 8085 Microprocessor Laboratory Solution Manual: Department of Electronics West Bengal State UniversityDocument17 pages8085 Microprocessor Laboratory Solution Manual: Department of Electronics West Bengal State UniversitySupriyo SrimaniNo ratings yet
- Number Systemss From BCA-121 Computer Fundamental PDFDocument14 pagesNumber Systemss From BCA-121 Computer Fundamental PDFUdeshika Wanninayake100% (1)
- Learning and Remembering Morse CodeDocument6 pagesLearning and Remembering Morse Codeisaac setabiNo ratings yet

























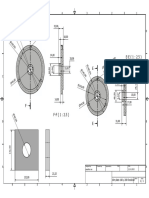








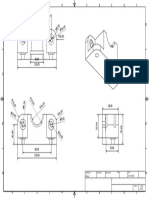

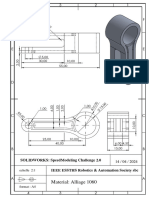








































































Download as pdf or txt
You might also like
- Plano Motor ElectricoDocument1 pagePlano Motor ElectricoRogger H-c0% (1)
- MySQL Cluster TutorialDocument64 pagesMySQL Cluster TutorialOleksiy Kovyrin100% (3)
- Book UploadDocument270 pagesBook Uploadchuan88100% (20)
- Monti, Esquiline & San Lorenzo: Via VEDocument1 pageMonti, Esquiline & San Lorenzo: Via VEgatoNo ratings yet
- Economic Outlook 2011 - SchrodersDocument38 pagesEconomic Outlook 2011 - SchrodersArifin ManurungNo ratings yet
- Gucci FactureDocument1 pageGucci FactureflorianduplouyNo ratings yet
- Drawing2 ModelDocument1 pageDrawing2 ModelBilal HaiderNo ratings yet
- Drawing2 ModelDocument1 pageDrawing2 ModelBilal HaiderNo ratings yet
- Arpanet Information Brochure 1978Document30 pagesArpanet Information Brochure 1978binkyfishNo ratings yet
- TRUCKHUYUDocument1 pageTRUCKHUYUNgoc NguyenNo ratings yet
- Vintage Stereo Catalog 1977Document192 pagesVintage Stereo Catalog 1977jdap2000-1100% (2)
- Employability Skills 2nd Sem Final-148Document1 pageEmployability Skills 2nd Sem Final-148SAVITA MAURYANo ratings yet
- THANMAY1Document1 pageTHANMAY1bo himNo ratings yet
- CalculationDocument2 pagesCalculationrajith_lovezoneNo ratings yet
- Amblyopia, A Multidisciplinary ApproachDocument161 pagesAmblyopia, A Multidisciplinary ApproachTatianaGutuNo ratings yet
- Ke Baratan: Keterangan GambarDocument1 pageKe Baratan: Keterangan GambarNerossi Nya JonathanNo ratings yet
- LuxemburgoDocument30 pagesLuxemburgoBeatriz C. MeloNo ratings yet
- Diagram 6Document1 pageDiagram 6Tue TranNo ratings yet
- Book 1Document2 pagesBook 1paapuhomeNo ratings yet
- 19312241024.tugas Managemen FasilitasDocument2 pages19312241024.tugas Managemen FasilitasKhoirunnisa NisaNo ratings yet
- Quality Audit 2024Document29 pagesQuality Audit 2024Kaycee Murtz MendozaNo ratings yet
- Mapa de FlujosDocument1 pageMapa de FlujosEylen Johana Garcia LopezNo ratings yet
- Sander 3Document4 pagesSander 3Ibram PurnamaNo ratings yet
- Vidrio 2Document1 pageVidrio 2Diego SubiaNo ratings yet
- 7th To 12thDocument15 pages7th To 12thClarence MoretteNo ratings yet
- Dim Plato 160 y 200 Fundicion - Idwpapeltec SasDocument1 pageDim Plato 160 y 200 Fundicion - Idwpapeltec Sasluis acostaNo ratings yet
- ledakh-spiti-drive-direction1.ramkyDocument4 pagesledakh-spiti-drive-direction1.ramkyAjay RajpurohitNo ratings yet
