Professional Documents
Culture Documents
Data Dictionary
Data Dictionary
Uploaded by
devammaOriginal Description:
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Data Dictionary
Data Dictionary
Uploaded by
devammaCopyright:
Available Formats
What is data Dictionary?
The ABAP Dictionary centrally describes and manages all the data definitions used in the system. The ABAP Dictionary is completely integrated in the ABAP Development Workbench. All the other components of the Workbench can actively access the definitions stored in the ABAP Dictionary. The ABAP Dictionary supports the definition of user-defined types (data elements, structures and table types). You can also define the structure of database objects (tables, indexes and views) in the ABAP Dictionary. These objects can then be automatically created in the database with this definition. The ABAP Dictionary also provides tools for editing screen fields, for example for assigning a field an input help (F4 help). Data dictionary is a central source of data in a data management system. Its main function is to support the .It has details about - What data is contained ? - What are the attributes of the data ? - What is the relationship existing between the various data elements ? Role: ABAP data dictionary supports definition of user-defined types (data elements, structures, table types). structure of database objects (tables, indexes and views) can also be defined. These user-defined types/objects are then automatically created in the underlying relational database using the above data definitions. The ABAP dictionary also provides tools for editing screen fields (e.g., for assigning a field an input help i.e. F4 help). Data dictionary ensures data integrity, consistency and security. What is the difference between open sql & native sql ? Open SQL Open SQL allows you to access all database tables known to the SAP system, regardless of the database manufacturer. Sometimes, however, we may want to use database-specific SQL statements called Native SQL in the ABAP/4 program. A database interface translates SAP\'s Open SQL statements into SQL commands specific to the database in use. Native SQL statements access the database directly. To avoid incompatibilities between different database tables and also to make ABAP/4 programs independent of the database system in use, SAP has created a set of separate SQL statements called Open SQL. Open SQL contains a subset of standard SQL statements as well as some enhancements which are specific to SAP. Open SQL contains the following keywords: SELECT - Reads data from database tables. INSERT - Adds lines to database tables. UPDATE - Changes the contents of lines of database tables. MODIFY - Inserts lines into database tables or changes the contents of existing lines. DELETE - Delete lines from database tables. OPEN CURSOR, FETCH, CLOSE CURSOR - Reads lines of database tables using the cursor. All Open SQL statements fill the following two system fields with return codes: SY-SUBRC After every Open SQL statement, the system field SY-SUBRC contains 0 if the operation was successful, a value other than 0 if not. SY-DBCNT After an OPEN SQL statement, the system field SY-DBCNT contains the number of database lines processed. Native SQL Native SQL allows you to use database-specific SQL statements in an ABAP program. This means that you can use database tables that are not administered by the ABAP Dictionary, and therefore integrate data that is not part of the R/3 System. ABAP Native SQL allows you to include database-specific SQL statements in an ABAP program. Most ABAP programs containing database-specific SQL statements do not run with different databases. If different databases are involved, use Open SQL. To execute ABAP Native SQL in an ABAP program, use the statement EXEC. Open SQL (Subset of standard SQL statements), allows you to access all database tables available in the R/3 System, regardless of the manufacturer. To avoid conflicts between database tables and to keep ABAP programs independent from the database system used, SAP has generated its own set of SQL statements known as Open SQL. If you create a table by using database tools, without ABAP Dictionary, you are not able to use Open SQL to reach this table. You just can use Native SQL to do that. Native SQL statements bypass the R/3 database interface. There is no table logging, and no synchronization with the database buffer on the application server. For this reason, you should, wherever possible, use Open SQL to change database tables declared in the ABAP Dictionary. In particular, tables declared in the ABAP Dictionary that contain log columns with types LCHR and LRAW should only be addressed using Open SQL, since the columns contain extra, database-specific length information for the column. Native SQL does not take this information into account,
and may therefore produce incorrect results. Furthermore, Native SQL does not support automatic client handling. Instead, you must treat client fields like any other. To ensure that transactions in the R/3 System are consistent, you should not use any transaction control statements (COMMIT, ROLLBACK WORK), or any statements that set transaction parameters (isolation level) using Native SQL. Using Native SQL, you can Transfer values from ABAP fields to the database Read data from the database and process it in ABAP programs. Native SQL works without the administrative data about database tables stored in the ABAP Dictionary. Consequently, it cannot perform all of the consistency check used in Open SQL. This places a larger degree responsibility on application developers to work with ABAP fields of the correct type. You should always ensure that the ABAP data type and the type of database column are identical. Native SQL Advantages and Disadvantages - EXEC SQL statement Advantages Tables are not declared in ABAP Dictionary can be accessed. (e.g. Tables belonging to sys or system user of Oracle, etc.) To use some of the special features supported by the database-specific SQL. (e.g. Passing hints to Oracle optimizer.) Disadvantages No syntax check is performed whatever is written between EXEC and ENDEXEC. ABAP program containing database-specific SQL statements will not run under different database systems. There is no automatic clien handling for client dependent tables. Care has to be taken during migration to higher versions. Difference between Pooled, cluster & transparent tables? Transparent: A transparent table has 1-to-1 cardinality between the table definition in the data dictionary and in the table definition of sap database whereas cluster/pool tables have many-to-1 cardinality between the table definition in the data dictionary and in the table definition of sap database. Transparent tables are accessible both by Open and native SQL statements whereas table pool/cluster tables are accessible only by open SQL but never by native SQL. Transparent tables can store table relevant data whereas table pool or cluster tables can store only system data/ application data based on the transparent tables The tables physically present in the DB Server as in the Application Server. Pooled Tables: A pooled table in R/3 has a many-to-one relationship with a table in the database. For one table in the database, there are many tables in the R/3 Data Dictionary. The table in the database has a different name than the tables in the DDIC, it has a different number of fields, and the fields have different names as well. Pooled tables are an SAP proprietary construct. When you look at a pooled table in R/3, you see a description of a table. However, in the database, it is stored along with other pooled tables in a single table called a table pool. A table pool is a database table with a special structure that enables the data of many R/3 tables to be stored within it. It can only hold pooled tables. R/3 uses table pools to hold a large number (tens to thousands) of very small tables (about 10 to 100 rows each). Table pools reduce the amount of database resources needed when many small tables have to be open at the same time. SAP uses them for system data. You might create a table pool if you need to create hundreds of small tables that each hold only a few rows of data. To implement these small tables as pooled tables, you first create the definition of a table pool in R/3 to hold them all. When activated, an associated single table (the table pool) will be created in the database. You can then define pooled tables within R/3 and assign them all to your table pool. Pooled tables are primarily used by SAP to hold customizing data. Table Pools The data is stored as a table pool in the database server which consists of all the (physical) records from the tables present in that particular table pool. Technically, The table name and the field name are the key fields in case of pooled tables. Cluster Tables: A cluster table is similar to a pooled table. It has a many-to-one relationship with a table in the database. Many cluster tables are stored in a single table in the database called a table cluster. A table cluster is similar to a table pool. It holds many tables within it. The tables it holds are all cluster tables. Like pooled tables, cluster tables are another proprietary SAP construct. They are used to hold data from a few (approximately 2 to 10) very large tables. They would be used when these tables have a part of their primary keys in common, and if the data in these tables are all accessed simultaneously. Table clusters contain fewer tables than table pools and, unlike table pools, the primary key of each table within the table cluster begins with the same field or fields. Rows from the cluster tables are combined into a single row in the table cluster. The rows are combined based on the part of the primary key they have in common. Thus, when a row is
read from any one of the tables in the cluster, all related rows in all cluster tables are also retrieved, but only a single I/O is needed. A cluster is advantageous in the case where data is accessed from multiple tables simultaneously and those tables have at least one of their primary key fields in common. Cluster tables reduce the number of database reads and thereby improve performance. Table Clusters Logical data records from different tables are stored as single PHYSICAL record in the table clusters. Technically. There can be n number keys (usually generated by the system ) for a record in a cluster table and field called pageno is used to track the continuation of the records. BOTH TABLE POOLS AND TABLE CLUSTERS ARE NOT PHYSICALLY AVAILABLE IN THE DB SERVER BUT THEY ARE LOGICALLY POOLED OR CLUSTERED. Restrictions on Pooled and Cluster Tables Pooled and cluster tables are usually used only by SAP and not used by customers, probably because of the proprietary format of these tables within the database and because of technical restrictions placed upon their use within ABAP/4 programs. On a pooled or cluster table: - Secondary indexes cannot be created. - You cannot use the ABAP/4 constructs select distinct or group by. - You cannot use native SQL. - You cannot specify field names after the order by clause. order by primary key is the only permitted variation. Transparent tables Non transparent ( Cluster& Pooled)
1 - 1 cardinality between Data Dictionary and Database
Many - 1 cardinality
Transparent table can access with using Open & Native SQL statements
Non transparent can access only Open Sql.
