Download as pdf or txt
You might also like
- JBL Audio Engineering for Sound ReinforcementFrom EverandJBL Audio Engineering for Sound ReinforcementRating: 5 out of 5 stars5/5 (2)
- ThesisDocument18 pagesThesisapi-29776055293% (15)
- 3D Spacial Impulse Response RenderingDocument10 pages3D Spacial Impulse Response RenderingFederico Nahuel CacavelosNo ratings yet
- Marwari Wedding For DummiesDocument8 pagesMarwari Wedding For DummieslokeshtodiNo ratings yet
- Synthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezDocument5 pagesSynthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezZellagui EnergyNo ratings yet
- Voice Source Parameters Estimation by FiDocument5 pagesVoice Source Parameters Estimation by Figerardo7martinez-13No ratings yet
- Formant SynthesisDocument21 pagesFormant SynthesisameshlalNo ratings yet
- Predobro Za Konctrukciju FilteraDocument8 pagesPredobro Za Konctrukciju FilteraElvir Čolak Ope-PastuhNo ratings yet
- Voice Morphing Seminar ReportDocument36 pagesVoice Morphing Seminar ReportVinay ReddyNo ratings yet
- Cambridge University Engineering Department Trumpington Street, Cambridge, England, CB2 1PZDocument4 pagesCambridge University Engineering Department Trumpington Street, Cambridge, England, CB2 1PZBhuvan GuptaNo ratings yet
- Epoch Extraction From Speech Signals: K. Sri Rama Murty and B. Yegnanarayana, Senior Member, IEEEDocument12 pagesEpoch Extraction From Speech Signals: K. Sri Rama Murty and B. Yegnanarayana, Senior Member, IEEEVishnu_SairamNo ratings yet
- McAulay-Quatieri Technique v1Document11 pagesMcAulay-Quatieri Technique v1Kevin DiazNo ratings yet
- Phasenoise HajimiriDocument16 pagesPhasenoise HajimiriMan Mohan GoelNo ratings yet
- Juhan Nam Vesa VälimäkiDocument6 pagesJuhan Nam Vesa VälimäkiHerman HesseNo ratings yet
- Measuring Distortion in Amplifiers - PetrovDocument38 pagesMeasuring Distortion in Amplifiers - Petrovpuji yatmiNo ratings yet
- Hani ThesisDocument160 pagesHani ThesisHani C YehiaNo ratings yet
- Aes2001 Bonada PDFDocument10 pagesAes2001 Bonada PDFjfkNo ratings yet
- Voice Conversion by Prosody and Vocal Tract Modification: K. Sreenivasa Rao B. YegnanarayanaDocument6 pagesVoice Conversion by Prosody and Vocal Tract Modification: K. Sreenivasa Rao B. Yegnanarayanaleonunes80No ratings yet
- Speech Sound Production: Recognition Using Recurrent Neural NetworksDocument20 pagesSpeech Sound Production: Recognition Using Recurrent Neural NetworkstatiturihariNo ratings yet
- Luc Koe JASA2005 BDocument11 pagesLuc Koe JASA2005 BPauloGonçalvesNo ratings yet
- Correlation Network Model of Auditory Processing: CNRS - Ircam, 4 Place Igor Stravinsky, 75004, Paris, FRANCEDocument6 pagesCorrelation Network Model of Auditory Processing: CNRS - Ircam, 4 Place Igor Stravinsky, 75004, Paris, FRANCEShashi BarotNo ratings yet
- Convention Paper 5452: Audio Engineering SocietyDocument10 pagesConvention Paper 5452: Audio Engineering SocietyNathalia Parra GarzaNo ratings yet
- Speech Coding With Wavelet Packet Excitation Signal CompressionDocument8 pagesSpeech Coding With Wavelet Packet Excitation Signal CompressionptknNo ratings yet
- The Basic Properties of SpeechDocument3 pagesThe Basic Properties of Speechjeysam0% (1)
- Pitch Synchronous SpectrogramDocument32 pagesPitch Synchronous Spectrogramadelradwan474No ratings yet