- Celian Hill & San Giovanni: Via C La Ud IaDocument1 pageCelian Hill & San Giovanni: Via C La Ud IagatoNo ratings yet
- Lixadeira FitaDocument4 pagesLixadeira Fitaluizcarlosf8493No ratings yet
- Designed by Checked by Approved by Date DateDocument4 pagesDesigned by Checked by Approved by Date DateBogdan OvidiuNo ratings yet
- Templates For MPS and GPADocument8 pagesTemplates For MPS and GPARubilen Papasin SatinitiganNo ratings yet
- Tugas Statistika: 09211750054009 - CECILIA STEPHANIEDocument20 pagesTugas Statistika: 09211750054009 - CECILIA STEPHANIEiichimaru3No ratings yet
- Part2 PDFDocument1 pagePart2 PDFWilmer A. VargasNo ratings yet
- Part 2Document1 pagePart 2Wilmer A. VargasNo ratings yet
- Part2 PDFDocument1 pagePart2 PDFWilmer A. VargasNo ratings yet
- Book 1Document3 pagesBook 1Alice ZhangNo ratings yet
- Part 11 V3 Feuille1Document1 pagePart 11 V3 Feuille1gaaloul ghaithNo ratings yet
- A-A (1: 1) A B: Dise o de Aprobado Por FechaDocument1 pageA-A (1: 1) A B: Dise o de Aprobado Por Fechajosue sulca carrilloNo ratings yet
- Sim Bología: T Opot or - C O O R 2Document1 pageSim Bología: T Opot or - C O O R 2Domenica TobarNo ratings yet
- Surat Tugas PMMDocument7 pagesSurat Tugas PMMpulau kaungNo ratings yet
- MS Word 4 (Insert/chart ) : Bat Dulam Suren DorjDocument1 pageMS Word 4 (Insert/chart ) : Bat Dulam Suren DorjNaraa JaminNo ratings yet
- Lucru Individual InfoDocument3 pagesLucru Individual InfoАлёнка ШтефанкоNo ratings yet
- MIS Regional - Revision Coming SoonDocument21 pagesMIS Regional - Revision Coming SoonPrabhakar SvNo ratings yet
- Personnel File Audit Checklist 1Document2 pagesPersonnel File Audit Checklist 1Davy Arnold KombilaNo ratings yet
- Eje 1Document1 pageEje 1Stiven MitisNo ratings yet
- Determination of Particle Size Distribution - Sieve AnalysisDocument25 pagesDetermination of Particle Size Distribution - Sieve Analysisblast.scribdNo ratings yet
- TD TP 1Document8 pagesTD TP 1Andrei ImashauNo ratings yet
- Truckhuyu 2Document1 pageTruckhuyu 2Đức Nguyễn VănNo ratings yet
- Truckhuyu 1Document1 pageTruckhuyu 1Đức Nguyễn VănNo ratings yet
- Via de Gig Lid 'O Ro: Largo ChigiDocument1 pageVia de Gig Lid 'O Ro: Largo ChigigatoNo ratings yet
- Anexo 7Document1 pageAnexo 7christianNo ratings yet
- Astro ChakraDocument1 pageAstro ChakraAmarprit RaenooNo ratings yet
- Sensibilidad NaftaDocument755 pagesSensibilidad NaftaJean Carlos Quispe De La CruzNo ratings yet
- Book 1Document2 pagesBook 1Genevieve Galariana De RodaNo ratings yet
- R 152a Diagrama de Refrigerante P-HDocument1 pageR 152a Diagrama de Refrigerante P-HJose LuisNo ratings yet
- Via de Gli An Nibald I Via Del Faguta Le: Via D El Bo Sche TtoDocument1 pageVia de Gli An Nibald I Via Del Faguta Le: Via D El Bo Sche TtogatoNo ratings yet
- Kalmus Model 210LC Instruction ManualDocument17 pagesKalmus Model 210LC Instruction ManualrdzoetenNo ratings yet
- Afar Test Bank Afar Test BankDocument257 pagesAfar Test Bank Afar Test BankJaceNo ratings yet
- Tapak Atas Kiri OrdinateDocument1 pageTapak Atas Kiri OrdinateAbdcareem MohdNo ratings yet
- Chart Title: Tra Fco Ay Se CR Uz An Pu BL Ico LL en o Ma LL Uv Io So Ed or Mi Do S Ev en Tu Al EsDocument3 pagesChart Title: Tra Fco Ay Se CR Uz An Pu BL Ico LL en o Ma LL Uv Io So Ed or Mi Do S Ev en Tu Al EsJoshua Vinicio LascanoNo ratings yet