Transparent tables can store Table relevant data
Non transparent tables can store system data/ application data based on the transparent tables
secondary indexes allowed
No secondary indexes
Can be buffered
(Should be accessed via primary key) Cluster Tables: Can not be buffered Pool Tables Should be buffered
What is Primary key, foreign key ? what is primary index? Primary key field is the the database table column which helps in identifying the records uniquely in master table. Foreign key field is the database table column of a details table which is dependent on the primary key field of a parent table . e.g - In Employee Master Data table (Dept_ID is the foreign key) Emp_ID Emp_name Dept_ID 1 2 3 4 5 6 7 8 aaa bbb ccc ddd eee fff ggg hhh 10 20 30 40 20 10 30 50
9 iii 10 10 jjj 30 In Employee Details Data table (Dept_ID is the Primary key) Dept_ID Dept_Name 10 Accounts 20 Sales 30 Purchase 40 Inventory 50 Administration Uses of foreign keys in SAP Using foreign keys (as main table-field is linked with check table), input value check for any input field can be done. Foreign keys can also be used to link several tables. Explanation on foreign keys: Relationships between tables are defined in the ABAP dictionary by creating foreign keys. Suppose, tab1(Foreign key table or dependent table) contains the following fields: fld1(primary key), fld2, fld3, fld4, fld5 and Tab2(Referenced table) contains the following fields: fld6(primary key), fld7(primary key), fld8, fld9 and tab1fld2 is connected to tab2-fld5, tab1-fld4 is connected to tab2-fld6Therefore, fld2 and fld4 fields of the table tab1 are called as foreign key fields to the table tab2 and tab2 is called as check table or referenced table. Foreign key fields One field of the foreign key table corresponds to each key field of the check table. That field of the is called as foreign key field. Uses: A foreign key permits assigning data records in the foreign key table and check table. One record of the foreign key table uniquely identifies a record of the check table (using the value entries in the foreign key fields of the foreign key table). Primary index: the primary index contains key fields of a table and a pointer to non-key fields of the table. The primary index is created automatically when a table is created in database and moreover you can further define reference to the primary index which are known as Secondary index. What secondary index? You can search a table for data records that satisfy certain search criteria faster using an index. An index can be considered a copy of a database table that has been reduced to certain fields. This copy is always in sorted form. Sorting provides faster access to the data records of the table, for example using a binary search. The index also contains a pointer to the corresponding record of the actual table so that the fields not contained in the index can also be read. The primary index is distinguished from the secondary indexes of a table. The primary index contains the key fields of the table and a pointer to the non-key fields of the table. The primary index is created automatically when the table is created in the database. Table SCOUNTER in the link contains the assignment of the carrier counters to airports. The primary index on this table therefore consists of the key fields of the table and a pointer to the original data records.
You can also create further indexes on a table in the ABAP Dictionary. These are called secondary indexes. This is necessary if the table is frequently accessed in a way that does not take advantage of the sorting of the primary index for the access. Different indexes on the same table are distinguished with a three-place All the counters of carriers at a certain airport are often searched for flight bookings. The airport ID is used to search for counters for such an access. Sorting the primary index is of no use in speeding up this access. Since table SCOUNTER has a large number of entries, a secondary index on the field AIRPORT (ID of the airport) must be created to support access using the airport ID.
The optimizer of the database system decides whether an index should be used for a concrete table access . This means that an index might only result in a gain in performance for certain database systems. You can therefore define the database systems on which an index should be created when you define the index in the ABAP Dictionary .All the indexes existing in the ABAP Dictionary for a table are normally created in the database when the table is created if this was not excluded in the index definition for this database system. If the index fields have key function, that is if they already uniquely identify each record of the table, an index can be defined as a unique index.
What to Keep in Mind for Secondary Indexes
How well an existing index supports data selection from a table largely depends on whether the data selected with the index represents the data that will ultimately be selected. This can best be shown using an example. An index is defined on fields FIELD1, FIELD2, FIELD3 and FIELD4 of table BSPTAB in this order. This table is accessed with the SELECT statement: SELECT * FROM BSPTAB WHERE FIELD1 = X1 AND FIELD2 = X2 AND FIELD4= X4. Since FIELD3 is not specified more exactly, only the index sorting up to FIELD2 is of any use. If the database system accesses the data using this index, it will quickly find all the records for which FIELD1 = X1 and FIELD2 = X2. You then have to select all the records for which FIELD4 = X4 from this set. The order of the fields in the index is very important for the accessing speed. The first fields should be those which have constant values for a large number of selections. During selection, an index is only of use up to the first unspecified field. Only those fields that significantly restrict the set of results in a selection make sense for an index. The following selection is frequently made on address file ADRTAB: SELECT * FROM ADRTAB WHERE TITEL = Prof. AND NAME = X AND VORNAME = Y. The field TITLE would rarely restrict the records specified with NAME and FIRSTNAME in an index on NAME, FIRSTNAME and TITLE, since there are probably not many people with the same name and different titles. This would not make much sense in this index. An index on field TITLE alone would make sense for example if all professors are frequently selected. Additional indexes can also place a load on the system since they must be adjusted each time the table contents change. Each additional index therefore slows down the insertion of records in the table. For this reason, tables in which entries are very frequently written generally should only have a few indexes. The database system sometimes does not use a suitable index for a selection, even if there is one. The index used depends on the optimizer used for the database system. You should therefore check if the index you created is also used for the link.Creating an additional index could also have side effects on the performance. This is because an
index that was used successfully for selection might not be used any longer by the optimizer if the optimizer estimates (sometimes incorrectly) that the newly created index is more selective. The indexes on a table should therefore be as disjunct as possible, that is they should contain as few fields in common as possible. If two indexes on a table have a large number of common fields, this could make it more difficult for the optimizer to choose the most selective index.
