Download as pdf or txt
You might also like
- Chapter 3 Metal Oxide Semiconductor (MOS)Document64 pagesChapter 3 Metal Oxide Semiconductor (MOS)Jay Chandra DharNo ratings yet
- Complex Programmable Logic DeviceDocument7 pagesComplex Programmable Logic DeviceShaik BasheeraNo ratings yet
- Mosfet Based ChopperDocument12 pagesMosfet Based Chopperarunkumar0% (1)
- Dual-Threshold Cad Framework For Subthreshold Leakage Power Aware FpgasDocument14 pagesDual-Threshold Cad Framework For Subthreshold Leakage Power Aware Fpgasrostamedastan65No ratings yet
- Term Paper Report MODIFIEDDocument21 pagesTerm Paper Report MODIFIEDUma SankarNo ratings yet
- GlitchLess Dynamic Power Minimization in FPGAs Through Edge Alignment and Glitch FilteringDocument14 pagesGlitchLess Dynamic Power Minimization in FPGAs Through Edge Alignment and Glitch Filteringmossaied2No ratings yet
- FpgaDocument32 pagesFpgaPavan TejaNo ratings yet
- RTL Design Techniques To Reduce The Power Consumption of FPGA Based CircuitsDocument6 pagesRTL Design Techniques To Reduce The Power Consumption of FPGA Based Circuitsraees74No ratings yet
- Dynamic Power Consumption in Virtex™-II FPGA Family: Li Shang Alireza S Kaviani Kusuma BathalaDocument8 pagesDynamic Power Consumption in Virtex™-II FPGA Family: Li Shang Alireza S Kaviani Kusuma BathalaVarun VyasNo ratings yet
- InterconnectsDocument6 pagesInterconnectsachuu1987No ratings yet
- Sub-Threshold Adiabatic Logic For Low Power ApplicationsDocument7 pagesSub-Threshold Adiabatic Logic For Low Power ApplicationsarcherselevatorsNo ratings yet
- Gpimentel 2006Document8 pagesGpimentel 2006kiranNo ratings yet
- A Novel FPGA-Based 2.5Gbps D-QPSK Modem For High Capacity Microwave RadiosDocument4 pagesA Novel FPGA-Based 2.5Gbps D-QPSK Modem For High Capacity Microwave Radiospayam79bNo ratings yet
- Genetic Synthesis Techniques For Low Power Digital Signal Processing Circuits PDFDocument5 pagesGenetic Synthesis Techniques For Low Power Digital Signal Processing Circuits PDFDeepa YagainNo ratings yet
- Expo Potencia en FpgaDocument27 pagesExpo Potencia en FpgaJaime Andres SalazarNo ratings yet
- FPGA Based Control Unit For Marx GeneratorsDocument57 pagesFPGA Based Control Unit For Marx GeneratorsAnshuman SahooNo ratings yet
- An Efficient Cordic Processor For Complex Digital Phase Locked LoopDocument7 pagesAn Efficient Cordic Processor For Complex Digital Phase Locked LoopInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Atul K Srivastava: 10.3 Field Programmable Gate ArraysDocument4 pagesAtul K Srivastava: 10.3 Field Programmable Gate ArraysTushar GuptaNo ratings yet
- Fpga Interview QuestionDocument35 pagesFpga Interview QuestionRAGUL RAJ S100% (1)
- CAD VLSI Unit 5 LMDocument4 pagesCAD VLSI Unit 5 LMRaviNo ratings yet
- A Low-Power FPGA Based On Autonomous Fine-Grain Power GatingDocument13 pagesA Low-Power FPGA Based On Autonomous Fine-Grain Power GatingVimala PriyaNo ratings yet
- Vlsi Design FlowDocument7 pagesVlsi Design FlowAster RevNo ratings yet
- FPGA Interview QuestionsDocument11 pagesFPGA Interview Questionssneha587No ratings yet
- Cascaded Multilevel InvertersDocument6 pagesCascaded Multilevel InvertersMinhaj NaimNo ratings yet
