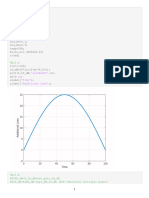
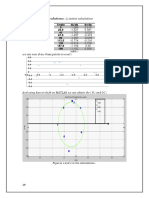
Download as ppt, pdf, or txt
You might also like
- Tech It Easy 3 Activity BookDocument23 pagesTech It Easy 3 Activity BookEleniNo ratings yet
- Fiona Apple All LyricsDocument74 pagesFiona Apple All Lyricsscarlett_merino0% (1)
- PerDev - Q2 - Module 3Document45 pagesPerDev - Q2 - Module 3jeysel calumbaNo ratings yet
- Sem Data AnalysisDocument36 pagesSem Data AnalysisBaraa SbaihNo ratings yet
- Probability and SamplingDistributionsDocument59 pagesProbability and SamplingDistributionsRmro Chefo LuigiNo ratings yet
- Practice 24 25Document10 pagesPractice 24 25Marisnelvys CabrejaNo ratings yet
- Chapter 3 - Data Visualization Chapter 4 - Summary StatisticsDocument38 pagesChapter 3 - Data Visualization Chapter 4 - Summary StatisticsjayNo ratings yet
- Kolmogorov Smirnov (K-S) TestDocument3 pagesKolmogorov Smirnov (K-S) TestAnonymous Tb9WqNsSUqNo ratings yet
- Teknik SimulasiDocument5 pagesTeknik SimulasiBee BaiiNo ratings yet
- Kingrynormalized Data Set AssignmentDocument24 pagesKingrynormalized Data Set Assignment20013122-001No ratings yet
- Lecture 3 Part 1 Understanding Data With StatisticsDocument7 pagesLecture 3 Part 1 Understanding Data With Statisticszhraa qassemNo ratings yet
- Lab2 2 8Document7 pagesLab2 2 8duelgodgaming007No ratings yet
- Syns 11Document4 pagesSyns 11Nikkaa XOXNo ratings yet
- Adobe Scan Jun 29, 2022Document3 pagesAdobe Scan Jun 29, 2022Himanshi GoplaniNo ratings yet
- Decimal SubtractionDocument1 pageDecimal SubtractionGAYATHRI MNo ratings yet
- This Is Only For Practice and Will Not Be GradedDocument5 pagesThis Is Only For Practice and Will Not Be GradedVikash KumarNo ratings yet
- Generic TST Protocol Distributed Annexes KNCVDocument14 pagesGeneric TST Protocol Distributed Annexes KNCVtheresiaNo ratings yet
- Lab AlbertDocument106 pagesLab AlbertRicardo De Can Menor XNo ratings yet
- Practical On Nonparametric Statistical TestsDocument16 pagesPractical On Nonparametric Statistical TestsMoni SarkerNo ratings yet
- AT70.20: Applied Machine Vision, Midterm Exam: Mon Feb 27, 2017Document8 pagesAT70.20: Applied Machine Vision, Midterm Exam: Mon Feb 27, 2017Vidura Yashodha GamageNo ratings yet
- Decimal SubtractionDocument1 pageDecimal SubtractionGAYATHRI MNo ratings yet
- Data Analytics Tools and Techniques: Post Graduate Diploma in Management (2019-2021)Document11 pagesData Analytics Tools and Techniques: Post Graduate Diploma in Management (2019-2021)Mayur KaushikNo ratings yet
- Stat 2032 2014 Final SolutionsDocument12 pagesStat 2032 2014 Final SolutionsJasonNo ratings yet
- Lab 8 - 143Document21 pagesLab 8 - 143CHETAN SETIYANo ratings yet
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- AppendixDocument12 pagesAppendixsadyehclenNo ratings yet
- This Template Is Obtained From HTTP://WWW - Andypope.info Above Mentioned Website Has Great Worksheets Tutorials and Excellent SamplesDocument5 pagesThis Template Is Obtained From HTTP://WWW - Andypope.info Above Mentioned Website Has Great Worksheets Tutorials and Excellent SamplesiPakistanNo ratings yet
- This Template Is Obtained From HTTP://WWW - Andypope.info Above Mentioned Website Has Great Worksheets Tutorials and Excellent SamplesDocument5 pagesThis Template Is Obtained From HTTP://WWW - Andypope.info Above Mentioned Website Has Great Worksheets Tutorials and Excellent Samplesanon-13887No ratings yet
- Materi Uji Normalitas Mata Kuliah Pengolahan DataDocument4 pagesMateri Uji Normalitas Mata Kuliah Pengolahan DataafrahamiryanoNo ratings yet