what are the components of a table? Table fields: For table fields, field names and data types are defined. Foreign keys: Relationship between the table and the other tables are defined. Technical settings: Data class and size category defines that what type of table to be created and how much space required. Indexes: Secondary indexes are created for a table for faster data selection. Again following are defined for a table fields: Field name can be of maximum 16 characters in a table and must start with a letter. Key flag determines if a field should be the table key. Field type depicts the data type of the field in the ABAP dictionary. Field length denotes the number of valid places in the field. Decimal places Number of places after decimal point for float type value. Short text describes the business meaning of the field. what is a domain? A domain describes the technical characteristics of a table field .it specifies a value range, which describes allowed data values for the fields that refer to this domain. The value range for a domain is defined by specifying a data type and length. For example, specifying the data format NUMC and the field length 8 define the number a person belonging to the university. The ABAP/4 dictionary provides two ways of further restricting the value range for a domain with in a data type. By specifying fixed values. For example, the value range for the months in the year can be specified by listing all possible values (JanuaryDecember) By stipulating a value table. Only values contained in the relevant field of the value table may be entered in fields referring to this domain, a check is not made in the input mask for a field referring to this domain unless a corresponding foreign key has been defined for this field. Both fixed values and a value table can be specified for a domain. As a result, fields referring to this domain can accept only those values that exist in both the value table and in the fixed values. what is a data element? what is data class? If you choose the data class correctly, your table is automatically assigned to the correct area (tablespace or DBspace) of the database when it is created. Each data class corresponds to a physical area in which all the tables assigned to this data class are stored There are the following data classes: _ APPL0 (master data): Data which is seldomly changed. An example of master data is the data contained in an address file, such as the name, address and telephone number. _ APPL1 (transaction data): Data that is frequently changed. An example of transaction data is the goods in a warehouse, which change after each purchase order. _ APPL2 (organizational data): Customizing data that is defined when the system is installed and seldomly changed. An example is the table with country codes. Two further data classes, USR and USR1, are provided for the customer. These are for user developments. The tables assigned to these data classes are stored in a tablespace for user developments. What is table maintenance generator and how to create that? What is the transaction code? Ans: Table maintanence generator is nothing but making a table available for adding records and deleting records. The transaction code used is SM30. Table Maintenance Generator is a tool used to customize the tables created by end users and can be changed as required, such as making an entry to that table, deleting an entry etc. In other words, table maintenance generator is a user interface tool which is used to change the entry of the table or delete an entry from the table or create an entry for the table. Prerequisite To make this feature work care should be taken while creating the database table that in the 'Delivery & Maintenance' tab, the 'Table View Maint.' should have the "Maintenance allowed" property defined.
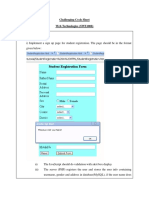
Transaction Codes SE54: Generate Table Maintenance Dialog SE55: Table view maintenance DDIC call SE56: Table view display DDIC call SE57: Deletion of Table Maintenance SM30: Maintenance Table Views: Implementation of table maintenance generator for a custom table Go to SE11 and create a table with the fields as per the requirement. In table change mode, click on Utilities and then click on Table maintenance generator.
Following screen will be displayed for setting up the Maintenance generator
Following are the available options, choose them accordingly Authorization Group : If the table needs to be maintained by only particular group of people, then the Authorization group needs to be filled otherwise fill it as &NC&. To maintain the authorization group refer to SU21. Function group is the name to which the generated maintenance modules will belong to. Generally Function Group name can be same as table name. Maintenance screens: Maintenance can be done in 2 ways 1. Maintenance & Overview both on one screen 2. Maintenance on one screen and Overview on another screen. Provide the desired screen numbers. Table Maintenance Events The value to be displayed on the maintenance screen for any field can also be altered as per the requirement like for every new entry in the table one of the field should have the constant value appearing automatically. For this purpose, the event needs to be chosen which performs the action. In this case event "05 creating a new entry". List of Events available in Table maintenance 01 Before saving the data in the database 02 After saving the data in the database 03 Before deleting the data displayed 04 After deleting the data displayed 05 Creating a new entry 06 After completely performing the function 'Get original' 07 Before correcting the contents of a selected field 08 After correcting the contents of a selected field 09 After getting the original of an entry 10 After creating the header entries for the change task (E071) 11 After changing a key entry for the change task (E071K) 12 After changing the key entries for the change task (E071K) 13 Exit editing (exit main function module) 14 After lock/unlock in the main function module 15 Before retrieving deleted entries 16 After retrieving deleted entries 17 Do not use. Before print: Event 26 18 After checking whether the data has changed
19 After initializing global variables, field symbols, etc. 20 after input in date sub screen (time-dep. tab. /views) 21 Fill hidden fields 22 Go to long text maintenance for other languages 23 Before calling address maintenance screen 24 After restricting an entry (time-dep. tab./views) 25 Individual authorization checks 26 Before creating a list 27 After creation or copying a GUID (not a key field) 28 After entering a date restriction for time-dep. views AA Instead of the standard data read routine AB Instead of the standard database change routine AC Instead of the standard 'Get original' routine AD Instead of the standard RO field read routine AE Instead of standard positioning coding AF Instead of reading texts in other languages AG Instead of 'Get original' for texts in other languages AH Instead of DB change for texts in other languages ST GUI menu main program name AI Internal use only For selecting the events follow the path as Environment -> Modification -> Events
what is table maintenance generator?What is the use of it? As all of you know, we can create database tables in SAP using transaction code SE11. A table can be manipulated by a program or manually. When creating table, you will find a check box 'Table maintenance allowed'. If we check that option, we can manually enter entries using SE16 or table maintenance generator screen. SE16 is for data browser. How to create table maintenance generator? Go to SE11, give the table name and click on change. Then Go to utilities--> Table maintenance generator. In the table maintenance generator screen, we should give Authorization Group, Function Group name (Function Group name can be same as table name), Maintenance type can be one step or two step, usually we will create with one step. we should give maintenance screen number. After clicking on create button, a table maintenance generator will be created. To check it go to SM30 . In SM30, we find display, Maintain options. We can view the table contents by choosing Display and we can create table entries by choosing Maintain. Why we have to go for Table maintenance generator, when we can edit the table by SE16 or SE11, utilities->create entries? Answer. In the production system, end-users will not be having access to transaction codes like SE11 and SE16. Developers will not be having access to many transaction codes including the above two. To view the contents of the database table, we will use SE16n in Production system. Please find out the difference between SE16 and SE16n. All these authorizations will be maintained by BASIS team, by creating access profiles.