- FPGA Implementation of Digital Modulation Schemes Using Verilog HDLDocument10 pagesFPGA Implementation of Digital Modulation Schemes Using Verilog HDLIJRASETPublicationsNo ratings yet
- Implementation of Low Power Test Pattern Generator Using LFSRDocument6 pagesImplementation of Low Power Test Pattern Generator Using LFSRIjsrnet EditorialNo ratings yet
- Fpga Interview QuestionsDocument9 pagesFpga Interview QuestionsV SharmaNo ratings yet
- FPGA Design Flow: Page 1 of 5Document6 pagesFPGA Design Flow: Page 1 of 5PRAVEEN034No ratings yet
- A Design Approach For Fine-Grained Run-Time Power Gating Using Locally Extracted Sleep SignalsDocument7 pagesA Design Approach For Fine-Grained Run-Time Power Gating Using Locally Extracted Sleep Signalsthamy_15No ratings yet
- Design and Implementation of Traffic Controller Using VHDL: Interim Project ReportDocument21 pagesDesign and Implementation of Traffic Controller Using VHDL: Interim Project ReportAugusto Germano da SilvaNo ratings yet
- FPGA-based Design of An Evolutionary Controller For Collision-Free Robot NavigationDocument12 pagesFPGA-based Design of An Evolutionary Controller For Collision-Free Robot NavigationOussama BoulfousNo ratings yet
- Bhattacharjee 2011Document5 pagesBhattacharjee 2011harithNo ratings yet
- Atees 14Document7 pagesAtees 14Eng:ehab AlmkhlafiNo ratings yet
- Image Compression Using High Efficient Video Coding (HEVC) TechniqueDocument3 pagesImage Compression Using High Efficient Video Coding (HEVC) TechniqueAnonymous gQOifzNo ratings yet
- Low Power Techniques For VLSI DesignDocument6 pagesLow Power Techniques For VLSI DesignjainatinNo ratings yet
- Thesis Report On Low Power VlsiDocument7 pagesThesis Report On Low Power Vlsiashleylovatoalbuquerque100% (2)
- Trancated Multiplier PeprDocument5 pagesTrancated Multiplier PeprJagannath KbNo ratings yet
- SOC Implementation Wave-Pipelined: VenkataramaniDocument8 pagesSOC Implementation Wave-Pipelined: VenkataramaniRamesh PrasadNo ratings yet
- 097 Pid142349Document7 pages097 Pid142349jije townNo ratings yet
- Zhang2012 PDFDocument13 pagesZhang2012 PDFPhuc HoangNo ratings yet
- Fault Tolerance in FPGA Through Horse Shifting PDFDocument5 pagesFault Tolerance in FPGA Through Horse Shifting PDFNoah OkitoiNo ratings yet
- Digital Design and Implementation of An Overcurrent Relay On FPGADocument5 pagesDigital Design and Implementation of An Overcurrent Relay On FPGANandi ?No ratings yet
- FORTRAN Based ApproachDocument22 pagesFORTRAN Based ApproachGS EKTANo ratings yet
- Register-Transfer Level - WikipediaDocument6 pagesRegister-Transfer Level - WikipediasukhoiNo ratings yet
- Low Power Vlsi ThesisDocument5 pagesLow Power Vlsi Thesismariapadillaomaha100% (2)
- Wingz Technologies 9840004562: A Scalable and Modular Architecture For High-Performance Packet ClassificationDocument10 pagesWingz Technologies 9840004562: A Scalable and Modular Architecture For High-Performance Packet ClassificationReni JophyNo ratings yet
- 16 Dynamic FullDocument14 pages16 Dynamic FullTJPRC PublicationsNo ratings yet