- Bros Sier 04 Fast NotesDocument6 pagesBros Sier 04 Fast NotesfddddddNo ratings yet
- Lecture Notes 10 - Monday 7/10: Summary of Last LectureDocument5 pagesLecture Notes 10 - Monday 7/10: Summary of Last LecturemahdiwisfulNo ratings yet
- McCree MixedExcitationLPCVocoderModel ieeetSAP95Document9 pagesMcCree MixedExcitationLPCVocoderModel ieeetSAP95ΚουρδιστόςΑνανάςNo ratings yet
- Table Lookup Oscillators Using Generic Integrated WavetablesDocument4 pagesTable Lookup Oscillators Using Generic Integrated WavetablesPhilip KentNo ratings yet
- Voice MorphingDocument31 pagesVoice Morphingapi-382700092% (13)
- The Information Content of Demodulated Speech: Gregory Sell Malcolm SlaneyDocument4 pagesThe Information Content of Demodulated Speech: Gregory Sell Malcolm Slaneyele_shahad83No ratings yet
- The Cepstrum MethodDocument31 pagesThe Cepstrum MethodNiranjan ReddyNo ratings yet
- Audio Analysis Using The Discrete Wavelet Transform: 1 2 Related WorkDocument6 pagesAudio Analysis Using The Discrete Wavelet Transform: 1 2 Related WorkAlexandro NababanNo ratings yet
- A Practical Handbook of Speech CodersDocument15 pagesA Practical Handbook of Speech CodersVany BraunNo ratings yet
- Measured Distortion in AmplifiersDocument25 pagesMeasured Distortion in Amplifierspuji yatmiNo ratings yet
- Jnam Taslp2010 PDFDocument13 pagesJnam Taslp2010 PDFKai AhoNo ratings yet
- 2ch SRSDocument5 pages2ch SRSmaurizio_verdecchiaNo ratings yet
- Spectral Envelope Estimation and Representation For Sound Analysis-SynthesisDocument4 pagesSpectral Envelope Estimation and Representation For Sound Analysis-SynthesisHussein RazaqNo ratings yet
- RaoK S Prasannas R M Yegna2007Document4 pagesRaoK S Prasannas R M Yegna2007monica_804238794No ratings yet
- Temporally Weighted Linear Prediction Features For Tackling Additive Noise in Speaker VerificationDocument4 pagesTemporally Weighted Linear Prediction Features For Tackling Additive Noise in Speaker Verificationsathish14singhNo ratings yet
- Trombone Synthesis by Model and MeasurementDocument14 pagesTrombone Synthesis by Model and MeasurementMarcSanchisMartínezNo ratings yet
- Implementing Loudness Models in MatlabDocument5 pagesImplementing Loudness Models in MatlabPro AcousticNo ratings yet
- Horn Measurement - PaperDocument6 pagesHorn Measurement - PaperSara BassoNo ratings yet
- Boll79 SuppressionAcousticNoiseSpectralSubtraction PDFDocument8 pagesBoll79 SuppressionAcousticNoiseSpectralSubtraction PDFNguyễn Trí PhướcNo ratings yet
- Testing Loudspeakers With WaveletsDocument23 pagesTesting Loudspeakers With WaveletsyogimgurtNo ratings yet
- Optical Phase Conjugation Technique Using Four-Wave Mixing in Semiconductor Optical AmplifierDocument2 pagesOptical Phase Conjugation Technique Using Four-Wave Mixing in Semiconductor Optical AmplifierDang ShinichiNo ratings yet
- Voice MorphingDocument33 pagesVoice MorphinggrandhiramamurthyNo ratings yet
- Digital Representations of Speech SignalsDocument18 pagesDigital Representations of Speech SignalsMohammed RiyazuddinNo ratings yet
- Speech Signal ProcessingDocument173 pagesSpeech Signal ProcessingLizy Abraham100% (2)
- Voice Morphing Seminar ReportDocument31 pagesVoice Morphing Seminar ReportJerin Antony100% (5)
- PadovaniDocument4 pagesPadovaniQiyanNo ratings yet
- Gain Normalization in BPS Homomorphic Vocoder: Jae Chung and Ronald SchaferDocument5 pagesGain Normalization in BPS Homomorphic Vocoder: Jae Chung and Ronald SchaferPavan KulkarniNo ratings yet