So in order to edit or create the contents of a database table, we should go for table maintenance generator. In real time, authorizations will be maintained in production system. (even in development and Test systems to some extent). There is an audit like Sarbanes-Oxley Act for American clients, where every thing will be audited by government agency. To know more about SOX, use the links on the right hand side of this page. The second reason is, we can edit or create multiple entries at a time, using table maintenance generator. Apart from that we have options like 'Enter conditions' in table maintenance screen SM30. Please try to find out the use of those, by creating an example. Table Maintenance generator: Difference between one step and two steps. While creating table maintenance generator, we find below options: 1. When we choose one step, we have to give the screen number in Overview Screen field. 2. When we choose two step, we have to give both overview screen number and single screen number. You can give any number for screen. Dont give 1000 screen number. As this number is reserved for selection screen. When we choose two step, two screens will be created for table maintenance. For single step only one screen will be created. When we choose two step, table maintenance will work as follows Go to SM30, give the table name for which you have created table maintenanceOverview screen will be displayed. To create entries, when you click on new entries. Another screen will be displayed, where you give input and save. You can enter one record at a time. When we choose single step, table maintenance will work as follows: Go to SM30; give table name for which you have created table maintenanceOverview screen will be displayed; To create entries click on new entries, you can enter the records on the same screen. You can enter multiple records at a time. We use single step generally, as it is user friendly. To completely understand the difference and above points please do exercise by creating table maintenance generator in both ways (using single step and two step). How to add new fields to a standard sap table? 1. Appended structures 2. Customizing tables What are lock objects? Lock objects are nothing but which holds a data for particular field value until you remove a lock. Lock objects are use in SAP to avoid the inconsistency at the time of data is being insert/change into database. SAP Provide three types of Lock objects. Read Lock (Shared Locked) Protects read access to an object. The read lock allows other transactions read access but not write access to the locked area of the table Write Lock (exclusive lock) Protects write access to an object. The write lock allows other transactions neither read nor write access to the locked area of the table. Enhanced write lock (exclusive lock without cumulating) Works like a write lock except that the enhanced write lock also protects from further accesses from the same transaction. You can create a lock on a object of SAP through transaction SE11 and enter any meaningful name start with EZ Use: you can see in almost all transaction when you are open an object in Change mode SAP could not allow to any other user to open the same object in change mode. Example: in HR when we are enter a personal number in master data maintenance screen SAP can't allow to any other user to use same personal number for changes.
Example for Lock Objects When booking flights it is important to prevent flights from being overbooked. For this reason, you have to lock the particular flight as well as all the bookings existing for this flight during processing. You can do this with lock object E_BOOKING. The flights are recorded in table SFLIGHT and the bookings for the flights in table SBOOK. The two tables are linked with a foreign key. Lock object E_BOOKING must therefore contain table SFLIGHT as primary table and table SBOOK as further table.
The lock argument of table SFLIGHT thus contains the fields MANDT, CARRID, CONNID, and FLDATE. The lock argument of table SBOOK thus contains the fields MANDT, CARRID, CONNID, FLDATE, BOOKID and CUSTOMID. Select exclusive lock mode, that is the locked data can only be displayed and edited by one user. When the lock object is activated, the following function modules are generated from its definition: ENQUEUE_ E_BOOKING (set locks) ENQUEUE_ E_BOOKING (release locks) These function modules can now be linked to ABAP programs. The following example shows how function module ENQUEUE_ E_BOOKING is called.
With this call, flight LH 400 on Nov. 29,1998 is exclusively (lock mode E) locked in table SFLIGHT together with all the bookings entered in table SBOOK for this flight (since the initial value 0 is transferred for BOOKID and
CUSTOMID). The lock is sent to the update program (_SCOPE = 2). If there is a lock conflict, another attempt is made to set the lock after a certain time (_WAIT = X). The set locks can be removed by calling the function module DEQUEUE_E_BOOKING as follows:
The existing exclusive lock entries for flight LH 400 are deleted in table SFLIGHT and the bookings for this flight are deleted in table SBOOK. The request to delete the lock entries is passed on to the update program (_SCOPE = 3). Diff between inner & outer join? can you create a table without a data element? yes we can create at the time of creating a table after finishing field press built-in-type directly u can assign data type , length and description for each field .like that we can create field with out domain and data element . we never create a filed like that because table to table relationship is not possible can you create a field without a data element? ITAB LIKE SPFLI. here we are referencing to a data object(SPFLI) not data element. Yes.We can create a table without referring to data elements. But Data elements describe the technical attributes of the SAP field like data type, short text, field label, Parameter ID, Search help etc. Everything will get assigned automatically when we refer the data element to SAP field. What approach you prefer for creating a table? Give few names of cluster tables in sap? Example of table cluster and cluster tables. The table cluster RFBLG holds data for five transparent tables i.e. BSEC, BSED, BSEG, BSES and BSET. Other examples of table clusters are CDCLS, CDHDR, RFBLG, DOKCLU, DOKTL . Give few names of pooled tables in sap? give few names of transparent tables? VBAK, VBAP, KNA1 etc. What are User Defined Data Types? data elements, structures and table types What are the Database Objects? tables, indexes and views What are the most important Objects in ABAP Dictionary? The most important object types in the ABAP Dictionary are tables, views, types (data elements, structures, table types), domains, search helps and lock objects. What is the purpose/use of ABAP Dictionary? Data definitions (metadata) are created and managed in the ABAP Dictionary. The ABAP Dictionary permits a central description of all the data used in the system without redundancies. New or modified information is automatically provided for all the system components. This ensures data integrity, data consistency and data security. You can create the corresponding objects (tables or views) in the underlying relational database using these data definitions. The ABAP Dictionary therefore describes the logical structure of the objects used in application development and shows how they are mapped to the underlying relational database in tables or views.
