
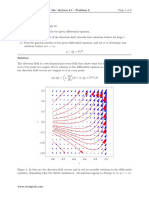
Scalable Implicit Algorithms For Sti Hyperbolic PDE Systems: L. Chacón
Scalable Implicit Algorithms For Sti Hyperbolic PDE Systems: L. Chacón
You might also like
- Low-Speed Aerodynamics, Second Edition PDFDocument29 pagesLow-Speed Aerodynamics, Second Edition PDFWei Gao100% (1)
- Pure Birth ProcessesDocument13 pagesPure Birth ProcessesDaniel Mwaniki100% (1)
- Powerpoint MathDocument10 pagesPowerpoint MathKristell Alipio67% (6)
- SoftFRAC Matlab Library For RealizationDocument10 pagesSoftFRAC Matlab Library For RealizationKotadai Le ZKNo ratings yet
- MIT2 29F11 Lect 11Document20 pagesMIT2 29F11 Lect 11costpopNo ratings yet
- Radial Fingering in A Hele-Shaw Cell: Ladhyx Internship Report, October 3 - December 23, 2011Document31 pagesRadial Fingering in A Hele-Shaw Cell: Ladhyx Internship Report, October 3 - December 23, 2011okochaflyNo ratings yet
- A New Predictor-Corrector Method For Optimal Power FlowDocument5 pagesA New Predictor-Corrector Method For Optimal Power FlowfpttmmNo ratings yet
- Bifurcation in The Dynamical System With ClearancesDocument6 pagesBifurcation in The Dynamical System With Clearancesklomps_jrNo ratings yet
- Chapter4 - 5 CFD PDFDocument25 pagesChapter4 - 5 CFD PDFTushar KarekarNo ratings yet
- Final Project PDFDocument2 pagesFinal Project PDFWillian MitziNo ratings yet
- A Stepwise Regression Method and Consistent ModelDocument42 pagesA Stepwise Regression Method and Consistent ModelMahmoud AlemamNo ratings yet
- Summation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable CoefficientsDocument33 pagesSummation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable Coefficientsadsfhire fklwjeNo ratings yet
- Extraction of Coupling Matrix of Generalized Chebyshev Filter Based On Matlab, Pei LiDocument4 pagesExtraction of Coupling Matrix of Generalized Chebyshev Filter Based On Matlab, Pei LiDenis CarlosNo ratings yet
- DC AnalysisDocument27 pagesDC AnalysisJr CallangaNo ratings yet
- Nonlinear Least Squares Theory - Lecture NotesDocument33 pagesNonlinear Least Squares Theory - Lecture NotesAnonymous tsTtieMHDNo ratings yet
- Intro 2 MD SimulationDocument20 pagesIntro 2 MD SimulationachsanuddinNo ratings yet
- ch6 Perceptron MLP PDFDocument31 pagesch6 Perceptron MLP PDFKrishnanNo ratings yet
- Obstacle Avoidance For Kinematically Redundant ManDocument7 pagesObstacle Avoidance For Kinematically Redundant Manhuynh nguyen dinhNo ratings yet
- MD 1 PDFDocument69 pagesMD 1 PDFChandra ClarkNo ratings yet
- 1 s2.0 S0895717710001743 MainDocument7 pages1 s2.0 S0895717710001743 MainAhmad DiabNo ratings yet
- Waves in Magnetoelastic MaterialsDocument22 pagesWaves in Magnetoelastic MaterialspsaxenaNo ratings yet
- Lec 14Document39 pagesLec 14Henrique Mariano AmaralNo ratings yet
- Introduction To Spectral Methods: Eric GourgoulhonDocument48 pagesIntroduction To Spectral Methods: Eric Gourgoulhonmanu2958No ratings yet
- MIT6 832s09 Exam01 PracticeDocument4 pagesMIT6 832s09 Exam01 PracticePiero RaurauNo ratings yet
- Introduction To Predictive LearningDocument101 pagesIntroduction To Predictive LearningVivek KumarNo ratings yet
- Multigrid Algorithms For Inverse Problems With Linear Parabolic Pde ConstraintsDocument29 pagesMultigrid Algorithms For Inverse Problems With Linear Parabolic Pde Constraintsapi-19973331No ratings yet
- Anderson - More Is DifferentDocument9 pagesAnderson - More Is DifferentDaniel OrsiniNo ratings yet
- Lasso SVMDocument6 pagesLasso SVMRaja Ben CharradaNo ratings yet
- Poster PT Symmetry Breaking PhysicsDocument30 pagesPoster PT Symmetry Breaking PhysicsHimadri BarmanNo ratings yet