- Skip GramDocument37 pagesSkip GramShikha JainNo ratings yet
- GetmekDocument3 pagesGetmekJamali Khoirul 'AbidinNo ratings yet
- Shipra Rajput Assignment 2Document4 pagesShipra Rajput Assignment 2MR. SHUBHAM PRAVIN SOMANINo ratings yet
- EJEMPLO: Calcular Los Desplazamientos de La Siguiente EstructuraDocument3 pagesEJEMPLO: Calcular Los Desplazamientos de La Siguiente EstructuraAlex Bustamante LaraNo ratings yet
- Tristan Camilleri - SOR0511 - Questions - 2021.06.20Document33 pagesTristan Camilleri - SOR0511 - Questions - 2021.06.20TristanCamilleriNo ratings yet
- Modeling and Simulation (Tcs-506) Assignment 2Document2 pagesModeling and Simulation (Tcs-506) Assignment 2Anurag BairagiNo ratings yet
- HW 2 CHAP 2 - YepezDocument9 pagesHW 2 CHAP 2 - YepezElviraNo ratings yet
- 08 TestDocument11 pages08 TestPETER0% (1)
- Numerical Analysis: Exercise 1Document6 pagesNumerical Analysis: Exercise 1Nhật LinhNo ratings yet
- Kinds of CatDocument406 pagesKinds of Catminhnguyen25253535No ratings yet
- AUC - Calculator and Review of AUC CurveDocument2,810 pagesAUC - Calculator and Review of AUC CurveKeshav PrakashNo ratings yet
- AUC - Calculator and Review of AUC CurveDocument410 pagesAUC - Calculator and Review of AUC CurvewaduNo ratings yet
- STA302 Mid 2010FDocument9 pagesSTA302 Mid 2010FexamkillerNo ratings yet
- 1Document4 pages1Arpita DasNo ratings yet
- 26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienDocument18 pages26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienPhạm Minh ChâuNo ratings yet
- Tabla OcrDocument6 pagesTabla OcrAlpq.w AlanyaNo ratings yet
- The Expected Value and Variance of A Discrete Random VariableDocument14 pagesThe Expected Value and Variance of A Discrete Random VariableLiana Putri MaharaniNo ratings yet
- Empirical Project Assignment 1Document6 pagesEmpirical Project Assignment 1ehitNo ratings yet
- demoLOGbin ENDocument146 pagesdemoLOGbin ENKaim OuaraNo ratings yet
- D (I, J) R+s Q +R +S+TDocument5 pagesD (I, J) R+s Q +R +S+TNitish NehraNo ratings yet
- Assignment 3 Report - FinalDocument8 pagesAssignment 3 Report - FinalMustafa MogriNo ratings yet
- Simulation Homework 3 Chapter 2 Random NumbersDocument3 pagesSimulation Homework 3 Chapter 2 Random NumbersMichelle ToalaNo ratings yet
- " - " I Drive: "Dream in Pocket"Document25 pages" - " I Drive: "Dream in Pocket"shubham_hazraNo ratings yet
- Ej.08.4.Cpm - SPC.2.2005 Abril 2006Document4 pagesEj.08.4.Cpm - SPC.2.2005 Abril 2006Tiberio Valdivieso BaronaNo ratings yet
- Problem Set 2Document5 pagesProblem Set 2Ezgi Nilay UzunNo ratings yet
- Experimental CalculationsDocument5 pagesExperimental CalculationsmomenNo ratings yet
- Distance (M) Time (S) : Position Model (S) Square DifferencesDocument73 pagesDistance (M) Time (S) : Position Model (S) Square DifferencesSilvestre GutierrezNo ratings yet
- Chaos and The Logistic Map: PHYS220 2004 by Lesa MooreDocument51 pagesChaos and The Logistic Map: PHYS220 2004 by Lesa MooreMounesh BasavarajNo ratings yet
- Solution MatlabDocument46 pagesSolution MatlabFreddy Mendoza CoronelNo ratings yet
- Tutorial 5 Q4Document3 pagesTutorial 5 Q4PeterMajorNo ratings yet
- Experimental Verification of Principle of Superposition For An Indeterminate StructureDocument10 pagesExperimental Verification of Principle of Superposition For An Indeterminate StructureRupinder SinghNo ratings yet
- Decision Science Q1Document12 pagesDecision Science Q1Nageshwar SinghNo ratings yet