The ABAP Dictionary also provides standard functions for editing fields on the screen, for example for assigning a screen field an input help. What are Tables? Tables can be defined independently of the database in the ABAP Dictionary. The fields of the table are defined with their (database-independent) data types and lengths. When the table is activated, a physical table definition is created in the database for the table definition stored in the ABAP Dictionary. The table definition is translated from the ABAP Dictionary to a definition of the particular database. What are the Components of Tables in ABAP Dictionary? Table fields: define the field names and data types of the fields contained in the Table Foreign keys: define the relationships between the table and other tables Technical settings: control how the table should be created in the database Indexes: To speed up data selection, secondary indexes can be created for the table Can we include the fields of a structure into the Table? If so How? Yes, Structure A was included in table B. A new field is inserted in structure A. When structure A is activated, table B is adjusted to this change, that is the new field is also inserted there. Includes can also be nested, that is structure A includes structure B which in turn includes another structure C, etc. The maximum nesting depth is limited to nine. The maximum length of a path of nested includes in a table or structure is therefore nine (the table/structure itself not included). Can all types of Structures be included in an Include? Only flat structures can be included What are the different methods of assigning DATA TYPE? In Table Definition-Directly You directly assign the field a data type, field length (and if necessary decimal places) and short text in the table definition. From the Domain of Data Element You can assign the field a data element .The data type, field length (and decimal places) are determined from the domain of the data element. The short description of the data element is assigned to the field as a short text. What are the other Assignment options in TABLE? Other Assignment Options: Check table: An input check for the field can be defined with a foreign key. This input check appears on all the screens in which the field is used. Search help assignment: A search help can be assigned to a field. This search help defines the input help flow on all the screens in which the field is used. Reference field and reference table: You must specify the table field in which the corresponding unit of measure or currency can be found for fields containing quantities (data type QUAN) or currency amounts (data type CURR). What are Reference Fields and Reference Tables? You must specify a reference table for fields containing quantities (data type QUAN) or currency Amounts (data type CURR). This reference table must contain a field with the format for the currency key (data type CUKY) or unit of measure (data type UNIT). This field is called the reference field of the output field. The reference field can also reside in the table itself. A field is only assigned to the reference field at program runtime. For example, if a field is filled with currency amounts, the corresponding currency is determined from the assigned reference field, that is the value entered in this field at the moment defines the currency. What are Includes? include the fields of another structure in tables and structures.
When an include is changed, all the tables and structures that include it are automatically adjusted. Can we include Group name in Includes? Yes, You can assign the include a group name [Page 148] with which the group of fields in the include can be addressed as a whole in ABAP programs. What are Nested Includes? Includes can also be nested, that is structure A includes structure B which in turn includes another structure C, etc. The maximum nesting depth is limited to nine. The maximum length of a path of nested includes in a table or structure is therefore nine (the table/structure itself not included). Only flat structures [Page 144] can be included. In a flat structure, every field either refers to a data element or is directly assigned a data type, length and possibly decimal places. Only structures may be included in a table. Tables, structures and views may be included in a structure. How to Insert Includes? Place the cursor under the line in which you want to insert the include Edit _ Include _ Insert. A dialog box appears. Enter the structure name/Group name Choose . A line with .INCLUDE in the Fields field and the name of the include in the Field type field is inserted in the field maintenance screen for the table. Select column Key if all the fields in the include should be key fields of the table. The table key must be at the start of the field list. If you select column Key, you must insert the include after the last key field or between the existing key fields of the table. If you do not select column Key, none of the included fields is a key field of the table. 5. Choose Where to find find information about the activation flow in the activation log, Utilities _ Activation log. Can we copy the Fields in the Includes? You can copy the fields contained in the include directly to the table with Edit _ Include _ Copy components. The fields of the include become table fields. They are no longer adjusted to changes in the include. 21.What is Foreign Key? define the relationships between tables in the ABAP Dictionary Using foreign keys, you can easily create value checks for input fields. A foreign key permits you to assign data records in the foreign key table and check table. One record of the foreign key table uniquely identifies one record of the check table using the entries in the foreign key fields.
Field Assignment in the Foreign Key A foreign key links two tables T1 and T2 by assigning fields of table T1 to the primary key fields of table T2.
What are Check Field and Value Check? check field. One of the foreign key fields is marked as the check field. This means that the foreign key relationship is maintained for this field. When an entry is made in the check field, there is a check whether the check table contains a record with the key defined by the values in the foreign key fields. If this is so, the entry is valid. Otherwise the system rejects the entry.
How to exclude the Check Field? you can exclude fields of the foreign key table from the assignment of the fields to the check table with generic and constant foreign keys .
What are Generic and Constant Foreign Keys? SELECT * FROM PTAB WHERE PTAB-FIELD1 = FTAB-FIELD6 AND PTAB-FIELD3 = FTABFIELD8 AND PTAB-FIELD4 = K.
The values entered on the screen for Field7 and Field9 are meaningless when checking against the check table. An entry with Field6 = 1, Field8 = 3 and Field9 = B would not be valid in this case since there is no record with PTAB-Field1 = 1, PTAB-Field3 = 3 and PTAB-Field4 = K in the check table! Semantic attributes of Foreign Keys A foreign key describes a relationship between two tables. You can define this relationship more precisely by specifying the cardinality and type of foreign key fields . This information is optional and is primarily for documentary purposes. In particular, the definitions of the cardinality and type of the foreign key fields are not used in the value check for the foreign key. The definition of the semantic attributes is only used in the following cases: If Key fields of a text table is selected as the type of the foreign key fields, the foreign key table is considered to be the text table [Page 27] for the check table.
Tables can only be included in a help view [Page 115] or maintenance view [Page 117] if they are linked with a foreign key. What is Cardinality? The cardinality (n:m) describes the foreign key relationship with regard to the number of possible dependent records (records of the foreign key table) or referenced records (records of the check table). The left side (n) of the cardinality is defined as follows: _ n=1: There is exactly one record assigned to the check table for each record of the foreign key table. _ n=C: The foreign key table may contain records which do not correspond to any record of the check table because the foreign key field is empty. This can occur for example if the field of the foreign key table is optional, in which case it does not have to be filled. The right side (m) of the cardinality is defined as follows: _ m=1: There is exactly one dependent record for each record of the check table. _ m=C: There is at most one dependent record for each record of the check table. _ m=N: There is at least one dependent record for each record of the check table. _ m=CN: There may be any number of dependent records for each record of the check table. What is a Text Table? Table A is a text table of table B if the key of A comprises the key of B and an additional language key field (field of data type LANG). Table A may therefore contain explanatory text in several languages for each key entry of B. To link the key entries with the text, text table A must be linked with table B using a foreign key. Key fields of a text table must be selected here for the type of foreign key fields Multi-Structured Foreign Keys When you define a foreign key, a field of the work area that is not contained in the foreign key table can also be assigned to a check table (for example a field of another table). This is possible for all fields except for the check field. Table.
If a field that is not contained in the foreign key table is assigned to a field of the check table, this field must be filled at the time of the input check. Otherwise the check always fails, and no values can be entered in the check field. Explain the Technical Settings in ABAP Data Dictionary. The technical settings of a table define how the table will be handled when it is created in the database, that is whether the table will be buffered and whether changes to data records of the table will be logged. What are the most important Parameters of Technical Settings? The most important parameters are: Data class: The data class defines the physical area of the database (tablespace) in which the table should be created.
Size category: The size category defines the size of the extents created for the table. When the table is created in the database, the required information about the memory area to be selected and the extent size is determined from the technical settings. Buffering permission: The buffering permission defines whether the table may be buffered. Buffering type: If the table may be buffered, you must define a buffering type (full, singlerecord, generic). The buffering type defines how many table records are loaded into the buffer when a table entry is accessed. Logging: This parameter defines whether changes to the table entries should be logged. If logging is switched on, each change to a table record is recorded in a log table. The Convert to transparent table flag (transparent flag [Page 42]) is also displayed for pooled tables or for tables which were converted into transparent tables earlier on with this flag. What is Size Category? The size category defines the expected space required for the table in the database. You can choose a size category from 0 to 4 for your table. Each category is assigned a certain fixed memory size in the database, which depends on the database system used. When a table is created, initial space (an Initial Extent) is reserved in the database. If more space is required at a later time due to data entries, additional memory will be added depending on the selected size category.