- Physical Chemistry Exam 1 KeyDocument8 pagesPhysical Chemistry Exam 1 KeyOsama GhaniNo ratings yet
- An Algorithm To Compute The Transfer Function of A Mechanical SystemDocument6 pagesAn Algorithm To Compute The Transfer Function of A Mechanical SystemquestrwpNo ratings yet
- IEE/CEEM Seminar: Vidvuds Ozolins and Sparse Physics and Its Applications To Energy MaterialsDocument53 pagesIEE/CEEM Seminar: Vidvuds Ozolins and Sparse Physics and Its Applications To Energy MaterialsUCSBieeNo ratings yet
- Higgs Boson Physics, Part IV: Laura ReinaDocument38 pagesHiggs Boson Physics, Part IV: Laura ReinaJose Francisco Suriano ChaconNo ratings yet
- Learning Algorithms For The Classification Restricted Boltzmann MachineDocument27 pagesLearning Algorithms For The Classification Restricted Boltzmann MachineCaballero Alférez Roy TorresNo ratings yet
- b2 MechanicsDocument9 pagesb2 MechanicsSifei ZhangNo ratings yet
- Stas Lecture1Document35 pagesStas Lecture1AronNo ratings yet
- On Integral Control in Backstepping: Analysis of Different TechniquesDocument6 pagesOn Integral Control in Backstepping: Analysis of Different TechniqueslimakmNo ratings yet
- 1 s2.0 S0096300317306641 MainDocument9 pages1 s2.0 S0096300317306641 MainChang YuNo ratings yet
- PTB Talk Sinp 2016Document25 pagesPTB Talk Sinp 2016Himadri BarmanNo ratings yet
- Bifurcation Analysis of A Single Species Reacrion-Diffusion Model With Nonlocal DelayDocument33 pagesBifurcation Analysis of A Single Species Reacrion-Diffusion Model With Nonlocal DelaysecMC ussNo ratings yet
- Orion Center: Computer Simulation: W.B.MoriDocument24 pagesOrion Center: Computer Simulation: W.B.Moridjyoti96No ratings yet
- PTB Talk Sanya 2019Document37 pagesPTB Talk Sanya 2019Himadri BarmanNo ratings yet
- 4vector PhysDocument7 pages4vector Physhassaedi5263No ratings yet
- Tuning The Leading Roots of A Second Order DC Servomotor With Proportional Retarded ControlDocument6 pagesTuning The Leading Roots of A Second Order DC Servomotor With Proportional Retarded ControlKOKONo ratings yet
- How To Cook A Quantum Computer: A. Cabello, L. Danielsen, A. López Tarrida, P. MorenoDocument53 pagesHow To Cook A Quantum Computer: A. Cabello, L. Danielsen, A. López Tarrida, P. MorenoZifra RaNo ratings yet
- Outline: Junction and MOS Electrostatics (III)Document17 pagesOutline: Junction and MOS Electrostatics (III)garu1991No ratings yet
- Progress in Electromagnetics Research, PIER 52, 173-183, 2005Document11 pagesProgress in Electromagnetics Research, PIER 52, 173-183, 2005Emerson Eduardo Rodrigues SetimNo ratings yet
- Observation of J Ps Decays To e e - e e - and e eDocument9 pagesObservation of J Ps Decays To e e - e e - and e eandromosdzNo ratings yet
- SVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationDocument11 pagesSVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationChris DiehlNo ratings yet
- Lecture 5 - P-N Junction Injection and Flow - Outline: - ReviewDocument29 pagesLecture 5 - P-N Junction Injection and Flow - Outline: - ReviewAnand ChaudharyNo ratings yet
- Lec 4Document3 pagesLec 4jaurav41No ratings yet
- PTB Talk TifrDocument26 pagesPTB Talk TifrHimadri BarmanNo ratings yet
- Lecture 05 PDFDocument42 pagesLecture 05 PDFM Bhargava SaiNo ratings yet
- Exercise 1 2018Document5 pagesExercise 1 2018Trungtin Bui DucNo ratings yet
- Edge Gyrokinetic Theory and Continuum Si PDFDocument19 pagesEdge Gyrokinetic Theory and Continuum Si PDFnabinNo ratings yet
- 117 Ijmperdjun2019117Document12 pages117 Ijmperdjun2019117TJPRC PublicationsNo ratings yet
