Download as docx, pdf, or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Iso 4804Document120 pagesIso 4804Keroro Nelson100% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- JH2009004 Revised JH143 Circ PackDocument6 pagesJH2009004 Revised JH143 Circ PackCak Nyum-nyumNo ratings yet
- Ford Ranger Bronco II TFI Ignition Diagnostics PDFDocument10 pagesFord Ranger Bronco II TFI Ignition Diagnostics PDFMatthester100% (1)
- NetworkUPSTools UserManualDocument87 pagesNetworkUPSTools UserManualMariana MaherNo ratings yet
- IATF 16949 ClientsDocument126 pagesIATF 16949 ClientsKumaravel100% (1)
- Manual FludexDocument38 pagesManual FludexMauricio RebolledoNo ratings yet
- A100K11422 Flowire Configuration Manual PDFDocument27 pagesA100K11422 Flowire Configuration Manual PDFPano de PiaNo ratings yet
- Whitepaper Single Pair EthernetDocument13 pagesWhitepaper Single Pair EthernetLarry HughesNo ratings yet
- CCNA 4 v60 Chapters Exam AnswersDocument111 pagesCCNA 4 v60 Chapters Exam AnswersNevzat TarhanNo ratings yet
- Example 1Document13 pagesExample 1LeswNo ratings yet
- Checklist For Details of Switchyard Gate & Wicket GateDocument2 pagesChecklist For Details of Switchyard Gate & Wicket GateRupesh KhandekarNo ratings yet
- Automatic Night LampDocument3 pagesAutomatic Night LampIchwant BanaNo ratings yet
- VNX5300 Hardware Information GuideDocument92 pagesVNX5300 Hardware Information Guidesandeepsohi88No ratings yet
- Privacy Ai Governance Report SummaryDocument8 pagesPrivacy Ai Governance Report SummaryEKNo ratings yet
- Excerpts From Chap11 1 Luigi Logrippo U OttawaDocument33 pagesExcerpts From Chap11 1 Luigi Logrippo U OttawaKristian CzarNo ratings yet
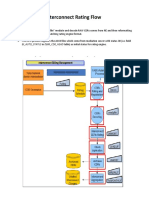
- Interconnect Rating FlowDocument5 pagesInterconnect Rating FlowShahzad AlviNo ratings yet
- A485 PDFDocument4 pagesA485 PDFProduction DepartmentNo ratings yet
- Supplier Assessment QuestionnaireDocument3 pagesSupplier Assessment QuestionnaireAdd KNo ratings yet
- BK130 1Document26 pagesBK130 1huychampiNo ratings yet
- Health and Safety PolicyDocument12 pagesHealth and Safety PolicyVarsha RaneNo ratings yet
- Is.10430.2000 Design of Lined CanalsDocument19 pagesIs.10430.2000 Design of Lined CanalstnvishNo ratings yet
- Letter Writing: Course Code: 1119 Subject: Communication Skills Course Instructor: Ms. Gull-e-HaniDocument21 pagesLetter Writing: Course Code: 1119 Subject: Communication Skills Course Instructor: Ms. Gull-e-HaniMEEN201101040 KFUEITNo ratings yet
- Crane Girder Design ProcedureDocument18 pagesCrane Girder Design ProcedureBhadresh Shah0% (1)
- eRAN15.1 Feature and Function Change SummaryDocument16 pageseRAN15.1 Feature and Function Change SummaryFaizal JamaludeenNo ratings yet
- Ogp 434-01Document42 pagesOgp 434-01Kishore ReddyNo ratings yet
- Sololift Plus BrochureDocument8 pagesSololift Plus BrochureSeyhun AgimNo ratings yet
- Quick Start Guide: Downloaded From Manuals Search EngineDocument2 pagesQuick Start Guide: Downloaded From Manuals Search EnginebuggersNo ratings yet
- Stihler Astotherm AP200-260 Blood Warmer - Service ManualDocument51 pagesStihler Astotherm AP200-260 Blood Warmer - Service ManualFábio Vitor MartinsNo ratings yet
- Compressor 800 Cfm-Atlas CopcoDocument3 pagesCompressor 800 Cfm-Atlas CopcoMahesh MirajkarNo ratings yet
- NZW14085 SC Bolts DataDocument7 pagesNZW14085 SC Bolts DataArnold TunduliNo ratings yet