- Advanced Mathematics for Engineers and ScientistsFrom EverandAdvanced Mathematics for Engineers and ScientistsRating: 4 out of 5 stars4/5 (2)
- The Art World ExpandsDocument35 pagesThe Art World ExpandsAnonymous YoF1nHvRNo ratings yet
- Women Empowerment in IndiaDocument2 pagesWomen Empowerment in IndiaPradipta RudraNo ratings yet
- SdasasasDocument22 pagesSdasasasGianne Robert MalavegaNo ratings yet
- BPSC Senior Secondary Teacher Booklets Political ScienceDocument48 pagesBPSC Senior Secondary Teacher Booklets Political Scienceabhijeetjha81No ratings yet
- UMT TriboLab Mechanical Tester and Tribometer-B1002 RevA2-Brochure PDFDocument8 pagesUMT TriboLab Mechanical Tester and Tribometer-B1002 RevA2-Brochure PDFcatalineuuNo ratings yet
- Branding Decisions: - Submitted byDocument8 pagesBranding Decisions: - Submitted byDiksha VashishthNo ratings yet
- A Uniform Change For The Better: MembersDocument12 pagesA Uniform Change For The Better: MembersAko Si Vern ÖNo ratings yet
- Scientology: Report of The Board of Inquiry Into Scientology, Victoria, Australia - 1965Document204 pagesScientology: Report of The Board of Inquiry Into Scientology, Victoria, Australia - 1965sirjsslutNo ratings yet
- WSC - BSBFIA401 SD Asset Register Worksheet V 1.0Document6 pagesWSC - BSBFIA401 SD Asset Register Worksheet V 1.0Gursheen KaurNo ratings yet
- Francesco Petrarch 1304-1374: To Be Able To Say How Much You Love Is To Love But Little."Document1 pageFrancesco Petrarch 1304-1374: To Be Able To Say How Much You Love Is To Love But Little."JongJin ParkNo ratings yet
- Valuations - DamodaranDocument308 pagesValuations - DamodaranharleeniitrNo ratings yet
- Msqe Mqek Mqed Pea 2014Document7 pagesMsqe Mqek Mqed Pea 2014Shreshth BabbarNo ratings yet
- Spiritual GiftDocument3 pagesSpiritual Giftharry misaoNo ratings yet
- Employee Commitment On Organizational Performance: K.Princy, E.RebekaDocument5 pagesEmployee Commitment On Organizational Performance: K.Princy, E.RebekaEBO The InspirationistNo ratings yet
- Science of The Total Environment: Steven G. Brown, Shelly Eberly, Pentti Paatero, Gary A. NorrisDocument10 pagesScience of The Total Environment: Steven G. Brown, Shelly Eberly, Pentti Paatero, Gary A. NorrisJuana CalderonNo ratings yet
- Nityananda SongsDocument32 pagesNityananda SongsMann Mahesh HarjaiNo ratings yet
- The Gratitude That Endears Us To God: Indigenous Peoples' SundayDocument4 pagesThe Gratitude That Endears Us To God: Indigenous Peoples' SundaycharissamacNo ratings yet
- 32 Vaporization TNDocument4 pages32 Vaporization TNAjeng FadillahNo ratings yet
- Antibiotics in AquacultureDocument2 pagesAntibiotics in AquaculturesgnewmNo ratings yet
- Liberal Pluralism 1Document24 pagesLiberal Pluralism 1Ma. Rica CatalanNo ratings yet
- 5C Artikel PROGRAM BIMBINGAN KONSELING PADA ANAK DENGAN GANGGUAN PERILAKU DI SLB HARMONI-dikonversiDocument10 pages5C Artikel PROGRAM BIMBINGAN KONSELING PADA ANAK DENGAN GANGGUAN PERILAKU DI SLB HARMONI-dikonversiAlfi Wahyuni8882No ratings yet
- Familylifeeducation CEJERDocument8 pagesFamilylifeeducation CEJERSHABRINA WIDAD NAZIHAH 2021No ratings yet
- Freshsales Product Overview Detailed Nov2017Document54 pagesFreshsales Product Overview Detailed Nov2017Kris GeraldNo ratings yet
- Province of Cam Sur V CA DigestDocument2 pagesProvince of Cam Sur V CA Digestalma navarro escuzar100% (5)
- How To Write A CommentaryDocument4 pagesHow To Write A CommentaryHarishJainNo ratings yet
- English Placement TestDocument16 pagesEnglish Placement TestMariana GheorgheNo ratings yet
- DruidDocument24 pagesDruidשובל לויNo ratings yet