- Marco Valerio Battisti - Extended Approach To The Canonical Quantization in The MinisuperspaceDocument12 pagesMarco Valerio Battisti - Extended Approach To The Canonical Quantization in The MinisuperspaceMremefNo ratings yet
- ES386 Slides 06 N DOF LectureDocument28 pagesES386 Slides 06 N DOF Lecturejimawsd569No ratings yet
- Existence and Regularity of Periodic Solutions To Certain First-Order Partial Differential EquationsDocument24 pagesExistence and Regularity of Periodic Solutions To Certain First-Order Partial Differential EquationsAlex TedescoNo ratings yet
- Lecture 2Document55 pagesLecture 2Zahid SaleemNo ratings yet
- 2002 Austin 1aDocument27 pages2002 Austin 1aValério da Silva AlmeidaNo ratings yet
- Examination Paper For TPG4160 Reservoir Simulation: Department of Petroleum Engineering and Applied GeophysicsDocument11 pagesExamination Paper For TPG4160 Reservoir Simulation: Department of Petroleum Engineering and Applied Geophysicssid100% (1)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Airfoil Boundary-Layer Development and Transition With Large Leading-Edge RoughnessDocument10 pagesAirfoil Boundary-Layer Development and Transition With Large Leading-Edge RoughnessWei GaoNo ratings yet
- HW1 SolutionsDocument4 pagesHW1 SolutionsWei GaoNo ratings yet
- Euclid - Jam.1350488796 GoodDocument14 pagesEuclid - Jam.1350488796 GoodWei GaoNo ratings yet
- Society For Industrial and Applied MathematicsDocument26 pagesSociety For Industrial and Applied MathematicsWei GaoNo ratings yet
- An Implicit-Explicit Hybrid Method: For Lagrangian HydrodynamicsDocument28 pagesAn Implicit-Explicit Hybrid Method: For Lagrangian HydrodynamicsWei GaoNo ratings yet
- Kunci Jawaban BukuDocument2 pagesKunci Jawaban BukuDetta RamadhaniaNo ratings yet
- Solutions of Volterra Integral and Integro-Differential Equations Using Modified Laplace Adomian Decomposition MethodDocument14 pagesSolutions of Volterra Integral and Integro-Differential Equations Using Modified Laplace Adomian Decomposition MethodSweety MascarenhasNo ratings yet
- Mat 052 - P2Document20 pagesMat 052 - P2James Laroda LaceaNo ratings yet
- Calcvariations PDFDocument9 pagesCalcvariations PDFDomenico VerbicaroNo ratings yet
- Cm131a Notes 1819Document208 pagesCm131a Notes 1819sb_waradNo ratings yet
- On The Distribution of Explosion Time of StochastiDocument18 pagesOn The Distribution of Explosion Time of StochastiapuntesjmznNo ratings yet
- C2 Trigonometry - Target Board SolnsDocument6 pagesC2 Trigonometry - Target Board SolnsGMNo ratings yet
- Logarithms - Past Edexcel Exam Questions: C Studywell Publications Ltd. 2015Document7 pagesLogarithms - Past Edexcel Exam Questions: C Studywell Publications Ltd. 2015Sayar U A FourNo ratings yet
- Alvian Iqbal Hanif N 13614013 No.1 Figure 18.4Document17 pagesAlvian Iqbal Hanif N 13614013 No.1 Figure 18.4Alvian Iqbal Hanif NasrullahNo ratings yet
- 2.4 To Form Quadratic Equations From Given RootsDocument5 pages2.4 To Form Quadratic Equations From Given RootsJianjie OngNo ratings yet
- Linear Equation in Two VariableDocument2 pagesLinear Equation in Two Variablerajesh kumar sainiNo ratings yet
- Ch13-Dennis G. Zill - Warren S. Wright-Advanced Engineering Mathematics-Jones - Amp - Bartlett Learning (2012)Document38 pagesCh13-Dennis G. Zill - Warren S. Wright-Advanced Engineering Mathematics-Jones - Amp - Bartlett Learning (2012)Nguyễn Chí NguyệnNo ratings yet
- HW 2 SolnsDocument5 pagesHW 2 SolnsHiya MukherjeeNo ratings yet
- M257 316 2012 Lecture 2Document8 pagesM257 316 2012 Lecture 2Irani GonçalvesNo ratings yet