Selecting the correct size category prevents a large number of very small extents from being created for a table. It also prevents space from being wasted if extents which are too large are created. What is Buffering?What are the types of Buffering permission? You must define whether and how a table is buffered in the technical settings for the table. There are three possibilities here: Buffering not permitted: Table buffering is not permitted, for example because application programs always need the most recent data from the table or the table is changed too frequently. Buffering permitted but not activated: Buffering is permitted from the business and technical points of view. Applications which access the table execute correctly with and without table buffering. Whether or not table buffering will result in a gain in performance depends on the table size and access profile of the table (frequency of the different types of table access). Table buffering is deactivated because it is not possible to know what these values will be in the customer system. If table buffering would be advantageous for the table size and access profile of the table, you can activate it in the customer system
at any time. Buffering activated: The table should be buffered. In this case you must specify a buffering type The buffering type defines which table records are loaded into the buffer of the application server when a table record is accessed. There are the following buffering types: Full buffering Generic buffering Single-record buffering Full Buffering With full buffering, either the entire table is in the buffer or the table is not in the buffer at all. All the records of the table are loaded into the buffer when one record of the table is read.
How are the records sorted in Buffer Table? The buffered data records are sorted in the buffer by table key. Accesses to the buffered data can therefore only analyze field contents up to the last specified key field for restricting the dataset to be searched direct access to the database can be more efficient if the database has suitable secondary indexes When Should you Use Full Buffering? Following Points to be considered: 1. should take into account the size of the table, 2. the number of read accesses 3. the number of write accesses. In What are cases full buffering are needed? 1. Tables up to 30 KB in size. 2. If a table is accessed frequently, but all accesses are read accesses, this value can be exceeded 3. Larger tables where large numbers of records are frequently accessed. 4. _ Tables for which accesses to non-existent records are frequently submitted. Since all the table records reside in the buffer, the system can determine directly in the buffer whether or not a record exists. What is Generic Buffering? With generic buffering, all the records in the buffer whose generic key fields match this record are loaded when one record of the table is accessed. The generic key is a part of the primary key of the table that is left-justified.
What is Single record Buffering? With single-record buffering, only the records that are actually read are loaded into the buffer. Single-record buffering therefore requires less storage space in the buffer than generic and full buffering. The administrative costs in the buffer, however, are greater than for generic or full buffering. Considerably more database accesses are necessary to load the records than for the other buffering types.
When Should you Use Single-Record Buffering? Single-record buffering should be used particularly for large tables where only a few records are accessed with SELECT SINGLE. The size of the records being accessed should be between 100 and 200 KB. Full buffering is usually more suitable for smaller tables that are accessed frequently. This is because only one database access is necessary to load such a table with full buffering, whereas several database accesses are necessary for single-record buffering. Difference between "select * from mara" and "select single * from mara"? Whats table include?
Ans: In addition to listing the individual fields in a table or structure, fields from another structure can be included as includes. Whats named include? If an include is added to define a database table or database structure, a name can be assigned to that included (included substructure). The group of fields of that include can be addressed as a whole in ABAP application programs with a group name which is called as named include. E.g.:We can access field of a table/ structure in the ABAP application program in the following manner: <TABLE / STRUCTURE NAME > - < FIELD NAME> <TABLE / STRUCTURE NAME > - <GROUP NAME>-<FIELD NAME> <TABLE / STRUCTURE NAME > - <GROUP NAME> Q. Give an example of nested include. Ans: Structure S1 may include structure S2 and again S2 may include S3. Whats the maximum depth of nested includes in a table? Maximum depth is 9 i.e. maximum 9 structures can be included in a table/structure. Whats check table? Check table is maintained at field level for data validation. Whats check field? One of the foreign key field is marked as the check field. This depicts that the foreign key relationship is maintained for that field. When a value is entered for that check field in the table, input validation checking is done i.e. a checking is done that whether the inserted value exists in the check table or not. If doesnt exist then system rejects the entry else input validation check for that field is successful. What is delivery class? We need to insert an delivery class value while creating customized table in SAP through the transaction code SE11. Delivery class is that which regulates the transport of the tables data records (during SAP installations, SAP software upgrade, client copies, and data transport to other SAP system). SAP and its customers have different write types depending on the variety of delivery class. If Delivery class is A, it depicts that the application table for master and transaction data changes only rarely. How many types of delivery classes are there in SAP? There are following delivery classes: A: Application table (master and transaction data) is maintained by the customers using application transaction. C: Customer table. Data is maintained only by the customer. L: Table for storing temporary data. G: Customer table, new data records can be inserted but may not overwrite or delete existing ones. E: System table with its own namespaces for customer entries. S: System table, data changes have the status of program changes i.e. System table for programs nature. Maintained only by SAP. E.g.: Codes for SAP transactions. W: System table for system operation and maintenance. Table contents are maintained by maintenance transactions. E.g: function module table. What are the differences between domain and data element? i. Domain depicts the technical attributes of a field (its data type, field length, no. of decimal places, appearance on the screen) of a SAP database table. Whereas data element denotes the semantic attributes (short description, label names) for a field. ii. Data elements are directly attached to the fields of SAP database tables and each data element has an underlying domain within it. Whereas domains are not directly attached to the fields and a single domain can be under many data elements. iii. Within domain value range of a field can be described. Whereas within the data element parameter id and search help for a particular field can be assigned. Whats value table? Value table is maintained at domain level in SAP. During domain creation, value range of the domain is defined by specifying value table. Suppose for a particular domain, its value table holds the values A, B, Z. So whenever the domain will be used, system will allow to use these values only. What are the layers of data description in R/3? The external layer. The ABAP/4 layer. The database layer. Define external layer? The external layer is the plane at which the user sees and interacts with the data, that is, the data format in the user interface. This data format is independent of the database system used. Define ABAP/4 layer? The ABAP/4 layer describes the data formats used by the ABAP/4 processor.