- A Framework For The Design of High Speed Fir Filters On FpgasDocument4 pagesA Framework For The Design of High Speed Fir Filters On Fpgasamit1411narkhedeNo ratings yet
- 01 Project 01 PDFDocument2 pages01 Project 01 PDFmarcjoseph.hufanciaNo ratings yet
- Noc-Based Fpga: Architecture and RoutingDocument10 pagesNoc-Based Fpga: Architecture and RoutingAnonymous 1kEh0GvTgiNo ratings yet
- Tutorial On FPGA RoutingDocument11 pagesTutorial On FPGA RoutingAnshika SharmaNo ratings yet
- Pipeline Dae S With FeedbackDocument10 pagesPipeline Dae S With Feedbackyame asfiaNo ratings yet
- Thesis On Pipeline AdcsDocument6 pagesThesis On Pipeline Adcsamyholmesmanchester100% (2)
- High-Speed Low-Power Viterbi Decoder Design For TCM DecodersDocument13 pagesHigh-Speed Low-Power Viterbi Decoder Design For TCM DecodersPooja BanNo ratings yet
- Ijert Ijert: Implementation of Interleaving Switch Based Architecture For System On ChipDocument7 pagesIjert Ijert: Implementation of Interleaving Switch Based Architecture For System On ChipAkhila ReddyNo ratings yet
- Vlsi Design Unit 5 2019Document37 pagesVlsi Design Unit 5 2019Jpradha KamalNo ratings yet
- Low Power and Delay Efficient 32 - Bit Hybrid Carry Skip Adder Implementation Using HDLDocument4 pagesLow Power and Delay Efficient 32 - Bit Hybrid Carry Skip Adder Implementation Using HDLRahul SharmaNo ratings yet
- High-Performance D/A-Converters: Application to Digital TransceiversFrom EverandHigh-Performance D/A-Converters: Application to Digital TransceiversNo ratings yet
- Highly Integrated Gate Drivers for Si and GaN Power TransistorsFrom EverandHighly Integrated Gate Drivers for Si and GaN Power TransistorsNo ratings yet
- Gain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipFrom EverandGain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-ChipNo ratings yet
- WAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksFrom EverandWAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksNo ratings yet
- Design and Implementation of PhotovoltaicDocument8 pagesDesign and Implementation of Photovoltaicrostamedastan65No ratings yet
- 2007 Level ConverterDocument4 pages2007 Level Converterrostamedastan65No ratings yet
- What Is An Embedded System?: Special CharacteristicsDocument3 pagesWhat Is An Embedded System?: Special Characteristicsrostamedastan65No ratings yet
- Intro Digital Design-Digilent-VHDL OnlineDocument124 pagesIntro Digital Design-Digilent-VHDL OnlineGregorio Borges100% (1)
- Tanner Lab Manual (S-Edit and L-Edit)Document22 pagesTanner Lab Manual (S-Edit and L-Edit)sandeep_sggsNo ratings yet
- Dual-Threshold Cad Framework For Subthreshold Leakage Power Aware FpgasDocument14 pagesDual-Threshold Cad Framework For Subthreshold Leakage Power Aware Fpgasrostamedastan65No ratings yet
- Fundamentals Digital Logic and Microcomputer DesignDocument1 pageFundamentals Digital Logic and Microcomputer Designty3919883665No ratings yet
- TannerDocument40 pagesTannerkjnanduNo ratings yet
- Singel State TransistorDocument10 pagesSingel State Transistorkaran007_mNo ratings yet
- STR2A100 Series Application Note (Rev.0.3) : Sanken Electric Co., LTDDocument18 pagesSTR2A100 Series Application Note (Rev.0.3) : Sanken Electric Co., LTDBertrand Soppo YokiNo ratings yet