- Our Lady of Guadalupe Minor Seminary Area A Table of Specification 1 Quarter Mathematics 9 School Year: 2020-2021Document1 pageOur Lady of Guadalupe Minor Seminary Area A Table of Specification 1 Quarter Mathematics 9 School Year: 2020-2021Bernadette Remigio - JovellanosNo ratings yet
- An Introduction To The Split Step Fourier Method Using MATLABDocument15 pagesAn Introduction To The Split Step Fourier Method Using MATLABLeonard Nsah100% (1)
- Quasilinear Timefrac Parabolic Equation-MRDocument17 pagesQuasilinear Timefrac Parabolic Equation-MRUzair MalikNo ratings yet
- MS Xii Maths PB3 2023-24Document9 pagesMS Xii Maths PB3 2023-24abhay012abhay3No ratings yet
- Delft University of Technology Faculty of Elec. Eng, Mathematics and Comp. SCDocument2 pagesDelft University of Technology Faculty of Elec. Eng, Mathematics and Comp. SCPythonraptorNo ratings yet
- Particle in WellDocument20 pagesParticle in WellSrijan Garg100% (1)
- WWW tamilMV CZDocument35 pagesWWW tamilMV CZShaik Ikram Shaik Ikram2017No ratings yet
- Mathematical Methods For Physicists Webber/Arfken Selected Solutions Ch. 8Document4 pagesMathematical Methods For Physicists Webber/Arfken Selected Solutions Ch. 8Josh Brewer50% (2)
- Grade 9 Math SummativeDocument3 pagesGrade 9 Math SummativeGianmarie Sumagaysay Hilado83% (6)
- Computer Application in Engineering Homework IV: Mehmet Fatih Reyhan ID: 110170002Document4 pagesComputer Application in Engineering Homework IV: Mehmet Fatih Reyhan ID: 110170002fatih reyhanNo ratings yet
- Ast CalculationDocument5 pagesAst CalculationAntony JeyendranNo ratings yet
- Ordinary Differential EquationsDocument7 pagesOrdinary Differential Equationsmaster12345No ratings yet
- Ch01 Sec2Document13 pagesCh01 Sec2alexNo ratings yet
- Euler Cauchy EquationDocument15 pagesEuler Cauchy Equationraki tetNo ratings yet






























































































Download as pdf or txt
You might also like
- Low-Speed Aerodynamics, Second Edition PDFDocument29 pagesLow-Speed Aerodynamics, Second Edition PDFWei Gao100% (1)
- Pure Birth ProcessesDocument13 pagesPure Birth ProcessesDaniel Mwaniki100% (1)
- Powerpoint MathDocument10 pagesPowerpoint MathKristell Alipio67% (6)
- SoftFRAC Matlab Library For RealizationDocument10 pagesSoftFRAC Matlab Library For RealizationKotadai Le ZKNo ratings yet
- MIT2 29F11 Lect 11Document20 pagesMIT2 29F11 Lect 11costpopNo ratings yet
- Radial Fingering in A Hele-Shaw Cell: Ladhyx Internship Report, October 3 - December 23, 2011Document31 pagesRadial Fingering in A Hele-Shaw Cell: Ladhyx Internship Report, October 3 - December 23, 2011okochaflyNo ratings yet
- A New Predictor-Corrector Method For Optimal Power FlowDocument5 pagesA New Predictor-Corrector Method For Optimal Power FlowfpttmmNo ratings yet
- Bifurcation in The Dynamical System With ClearancesDocument6 pagesBifurcation in The Dynamical System With Clearancesklomps_jrNo ratings yet
- Chapter4 - 5 CFD PDFDocument25 pagesChapter4 - 5 CFD PDFTushar KarekarNo ratings yet
- Final Project PDFDocument2 pagesFinal Project PDFWillian MitziNo ratings yet
- A Stepwise Regression Method and Consistent ModelDocument42 pagesA Stepwise Regression Method and Consistent ModelMahmoud AlemamNo ratings yet
- Summation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable CoefficientsDocument33 pagesSummation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable Coefficientsadsfhire fklwjeNo ratings yet
- Extraction of Coupling Matrix of Generalized Chebyshev Filter Based On Matlab, Pei LiDocument4 pagesExtraction of Coupling Matrix of Generalized Chebyshev Filter Based On Matlab, Pei LiDenis CarlosNo ratings yet