- 25 May 24 - Work PlanDocument1 page25 May 24 - Work PlanBreezy Buzy OnNo ratings yet
- Deploying IP UnicastDocument83 pagesDeploying IP UnicastOleksiy KovyrinNo ratings yet
- Interview With Stana KaticDocument5 pagesInterview With Stana KaticOleksiy KovyrinNo ratings yet
- MySQL and SSD: Usage PatternsDocument29 pagesMySQL and SSD: Usage PatternsOleksiy KovyrinNo ratings yet
- Metadata Locking and Deadlock Detection in MySQL 5.5Document14 pagesMetadata Locking and Deadlock Detection in MySQL 5.5Oleksiy KovyrinNo ratings yet
- Granular Archival and Nearline Storage Using MySQL, S3 and SQS PresentationDocument28 pagesGranular Archival and Nearline Storage Using MySQL, S3 and SQS PresentationOleksiy KovyrinNo ratings yet
- MySQL and Linux Tuning - Better TogetherDocument26 pagesMySQL and Linux Tuning - Better TogetherOleksiy Kovyrin100% (1)
- A Code Stub Generator For MySQL and Drizzle Plugins PresentationDocument29 pagesA Code Stub Generator For MySQL and Drizzle Plugins PresentationOleksiy KovyrinNo ratings yet
- Lessons Learned: Scaling A Social NetworkDocument52 pagesLessons Learned: Scaling A Social NetworkOleksiy KovyrinNo ratings yet
- Dynamic ColumnsDocument18 pagesDynamic ColumnsOleksiy KovyrinNo ratings yet
- Large Datasets in MySQL On Amazon EC2Document30 pagesLarge Datasets in MySQL On Amazon EC2Oleksiy KovyrinNo ratings yet
- Forecasting MySQL Performance and ScalabilityDocument41 pagesForecasting MySQL Performance and ScalabilityOleksiy Kovyrin100% (1)
- Automated, Non-Stop MySQL Operations and Failover PresentationDocument46 pagesAutomated, Non-Stop MySQL Operations and Failover PresentationOleksiy Kovyrin100% (1)
- Data in The Cloud PresentationDocument13 pagesData in The Cloud PresentationOleksiy KovyrinNo ratings yet
- Bottom-Up Database BenchmarkingDocument43 pagesBottom-Up Database BenchmarkingOleksiy KovyrinNo ratings yet
- Advanced Replication Monitoring PresentationDocument13 pagesAdvanced Replication Monitoring PresentationOleksiy Kovyrin100% (1)
- A Beginner's Guide To MariaDB PresentationDocument26 pagesA Beginner's Guide To MariaDB PresentationOleksiy Kovyrin67% (3)
- Linux and H/W Optimizations For MySQLDocument160 pagesLinux and H/W Optimizations For MySQLOleksiy Kovyrin100% (2)
- Top 10 Lessons Learned From Deploying Hadoop in A Private CloudDocument33 pagesTop 10 Lessons Learned From Deploying Hadoop in A Private Cloudwrite2bapunNo ratings yet
- Zipcar Incident ReportDocument2 pagesZipcar Incident ReportOleksiy KovyrinNo ratings yet
- Search Analytics With Flume and HBaseDocument24 pagesSearch Analytics With Flume and HBaseOleksiy KovyrinNo ratings yet
- Heres A Suggestion For A Cheap Breakfast in Aling Dory's CarinderiaDocument1 pageHeres A Suggestion For A Cheap Breakfast in Aling Dory's CarinderiaCecille M. ValenzuelaNo ratings yet
- Manual Mantenimiento Service Manual Sato Cl608 EsDocument56 pagesManual Mantenimiento Service Manual Sato Cl608 EsJosé Antonio VoyageNo ratings yet
- Digital Number System: Dr. Hazlina MD YusofDocument37 pagesDigital Number System: Dr. Hazlina MD YusofAmir SollehinNo ratings yet