- 查询AD0804供应商 捷多邦,专业PCB打样工厂,24小时加急出货Document7 pages查询AD0804供应商 捷多邦,专业PCB打样工厂,24小时加急出货gamaNo ratings yet
- Ec6601 2m Rejinpaul IDocument21 pagesEc6601 2m Rejinpaul IAngelinNo ratings yet
- Ssc-Je-Electronic-Devices Electrical EngineeringDocument13 pagesSsc-Je-Electronic-Devices Electrical EngineeringPeerzada WahidNo ratings yet
- A Technical Seminar Report 19q91a0429 Ece ADocument32 pagesA Technical Seminar Report 19q91a0429 Ece ASushmaNo ratings yet
- Fet Characteristics: ObjectDocument5 pagesFet Characteristics: ObjectpankajmadhuNo ratings yet
- Physics Investigatory Class 12 Full Exclusive Project CbseDocument21 pagesPhysics Investigatory Class 12 Full Exclusive Project CbseAyu Harshal44% (16)
- Steps For IC Manufacturing - VLSI Tutorials - MepitsDocument6 pagesSteps For IC Manufacturing - VLSI Tutorials - MepitsAbhiNo ratings yet
- Vlsi TechnologyDocument8 pagesVlsi TechnologynitiniitrNo ratings yet
- Lab - Theory and Fabrication of Inter Grated CircuitsDocument169 pagesLab - Theory and Fabrication of Inter Grated Circuitsmagzoob_alnwbyNo ratings yet
- Application Note AN-1108: IRS2111 and IR2111 ComparisonDocument7 pagesApplication Note AN-1108: IRS2111 and IR2111 ComparisonadiNo ratings yet
- High Speed Layout AnalogDocument4 pagesHigh Speed Layout AnalogMahendra SakreNo ratings yet
- Comparison of Sic Mosfet and Si IgbtDocument10 pagesComparison of Sic Mosfet and Si IgbtYassir ButtNo ratings yet
- VLSIDocument22 pagesVLSIMoulana YasinNo ratings yet
- 2 Silicon: The Semiconductor MaterialDocument18 pages2 Silicon: The Semiconductor MaterialmohanNo ratings yet
- Origins of Weak Inversion or Sub-Threshold CircuitDocument4 pagesOrigins of Weak Inversion or Sub-Threshold CircuitNaveed AhmedNo ratings yet
- Week1 Assignment1 SolutionsDocument4 pagesWeek1 Assignment1 SolutionspvvNo ratings yet
- Improved Direct Back EMF Detection For Sensorless Brushless DC (BLDC) Motor DrivesDocument6 pagesImproved Direct Back EMF Detection For Sensorless Brushless DC (BLDC) Motor DrivesBùi TuyếnNo ratings yet
- Optical Detectors: Wei-Chih Wang Department of Power Mechanical Engineering National Tsing Hua UniversityDocument71 pagesOptical Detectors: Wei-Chih Wang Department of Power Mechanical Engineering National Tsing Hua UniversityDivya BajpaiNo ratings yet
- Sla7024m PDFDocument12 pagesSla7024m PDFEJASMANYNo ratings yet
- The Well: Circuit Design, Layout, and Simulation Third Edition R. Jacob BakerDocument43 pagesThe Well: Circuit Design, Layout, and Simulation Third Edition R. Jacob BakerMostafa MohamedNo ratings yet
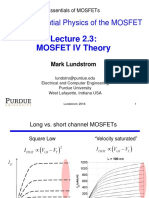
- ECEPurdue MOSFET Lundstrom L2.3v3bDocument22 pagesECEPurdue MOSFET Lundstrom L2.3v3balNo ratings yet
- Question Paper Code:: Reg. No.Document3 pagesQuestion Paper Code:: Reg. No.ajuklm88No ratings yet
- Investigation of Charge Plasma Based Nanowire Field Effect Transistor For Sub 5 NMDocument9 pagesInvestigation of Charge Plasma Based Nanowire Field Effect Transistor For Sub 5 NMNeethu SNo ratings yet
- 4953 IC DatasheetDocument10 pages4953 IC DatasheetAmit BhatiaNo ratings yet