- DC AnalysisDocument27 pagesDC AnalysisJr CallangaNo ratings yet
- Nonlinear Least Squares Theory - Lecture NotesDocument33 pagesNonlinear Least Squares Theory - Lecture NotesAnonymous tsTtieMHDNo ratings yet
- Intro 2 MD SimulationDocument20 pagesIntro 2 MD SimulationachsanuddinNo ratings yet
- ch6 Perceptron MLP PDFDocument31 pagesch6 Perceptron MLP PDFKrishnanNo ratings yet
- Obstacle Avoidance For Kinematically Redundant ManDocument7 pagesObstacle Avoidance For Kinematically Redundant Manhuynh nguyen dinhNo ratings yet
- MD 1 PDFDocument69 pagesMD 1 PDFChandra ClarkNo ratings yet
- 1 s2.0 S0895717710001743 MainDocument7 pages1 s2.0 S0895717710001743 MainAhmad DiabNo ratings yet
- Waves in Magnetoelastic MaterialsDocument22 pagesWaves in Magnetoelastic MaterialspsaxenaNo ratings yet
- Lec 14Document39 pagesLec 14Henrique Mariano AmaralNo ratings yet
- Introduction To Spectral Methods: Eric GourgoulhonDocument48 pagesIntroduction To Spectral Methods: Eric Gourgoulhonmanu2958No ratings yet
- MIT6 832s09 Exam01 PracticeDocument4 pagesMIT6 832s09 Exam01 PracticePiero RaurauNo ratings yet
- Introduction To Predictive LearningDocument101 pagesIntroduction To Predictive LearningVivek KumarNo ratings yet
- Multigrid Algorithms For Inverse Problems With Linear Parabolic Pde ConstraintsDocument29 pagesMultigrid Algorithms For Inverse Problems With Linear Parabolic Pde Constraintsapi-19973331No ratings yet
- Anderson - More Is DifferentDocument9 pagesAnderson - More Is DifferentDaniel OrsiniNo ratings yet
- Lasso SVMDocument6 pagesLasso SVMRaja Ben CharradaNo ratings yet
- Poster PT Symmetry Breaking PhysicsDocument30 pagesPoster PT Symmetry Breaking PhysicsHimadri BarmanNo ratings yet
- Physical Chemistry Exam 1 KeyDocument8 pagesPhysical Chemistry Exam 1 KeyOsama GhaniNo ratings yet
- An Algorithm To Compute The Transfer Function of A Mechanical SystemDocument6 pagesAn Algorithm To Compute The Transfer Function of A Mechanical SystemquestrwpNo ratings yet
- IEE/CEEM Seminar: Vidvuds Ozolins and Sparse Physics and Its Applications To Energy MaterialsDocument53 pagesIEE/CEEM Seminar: Vidvuds Ozolins and Sparse Physics and Its Applications To Energy MaterialsUCSBieeNo ratings yet
- Higgs Boson Physics, Part IV: Laura ReinaDocument38 pagesHiggs Boson Physics, Part IV: Laura ReinaJose Francisco Suriano ChaconNo ratings yet
- Learning Algorithms For The Classification Restricted Boltzmann MachineDocument27 pagesLearning Algorithms For The Classification Restricted Boltzmann MachineCaballero Alférez Roy TorresNo ratings yet
- b2 MechanicsDocument9 pagesb2 MechanicsSifei ZhangNo ratings yet
- Stas Lecture1Document35 pagesStas Lecture1AronNo ratings yet
- On Integral Control in Backstepping: Analysis of Different TechniquesDocument6 pagesOn Integral Control in Backstepping: Analysis of Different TechniqueslimakmNo ratings yet
- 1 s2.0 S0096300317306641 MainDocument9 pages1 s2.0 S0096300317306641 MainChang YuNo ratings yet
- PTB Talk Sinp 2016Document25 pagesPTB Talk Sinp 2016Himadri BarmanNo ratings yet
- Bifurcation Analysis of A Single Species Reacrion-Diffusion Model With Nonlocal DelayDocument33 pagesBifurcation Analysis of A Single Species Reacrion-Diffusion Model With Nonlocal DelaysecMC ussNo ratings yet
- Orion Center: Computer Simulation: W.B.MoriDocument24 pagesOrion Center: Computer Simulation: W.B.Moridjyoti96No ratings yet
- PTB Talk Sanya 2019Document37 pagesPTB Talk Sanya 2019Himadri BarmanNo ratings yet