- Codificacion. BCH PDFDocument5 pagesCodificacion. BCH PDFDaniela Cardenas LuboNo ratings yet
- 9010 Learner GuideDocument62 pages9010 Learner Guideflame mageNo ratings yet
- Number SystemsDocument35 pagesNumber SystemshasithrNo ratings yet
- Belanova - Rosa PastelDocument5 pagesBelanova - Rosa PastelRafael LeceaNo ratings yet
- Vlsi Iiest SBDocument45 pagesVlsi Iiest SBUshaRaniDashNo ratings yet
- A Simple Intro To The Hexadecimal SystemDocument11 pagesA Simple Intro To The Hexadecimal SystemiikshsdahfeNo ratings yet
- Thermal Control Board User Manual 1Document15 pagesThermal Control Board User Manual 1Nguyễn Quý NhậtNo ratings yet
- Delta Menurae AlphabetDocument1 pageDelta Menurae AlphabetAVLNo ratings yet
- DDS Assignment 1Document4 pagesDDS Assignment 1syedsalmanali91No ratings yet
- Fontselection in Latex PDFDocument29 pagesFontselection in Latex PDFHimanshuNo ratings yet
- PayloadDocument2 pagesPayloadargentynskiepesossNo ratings yet
- Perl TutorialDocument6 pagesPerl TutoriallearnwithvideotutorialsNo ratings yet
- Custom Number Formatting Codes PDFDocument1 pageCustom Number Formatting Codes PDFMukesh DakNo ratings yet
- Old English CalligraphyDocument9 pagesOld English Calligraphydonna faye OticNo ratings yet
- Write A Secret Message!: How To Talk Like A PilotDocument1 pageWrite A Secret Message!: How To Talk Like A PilotSyaima'a AripinNo ratings yet
- Telugu Translation Methods - Budaraju Radha KrishnaDocument69 pagesTelugu Translation Methods - Budaraju Radha KrishnabodhanaNo ratings yet
- MorseDocument2 pagesMorseIcha DacasthaNo ratings yet
- ??? Font Generator ? Copy Paste FriendlyDocument7 pages??? Font Generator ? Copy Paste FriendlySai SreeNo ratings yet
- Addition and Subtraction of Similar and Dissimilar FractionDocument20 pagesAddition and Subtraction of Similar and Dissimilar FractionRose-Salie OcdenNo ratings yet
- Digital Electronics AssignmentDocument22 pagesDigital Electronics AssignmentshanmugapriyaaNo ratings yet
- RPH M3Document15 pagesRPH M3MITCHELL WONG MoeNo ratings yet
- CSL 210: Data Structures With Applications: Module3: IIIT NagpurDocument11 pagesCSL 210: Data Structures With Applications: Module3: IIIT NagpurayushNo ratings yet
- Malayalam Orthographic Reforms - Impact On Language and Popular CultureDocument19 pagesMalayalam Orthographic Reforms - Impact On Language and Popular CultureHaikal Fatur Rozi MustofaNo ratings yet
- Visvesvaraya Technological University Belagavi, Karnataka-590 018Document2 pagesVisvesvaraya Technological University Belagavi, Karnataka-590 018Rajath KamathNo ratings yet
- 8085 Microprocessor Laboratory Solution Manual: Department of Electronics West Bengal State UniversityDocument17 pages8085 Microprocessor Laboratory Solution Manual: Department of Electronics West Bengal State UniversitySupriyo SrimaniNo ratings yet
- Number Systemss From BCA-121 Computer Fundamental PDFDocument14 pagesNumber Systemss From BCA-121 Computer Fundamental PDFUdeshika Wanninayake100% (1)
- Learning and Remembering Morse CodeDocument6 pagesLearning and Remembering Morse Codeisaac setabiNo ratings yet