- (Acoustical Model of Ear) : Name: Alaa Ashraf Abdelmoneim Elagrody Sec.:1 ID.:1Document9 pages(Acoustical Model of Ear) : Name: Alaa Ashraf Abdelmoneim Elagrody Sec.:1 ID.:1alaa elagrodiNo ratings yet
- Voice Morphing Final ReportDocument33 pagesVoice Morphing Final ReportrahuljindalNo ratings yet
- Acoustical ParametersDocument26 pagesAcoustical ParametersFederico Nahuel CacavelosNo ratings yet
- 752 Frequency ModulationDocument10 pages752 Frequency ModulationMiki ArsovskiNo ratings yet
- Time Frequency Analysis and Wavelet Transform Tutorial Time-Frequency Analysis For Voiceprint (Speaker) RecognitionDocument22 pagesTime Frequency Analysis and Wavelet Transform Tutorial Time-Frequency Analysis For Voiceprint (Speaker) RecognitionCan AlptekinNo ratings yet
- Speech AssignmentDocument4 pagesSpeech AssignmentAnithPalatNo ratings yet
- Phase Noise and Timing Jitter in Oscillators With Colored-Noise SourcesDocument10 pagesPhase Noise and Timing Jitter in Oscillators With Colored-Noise SourcesPournamy RameezNo ratings yet
- HST.582J / 6.555J / 16.456J Biomedical Signal and Image ProcessingDocument12 pagesHST.582J / 6.555J / 16.456J Biomedical Signal and Image ProcessingShafayet UddinNo ratings yet
- Spline and Spline Wavelet Methods with Applications to Signal and Image Processing: Volume III: Selected TopicsFrom EverandSpline and Spline Wavelet Methods with Applications to Signal and Image Processing: Volume III: Selected TopicsNo ratings yet
- Consoles Guide 2015Document28 pagesConsoles Guide 2015Artist RecordingNo ratings yet
- Microphone Guide 2012Document32 pagesMicrophone Guide 2012Artist Recording100% (1)
- Theatre Guide Live 2014 DigitalDocument24 pagesTheatre Guide Live 2014 DigitalArtist RecordingNo ratings yet
- Music Salary Guide PDFDocument24 pagesMusic Salary Guide PDFSusan JonesNo ratings yet
- Home Studio Series Vol4Document8 pagesHome Studio Series Vol4Artist Recording100% (3)
- Consoles 2014Document44 pagesConsoles 2014Artist Recording100% (1)
- Noise ReductionDocument112 pagesNoise ReductionnosoyninjaNo ratings yet
- Waves StoryDocument4 pagesWaves StoryArtist RecordingNo ratings yet
- IZotope Mixing Guide Principles Tips TechniquesDocument70 pagesIZotope Mixing Guide Principles Tips TechniquesRobinson Andress100% (1)
- Izotope Mastering Guide-Mastering With Ozone PDFDocument81 pagesIzotope Mastering Guide-Mastering With Ozone PDFOscar Pacheco100% (1)
- Console Guide 2013Document52 pagesConsole Guide 2013Artist Recording100% (1)
- 37 Recording TipsDocument3 pages37 Recording TipsIrwin B. GalinoNo ratings yet
- The Mastering ProcessDocument1 pageThe Mastering ProcessArtist RecordingNo ratings yet
- Refining The Details in Your Audio ProductionDocument4 pagesRefining The Details in Your Audio ProductionArtist RecordingNo ratings yet
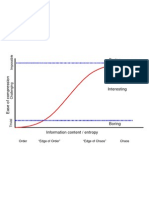
- Boring: Order "Edge of Order" "Edge of Chaos" ChaosDocument1 pageBoring: Order "Edge of Order" "Edge of Chaos" ChaosArtist RecordingNo ratings yet
- The Art of Equalization For Custom Home TheatersDocument3 pagesThe Art of Equalization For Custom Home TheatersArtist RecordingNo ratings yet
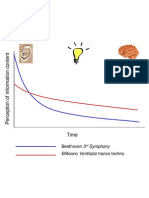
- Beethoven 3 Elbeano Ventilator Trance Techno: SymphonyDocument1 pageBeethoven 3 Elbeano Ventilator Trance Techno: SymphonyArtist RecordingNo ratings yet