- 4vector PhysDocument7 pages4vector Physhassaedi5263No ratings yet
- Tuning The Leading Roots of A Second Order DC Servomotor With Proportional Retarded ControlDocument6 pagesTuning The Leading Roots of A Second Order DC Servomotor With Proportional Retarded ControlKOKONo ratings yet
- How To Cook A Quantum Computer: A. Cabello, L. Danielsen, A. López Tarrida, P. MorenoDocument53 pagesHow To Cook A Quantum Computer: A. Cabello, L. Danielsen, A. López Tarrida, P. MorenoZifra RaNo ratings yet
- Outline: Junction and MOS Electrostatics (III)Document17 pagesOutline: Junction and MOS Electrostatics (III)garu1991No ratings yet
- Progress in Electromagnetics Research, PIER 52, 173-183, 2005Document11 pagesProgress in Electromagnetics Research, PIER 52, 173-183, 2005Emerson Eduardo Rodrigues SetimNo ratings yet
- Observation of J Ps Decays To e e - e e - and e eDocument9 pagesObservation of J Ps Decays To e e - e e - and e eandromosdzNo ratings yet
- SVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationDocument11 pagesSVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationChris DiehlNo ratings yet
- Lecture 5 - P-N Junction Injection and Flow - Outline: - ReviewDocument29 pagesLecture 5 - P-N Junction Injection and Flow - Outline: - ReviewAnand ChaudharyNo ratings yet
- Lec 4Document3 pagesLec 4jaurav41No ratings yet
- PTB Talk TifrDocument26 pagesPTB Talk TifrHimadri BarmanNo ratings yet
- Lecture 05 PDFDocument42 pagesLecture 05 PDFM Bhargava SaiNo ratings yet
- Exercise 1 2018Document5 pagesExercise 1 2018Trungtin Bui DucNo ratings yet
- Edge Gyrokinetic Theory and Continuum Si PDFDocument19 pagesEdge Gyrokinetic Theory and Continuum Si PDFnabinNo ratings yet
- 117 Ijmperdjun2019117Document12 pages117 Ijmperdjun2019117TJPRC PublicationsNo ratings yet
- Marco Valerio Battisti - Extended Approach To The Canonical Quantization in The MinisuperspaceDocument12 pagesMarco Valerio Battisti - Extended Approach To The Canonical Quantization in The MinisuperspaceMremefNo ratings yet
- ES386 Slides 06 N DOF LectureDocument28 pagesES386 Slides 06 N DOF Lecturejimawsd569No ratings yet
- Existence and Regularity of Periodic Solutions To Certain First-Order Partial Differential EquationsDocument24 pagesExistence and Regularity of Periodic Solutions To Certain First-Order Partial Differential EquationsAlex TedescoNo ratings yet
- Lecture 2Document55 pagesLecture 2Zahid SaleemNo ratings yet
- 2002 Austin 1aDocument27 pages2002 Austin 1aValério da Silva AlmeidaNo ratings yet
- Examination Paper For TPG4160 Reservoir Simulation: Department of Petroleum Engineering and Applied GeophysicsDocument11 pagesExamination Paper For TPG4160 Reservoir Simulation: Department of Petroleum Engineering and Applied Geophysicssid100% (1)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Airfoil Boundary-Layer Development and Transition With Large Leading-Edge RoughnessDocument10 pagesAirfoil Boundary-Layer Development and Transition With Large Leading-Edge RoughnessWei GaoNo ratings yet
- HW1 SolutionsDocument4 pagesHW1 SolutionsWei GaoNo ratings yet
- Euclid - Jam.1350488796 GoodDocument14 pagesEuclid - Jam.1350488796 GoodWei GaoNo ratings yet
- Society For Industrial and Applied MathematicsDocument26 pagesSociety For Industrial and Applied MathematicsWei GaoNo ratings yet
- An Implicit-Explicit Hybrid Method: For Lagrangian HydrodynamicsDocument28 pagesAn Implicit-Explicit Hybrid Method: For Lagrangian HydrodynamicsWei GaoNo ratings yet
- Kunci Jawaban BukuDocument2 pagesKunci Jawaban BukuDetta RamadhaniaNo ratings yet