4. Define Database layer? The database layer describes the data formats used in the database. 5. What is a Data Class? The Data class determines in which table space the table is stored when it is created in the database. 6. What is a Size Category? The Size category describes the probable space requirement of the table in the database. 8. What are control tables? The values specified for the size category and data class are mapped to database-specific values via control tables. 9. What is the function of the transport system and workbench organizer? The function of the transport system and the Workbench Organizer is to manage any changes made to objects of the ABAP/4 Development Workbench and to transport these changes between different SAP systems. 10. What is a table pool? A table pool (or pool) is used to combine several logical tables in the ABAP/4 Dictionary. The definition of a pool consists of at least two key fields and a long argument field (VARDATA). 11. What are pooled tables? These are logical tables, which must be assigned to a table pool when they are defined. Pooled tables can be used to store control data (such as screen sequences or program parameters). 12. What is a table cluster? A table cluster combines several logical tables in the ABAP/4 Dictionary. Several logical rows from different cluster tables are brought together in a single physical record. The records from the cluster tables assigned to a cluster are thus stored in a single common table in the database. 13. How can we access the correction and transport system? Each time you create a new object or change an existing object in the ABAP/4 Dictionary, you branch automatically to the Workbench Organizer or correction and transport system. 14. Which objects are independent transport objects? Domains, Data elements, Tables, Technical settings for tables, Secondary indexes for transparent tables, Structures, Views, Matchcode objects, Matchcode Ids, Lock objects. 15. How is conversion of data types done between ABAP/4 & DB layer? Conversion between ABAP/4 data types and the database layer is done within the database interface. 16. How is conversion of data types done between ABAP/4 & external level? Conversion between the external layer and the ABAP/4 layer is done in the SAP dialog manager DYNP. 17. What are the Data types of the external layer? ACCP, Char, CLNT, CUKY, CURR, DATS, DESC, FLTP, INT1, INT2, INT4, LANG, LCHR, LRAW, NUMC, PREC, QUAN, RAW, TIMS, UNIT,VARC. 18. What are the Data types of the ABAP/4 layer? Possible ABAP/4 data types: C: Character. D: Date, format YYYYMMDD. F: Floating-point number in DOUBLE PRECISION (8 bytes). I: Integer. N: Numerical character string of arbitrary length. P: Amount of counter field (packed; implementation depends on h/w platform). S: Time Stamp YYYYMMDDHHMMSS. V: Character string of variable length, length is given in the first two bytes. X: Hexadecimal (binary) storage. 19. How can we set the table spaces and extent sizes? You can specify the extent sizes and the table space (physical storage area in the database) in which a transparent table is to be stored by setting the size category and data class. 20. What is the function of the correction system? The correction system manages changes to internal system components. Such as objects of the ABAP/4 Dictionary. 21. What are local objects? Local objects (Dev class$TMP) are independent of correction and transport system. 22. What is a Development class? Related objects from the ABAP/4 repository are assigned to the same development class. This enables you to correct and transport related objects as a unit. 23. What is a data dictionary? Data Dictionary is a central source of data in a data management system. Its main function is to support the creation and management of data definitions. It has details about What data is contained? What are the attributes of the data? What is the relationship existing between the various data elements?
24. What functions does a data dictionary perform? In a data management system, the principal functions performed by the data dictionary are Management of data definitions. Provision of information for evaluation. Support for s/w development. Support form documentation. Ensuring that the data definitions are flexible and up-to-date. 25. What are the features of ABAP/4 Dictionary? The most important features are: Integrated to aABAP/4 Development Workbench. Active in the runtime environment. 26. What are the uses of the information in the Data dictionary? The following information is directly taken from the Data dictionary: Information on fields displayed with F1 help. Possible entries for fields displayed with F4 help. Matchcode and help views search utilities. 27. What are the basic objects of the data dictionary? Tables Domains Data elements Structures Foreign Keys 28. What are the aggregate objects in the data dictionary? Views Match codes Lock objects. 29. In the ABAP/4 Dictionary Tables can be defined independent of the underlying database (T/F). True. 30. ABAP/4 Dictionary contains the Logical definition of the table. 31. A field containing currency amounts (data type CURR) must be assigned to a reference table and a reference field. Explain. As a reference table, a system containing all the valid currencies is assigned or any other table, which contains a field with the currency key format. This field is called as reference field. The assignment of the field containing currency amounts to the reference field is made at runtime. The value in the reference field determines the currency of the amount. 32. A field containing quantity amounts (data type QUAN) must be assigned to a reference table and a reference field. Explain? As a reference table, a system table containing all the valid quantity units is assigned or any other table, which contains a field with the format or quantity units (data type UNIT). This field is called as reference field. The assignment of the field containing quantity amounts to the reference field is made at runtime. The value in the reference field determines the quantity unit of the amount. 33. What is the significance of Technical settings (specified while creating a table in the data dictionary)? By specifying technical settings we can control how database tables are created in the database. The technical settings allows us to Optimize storage space requirements. Table access behavior. Buffering required. Changes to entries logged. 34. What is a Table attribute? The table's attributes determine who is responsible for maintaining a table and which types of access are allowed for the table. The most important table attributes are: Delivery class. Table maintenance allowed. Activation type. 35. What is the significance of Delivery Class? The delivery class controls the degree to which the SAP or the customer is responsible for table maintenance. Whether SAP provides the table with or without contents. Determines the table type. Determines how the table behaves when it is first installed, at upgrade, when it is transported, and when a client copy is performed.
What are two methods of modifying SAP standard tables? Append Structures and Customizing Includes. What is the difference between a Substructure and an Append Structure? In case of a substructure, the reference originates in the table itself, in the form of a statement include.... In case of an append structure, the table itself remains unchanged and the reference originates in the append structure. To how many tables can an append structure be assigned. One. If a table that is to be extended contains a long field, we cannot use append structures why? Long fields in a table must always be located in the end, as the last field of the table. If a table has an append structure the append line must also be on the last field of the table. Can we include customizing include or an append structure with Pooled or Cluster tables? No. 42. What are the two ways for restricting the value range for a domain? By specifying fixed values. By stipulating a value table. Structures can contain data only during the runtime of a program (T/F) True. What are the aggregate objects in the Dictionary? Views Match Code. Lock Object. What are base tables of an aggregate object? The tables making up an aggregate object (primary and secondary) are called aggregate object. 46. The data of a view is not physically stored, but derived from one or more tables (t/f) True. 47. What are the 2 other types of Views, which are not allowed in Release 3.0? Structure Views. Entity Views. What is a Match Code? Match code is a tool to help us to search for data records in the system. Match Codes are an efficient and userfriendly search aid where key of a record is unknown. What are the two levels in defining a Match Code? Match Code Object. Match CodeId. . What is the max no of match code Id's that can be defined for one Match code object?* A match code Id is a one character ID that can be a letter or a number. Can we define our own Match Code ID's for SAP Matchcodes?* Yes, the number 0 to 9 are reserved for us to create our own Match Code Ids for a SAP defined Matchcode object. What is an Update type with reference to a Match code ID? If the data in one of the base tables of a matchcode ID changes, the matchcode data has to be updated. The update type stipulates when the matchcode is to be updated and how it is to be done. The update type also specifies which method is to be used for Building matchcodes. You must specify the update type when you define a matchcode ID. Can matchcode object contain Ids with different update types? Yes. What are the update types possible? The following update types are possible: Update type A: The matchcode data is updated asynchronously to database changes. Update type S: The matchcode data is updated synchronously to database changes. Update type P: The matchcode data is updated by the application program. Update type I: Access to the matchcode data is managed using a database view. Update type L: Access to the matchcode is achieved by calling a function module. What are the two different ways of building a match code object? A match code can be built in two different ways: Logical structure: The matchcode data is set up temporarily at the moment when the match code is accessed. (Update type I, k). Physical Structure: The match code data is physically stored in a separate table in the database. (Update type A, S, What are the differences between a Database index and a match code? Match code can contain fields from several tables whereas an index can contain fields from only one table. Match code objects can be built on transparent tables and pooled and cluster tables.