- Rane Audio ReferenceDocument437 pagesRane Audio ReferenceArtist RecordingNo ratings yet
- Drum Tuning Advice For Recording and GigsDocument7 pagesDrum Tuning Advice For Recording and GigsArtist RecordingNo ratings yet
- Solar RadiationtransDocument51 pagesSolar RadiationtransmrizqynugrahaNo ratings yet
- Cambridge International A Level: Mathematics 9709/32 May/June 2021Document19 pagesCambridge International A Level: Mathematics 9709/32 May/June 2021HADFINA DAMIA BINTI SHAHIDINNo ratings yet
- 2 SimplePendulumDocument12 pages2 SimplePendulumSs SsrNo ratings yet
- Various Arts FormsDocument1 pageVarious Arts FormsWilsonNo ratings yet
- Borderline Personality Disorder PDFDocument240 pagesBorderline Personality Disorder PDFAngélica100% (1)
- SG ch02Document44 pagesSG ch02MsKhan0078No ratings yet
- 12.course OutlineDocument3 pages12.course OutlineMD. ANWAR UL HAQUENo ratings yet
- Dead Stars by Paz MarquezDocument8 pagesDead Stars by Paz MarquezNaneth DomenNo ratings yet
- ST Sir Gems, Subhadip Sir Pivots and Explanation of IDF by DR - VivekDocument101 pagesST Sir Gems, Subhadip Sir Pivots and Explanation of IDF by DR - VivekUsha JagtapNo ratings yet
- Coinage of IndiaDocument5 pagesCoinage of IndiaJared AllenNo ratings yet
- Analgin MANUALDocument7 pagesAnalgin MANUALstankodavoNo ratings yet
- TH STDocument27 pagesTH STDaniel NyagechiNo ratings yet
- Ikatan Kimia SaskialyaDocument9 pagesIkatan Kimia SaskialyaSaskia AlyaNo ratings yet
- 66 Powrful Copywriting StrategiesDocument9 pages66 Powrful Copywriting StrategiesRobert Sloane75% (4)
- ECE 486 Lead Compensator Design Using Bode Plots Fall 08: C S +Z S +PDocument4 pagesECE 486 Lead Compensator Design Using Bode Plots Fall 08: C S +Z S +PNaeem Ur RehmanNo ratings yet
- COT Watch MaterialDocument6 pagesCOT Watch MaterialRay PatriarcaNo ratings yet
- School of Law, Mumbai: Shreya Singhal V. Union of India: Case AnalysisDocument13 pagesSchool of Law, Mumbai: Shreya Singhal V. Union of India: Case Analysisgopika mundraNo ratings yet
- DIR-FLoortime Interested Providers 020311Document2 pagesDIR-FLoortime Interested Providers 020311circlestretchNo ratings yet
- Examiners' Report Principal Examiner Feedback October 2020Document12 pagesExaminers' Report Principal Examiner Feedback October 2020Fahad FarhanNo ratings yet
- Logistic MapDocument8 pagesLogistic MapSathya ArulNo ratings yet
- Flight Control System Architecture Optimization For Fly-By-Wire AirlinersDocument8 pagesFlight Control System Architecture Optimization For Fly-By-Wire AirlinersCharlton EddieNo ratings yet
- The Brain and Cranial Nerves: Lecture Slides Prepared by Curtis Defriez, Weber State UniversityDocument81 pagesThe Brain and Cranial Nerves: Lecture Slides Prepared by Curtis Defriez, Weber State UniversityKristine SanchezNo ratings yet
- Spark 3 INT Game 4Document1 pageSpark 3 INT Game 4Biljana NestorovskaNo ratings yet
- Pte Mag PDFDocument68 pagesPte Mag PDFhollowNo ratings yet
- Relational AlgebraDocument53 pagesRelational AlgebraJeyc RapperNo ratings yet
- DM MICA+Brochure+tools+20210330Document18 pagesDM MICA+Brochure+tools+20210330Shubham DeshmukhNo ratings yet
- Lesson 91Document4 pagesLesson 91Orked MerahNo ratings yet
- Florigen: MechanismDocument3 pagesFlorigen: MechanismDharmendra SinghNo ratings yet