- Solutions of Volterra Integral and Integro-Differential Equations Using Modified Laplace Adomian Decomposition MethodDocument14 pagesSolutions of Volterra Integral and Integro-Differential Equations Using Modified Laplace Adomian Decomposition MethodSweety MascarenhasNo ratings yet
- Mat 052 - P2Document20 pagesMat 052 - P2James Laroda LaceaNo ratings yet
- Calcvariations PDFDocument9 pagesCalcvariations PDFDomenico VerbicaroNo ratings yet
- Cm131a Notes 1819Document208 pagesCm131a Notes 1819sb_waradNo ratings yet
- On The Distribution of Explosion Time of StochastiDocument18 pagesOn The Distribution of Explosion Time of StochastiapuntesjmznNo ratings yet
- C2 Trigonometry - Target Board SolnsDocument6 pagesC2 Trigonometry - Target Board SolnsGMNo ratings yet
- Logarithms - Past Edexcel Exam Questions: C Studywell Publications Ltd. 2015Document7 pagesLogarithms - Past Edexcel Exam Questions: C Studywell Publications Ltd. 2015Sayar U A FourNo ratings yet
- Alvian Iqbal Hanif N 13614013 No.1 Figure 18.4Document17 pagesAlvian Iqbal Hanif N 13614013 No.1 Figure 18.4Alvian Iqbal Hanif NasrullahNo ratings yet
- 2.4 To Form Quadratic Equations From Given RootsDocument5 pages2.4 To Form Quadratic Equations From Given RootsJianjie OngNo ratings yet
- Linear Equation in Two VariableDocument2 pagesLinear Equation in Two Variablerajesh kumar sainiNo ratings yet
- Ch13-Dennis G. Zill - Warren S. Wright-Advanced Engineering Mathematics-Jones - Amp - Bartlett Learning (2012)Document38 pagesCh13-Dennis G. Zill - Warren S. Wright-Advanced Engineering Mathematics-Jones - Amp - Bartlett Learning (2012)Nguyễn Chí NguyệnNo ratings yet
- HW 2 SolnsDocument5 pagesHW 2 SolnsHiya MukherjeeNo ratings yet
- M257 316 2012 Lecture 2Document8 pagesM257 316 2012 Lecture 2Irani GonçalvesNo ratings yet
- Our Lady of Guadalupe Minor Seminary Area A Table of Specification 1 Quarter Mathematics 9 School Year: 2020-2021Document1 pageOur Lady of Guadalupe Minor Seminary Area A Table of Specification 1 Quarter Mathematics 9 School Year: 2020-2021Bernadette Remigio - JovellanosNo ratings yet
- An Introduction To The Split Step Fourier Method Using MATLABDocument15 pagesAn Introduction To The Split Step Fourier Method Using MATLABLeonard Nsah100% (1)
- Quasilinear Timefrac Parabolic Equation-MRDocument17 pagesQuasilinear Timefrac Parabolic Equation-MRUzair MalikNo ratings yet
- MS Xii Maths PB3 2023-24Document9 pagesMS Xii Maths PB3 2023-24abhay012abhay3No ratings yet
- Delft University of Technology Faculty of Elec. Eng, Mathematics and Comp. SCDocument2 pagesDelft University of Technology Faculty of Elec. Eng, Mathematics and Comp. SCPythonraptorNo ratings yet
- Particle in WellDocument20 pagesParticle in WellSrijan Garg100% (1)
- WWW tamilMV CZDocument35 pagesWWW tamilMV CZShaik Ikram Shaik Ikram2017No ratings yet
- Mathematical Methods For Physicists Webber/Arfken Selected Solutions Ch. 8Document4 pagesMathematical Methods For Physicists Webber/Arfken Selected Solutions Ch. 8Josh Brewer50% (2)
- Grade 9 Math SummativeDocument3 pagesGrade 9 Math SummativeGianmarie Sumagaysay Hilado83% (6)
- Computer Application in Engineering Homework IV: Mehmet Fatih Reyhan ID: 110170002Document4 pagesComputer Application in Engineering Homework IV: Mehmet Fatih Reyhan ID: 110170002fatih reyhanNo ratings yet
- Ast CalculationDocument5 pagesAst CalculationAntony JeyendranNo ratings yet
- Ordinary Differential EquationsDocument7 pagesOrdinary Differential Equationsmaster12345No ratings yet
- Ch01 Sec2Document13 pagesCh01 Sec2alexNo ratings yet
- Euler Cauchy EquationDocument15 pagesEuler Cauchy Equationraki tetNo ratings yet