What is the function of a Domain? A domain describes the technical settings of a table field. A domain defines a value range, which sets the permissible data values for the fields, which refers to this domain. A single domain can be used as basis for any number of fields that are identical in structure. Can you delete a domain, which is being used by data elements? No. What are conversion routines? Non-standard conversions from display format to sap internal format and vice-versa are implemented with so called conversion routines. What is the function of a data element? A data element describes the role played by a domain in a technical context. A data element contains semantic information. Can a domain, assigned to a data element be changed? Yes. We can do so by just overwriting the entry in the field domain. Can you delete data element, which is being used by table fields. No. Can you define a field without a data element? Yes. If you want to specify no data element and therefore no domain for a field, you can enter data type and field length and a short text directly in the table maintenance. What are null values? If the value of a field in a table is undefined or unknown, it is called a null value. What is the difference between a structure and a table? Structures are constructed the almost the same way as tables, the only difference using that no database table is generated from them. What is a view? A view is a logical view on one or more tables. A view on one or more tables i.e., the data from a view is not actually physically stored instead being derived from one or more tables. How many types of Views are there? Database View Help View Projection View Maintenance View What is Locking? When two users simultaneously attempt to access the same data record, this is synchronized by a lock mechanism. What is database utility? Database utility is the interface between the ABAP/4 Dictionary and the underlying the SAP system. What are the basic functions of Database utility? The basic functions of database utility are: Create database objects. Delete database objects. Adjust database objects to changed ABAP/4 dictionary definition. What is Repository Info. Systems? It is a tool with which you can make data stored in the ABAP/4 Dictionary available.
What is the use of start-of-selection event? Ans: Start-of-selection is called implicity even it is not used in the program. start-of-selection is triggered after the standard selection screen has been displayed. What is the difference between end-of-page and end-of-selection? Ans: End-of-page : is footer of the page. End-of-selection: is triggered At the end of the processing block. If you write a write statement after end-of-selection, will that be triggered? Ans: Yes
How to create a button in selection screen?
Ans: Using parametres
How to add a gui status in a selection screen? Ans: sorry i dont know i thik using set pf. How to create a check box/option button in a list? Ans: Regarding Runtime creation of Check Boxes Can you call a bdc program from a report? how? Ans: Yes through Submit and return Can you call a transaction from a report? how? Ans: Yes Using Call transaction and leave to.
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5834)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (824)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (405)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Oracle PLSQL Developer ResumeDocument7 pagesOracle PLSQL Developer ResumeSenthil Kumar JayabalanNo ratings yet
- Bridge Condition Rating Data Modeling Using Deep Learning AlgorithmDocument15 pagesBridge Condition Rating Data Modeling Using Deep Learning AlgorithmPalisa Arafin100% (1)
- Unit 1 DBMSDocument116 pagesUnit 1 DBMSjgjeslinNo ratings yet
- PRP DAAI-IMDocument24 pagesPRP DAAI-IMVamsi Boya100% (1)
- DDBMS ArchitectureDocument11 pagesDDBMS ArchitectureArnab SahaNo ratings yet
- Sindu YellapuDocument8 pagesSindu Yellapunishant.bNo ratings yet
- Recommended Default Settings For A New PostgreSQL or EPAS Installation - WindowsDocument5 pagesRecommended Default Settings For A New PostgreSQL or EPAS Installation - WindowsGilberto MartinsNo ratings yet
- Spark SQLDocument34 pagesSpark SQLRoxana Godoy AstudilloNo ratings yet
- Web Application Hacking Penetration Testing 5 Day Hands On Course Syllabus v2.0 NewDocument8 pagesWeb Application Hacking Penetration Testing 5 Day Hands On Course Syllabus v2.0 NewstrokenfilledNo ratings yet
- LAB: String Patterns, Sorting & Grouping: HR DatabaseDocument18 pagesLAB: String Patterns, Sorting & Grouping: HR Databasedj Best MusicNo ratings yet
- Understanding The Personify APIDocument67 pagesUnderstanding The Personify APIDoradNo ratings yet
- Connected and Disconnected CH 4Document4 pagesConnected and Disconnected CH 4KHATRI DHRUVNo ratings yet
- PLSQLDocument34 pagesPLSQLPooja GoyalNo ratings yet
- ExampleDocument1 pageExampleangelica villegasNo ratings yet
- Chapter 6 AIS2 HandoutsDocument8 pagesChapter 6 AIS2 HandoutsMark Lawrence Yusi100% (1)
- Challenging Cycle Sheet Web Technologies (SWE1008) PHP and MysqlDocument4 pagesChallenging Cycle Sheet Web Technologies (SWE1008) PHP and Mysqlmsroshi madhuNo ratings yet
- Dbms Lab Practical 2018Document5 pagesDbms Lab Practical 2018Pooja mayakrishnan100% (1)
- SAP Data Archiving Demo - Ravi AnandDocument16 pagesSAP Data Archiving Demo - Ravi AnandRavi AnandNo ratings yet
- Software Engineering - Unit-2Document26 pagesSoftware Engineering - Unit-2lakshmilavanyaNo ratings yet
- Sagar MCQ DbmsDocument4 pagesSagar MCQ Dbmssagar teteNo ratings yet
- Script To Generate DocumentsDocument5 pagesScript To Generate DocumentsPrasad ReddNo ratings yet
- Ganpat University: Laplace TransformsDocument11 pagesGanpat University: Laplace TransformsyagneshNo ratings yet
- Hive What Is Hive?Document3 pagesHive What Is Hive?mmmNo ratings yet
- Nicky Van Vroenhoven - Query Folding in Power BIDocument53 pagesNicky Van Vroenhoven - Query Folding in Power BIleonardo.russoNo ratings yet
- BPA MigrationDocument2 pagesBPA Migrationkaipasudh1984No ratings yet
- Cópia de Random Dice Deck Database - InstructionsDocument2 pagesCópia de Random Dice Deck Database - InstructionsdesconhecidoNo ratings yet
- What Is NoSQLDocument14 pagesWhat Is NoSQLSantosh KumarNo ratings yet
- Oracle AQ - Example For Queue-To-Queue Transmission in Same Database/anotherDocument7 pagesOracle AQ - Example For Queue-To-Queue Transmission in Same Database/anothersubhash221103No ratings yet
- Views Quiz - Stanford OnlineDocument2 pagesViews Quiz - Stanford OnlineLUIS ICHAICOTO BONCANCANo ratings yet
- DataStax-WP-Apache-Cassandra-Architecture (Technical) PDFDocument22 pagesDataStax-WP-Apache-Cassandra-Architecture (Technical) PDFshah_d_pNo ratings yet