Download as pptx, pdf, or txt
You might also like
- Literature Review For Consumer PerceptionDocument10 pagesLiterature Review For Consumer PerceptionArun Girish60% (5)
- 09 ParallelizationRecap PDFDocument62 pages09 ParallelizationRecap PDFgiordano manciniNo ratings yet
- Automatically Converting C/ C++ To Opencl/Cuda: Introduction by David WilliamsDocument52 pagesAutomatically Converting C/ C++ To Opencl/Cuda: Introduction by David Williamscrazy_1No ratings yet
- Cuda Notes From Udacity LectureDocument3 pagesCuda Notes From Udacity LectureJ GNo ratings yet
- Pthreads ModDocument110 pagesPthreads ModDr. V. Padmavathi Associate ProfessorNo ratings yet
- Os MidTerm SolutionDocument8 pagesOs MidTerm SolutionZiyad AhmedNo ratings yet
- Odin Downloader Release NotesDocument9 pagesOdin Downloader Release Notesyash02005No ratings yet
- Independent Verification of Ipsec Functionality in Freebsd: David HonigDocument6 pagesIndependent Verification of Ipsec Functionality in Freebsd: David HonigVictor CorralNo ratings yet
- Session 31Document64 pagesSession 31Ashish ReddyNo ratings yet
- Class4 Advanced Cuda OpenclDocument64 pagesClass4 Advanced Cuda OpenclCarlangaslangasNo ratings yet
- Slides 8Document10 pagesSlides 8Manish Choudhary HarnawaNo ratings yet
- Chapter 13: Threads (6 HRS) Chapter Objective:: Page 1 of 16 Prepared By: Lawrence G. Decamora III, SCJPDocument16 pagesChapter 13: Threads (6 HRS) Chapter Objective:: Page 1 of 16 Prepared By: Lawrence G. Decamora III, SCJPAlex Cipher BallesterNo ratings yet
- Macos Kernel in SecurityDocument33 pagesMacos Kernel in SecurityVijayaLakshmiNo ratings yet
- 3 Some Commonly Used CUDA API: 3.1 Function Type QualifiersDocument7 pages3 Some Commonly Used CUDA API: 3.1 Function Type QualifiersMuhammad AzmatNo ratings yet
- Computer Basic Book 2 (1) 063636Document67 pagesComputer Basic Book 2 (1) 063636Kamal PandeyNo ratings yet
- SWE2007 - Fundamentals of Operating SystemsDocument6 pagesSWE2007 - Fundamentals of Operating SystemsmaneeshmogallpuNo ratings yet
- CS 378 (Spring 2003) : Linux Kernel ProgrammingDocument32 pagesCS 378 (Spring 2003) : Linux Kernel Programmingmanny oluanNo ratings yet
- CUDA - MonteCarloPi CodeDocument6 pagesCUDA - MonteCarloPi CodejitenparekhNo ratings yet
- Kernel Hacking: Introduction To Linux Kernel 2.6 How To Write A RootkitDocument28 pagesKernel Hacking: Introduction To Linux Kernel 2.6 How To Write A RootkitRAVICHANDRA VNo ratings yet
- How To Create Symbian Peripherals With QemuDocument4 pagesHow To Create Symbian Peripherals With QemuAakash SasidharanNo ratings yet
- Openmp Tutorial: Seung-Jai MinDocument30 pagesOpenmp Tutorial: Seung-Jai MinFrancesco LombardiNo ratings yet
- Lab Report 6Document12 pagesLab Report 6Rama AliNo ratings yet
- Discussion Questions 5Document2 pagesDiscussion Questions 5Sudip AdhikariNo ratings yet
- IPC in Unix of POSIX StandardDocument6 pagesIPC in Unix of POSIX Standardsyam prasad reddyNo ratings yet
- UP AssignmentDocument13 pagesUP AssignmentAmruth GowdaNo ratings yet
- Midterm Fall2012SolutionsDocument6 pagesMidterm Fall2012SolutionsanjugaduNo ratings yet
- Complete Lab ProgramsDocument23 pagesComplete Lab ProgramsGowtham VenkataramanNo ratings yet
- CudaDocument44 pagesCudaavinash kumarNo ratings yet
- QEMU Emulator User Documentation: 1.1 FeaturesDocument88 pagesQEMU Emulator User Documentation: 1.1 FeaturesEternal TyroNo ratings yet
- Fedora 17 Boot Optimization (From 15 To 2Document14 pagesFedora 17 Boot Optimization (From 15 To 2SSJ4GudduNo ratings yet
- Laboratory Manual: Applied Operating System (IT 607)Document21 pagesLaboratory Manual: Applied Operating System (IT 607)naidujhsnNo ratings yet
- In-Depth Network Programming in C++Document5 pagesIn-Depth Network Programming in C++fiorinalavacca500No ratings yet
- Cuda TalkDocument82 pagesCuda TalkKevin Salmeron Vicente100% (1)
- Tutorial 1 5Document10 pagesTutorial 1 5Zack Chh100% (1)
- Storing Data Directly From Oracle SGADocument9 pagesStoring Data Directly From Oracle SGAKaramela MelakaraNo ratings yet
- Objective QuestionsDocument14 pagesObjective QuestionssdhanaeceNo ratings yet
- p59 0x0a Execution Path Analysis Finding Kernel Rootkits by J.K.rutkowskiDocument22 pagesp59 0x0a Execution Path Analysis Finding Kernel Rootkits by J.K.rutkowskiabuadzkasalafyNo ratings yet
- #Splitvg #RecreatevgDocument19 pages#Splitvg #RecreatevgabhidhingraNo ratings yet
- How To Install GmtsarDocument24 pagesHow To Install GmtsardedetmixNo ratings yet
- Introduction To CUDA: CAP 4730 Spring 2012Document35 pagesIntroduction To CUDA: CAP 4730 Spring 2012Manvendra Singh ChhajerhNo ratings yet
- A B+a B A-B A A-B 2) : 1) Swap Two Variables Without Using Third VariableDocument33 pagesA B+a B A-B A A-B 2) : 1) Swap Two Variables Without Using Third VariableBadri NarayananNo ratings yet
- MainDocument15 pagesMainvictor manuel diazNo ratings yet
- Scenario Based QuestionsDocument30 pagesScenario Based QuestionsRavi DubeyNo ratings yet
- Eliminating The Hardware/Software Divide: Satnam Singh, Microsoft Research Cambridge, UKDocument146 pagesEliminating The Hardware/Software Divide: Satnam Singh, Microsoft Research Cambridge, UKMayam AyoNo ratings yet
- Data-Level Parallelism in Vector, SIMD, And: GPU ArchitecturesDocument29 pagesData-Level Parallelism in Vector, SIMD, And: GPU ArchitecturesMarcelo AraujoNo ratings yet
- Week 2Document22 pagesWeek 2Shubhadeep GhatakNo ratings yet
- The Test On CS: Open Followed by Fork 3mark Fork Followed by Exec Read Followed by Fork ForkDocument13 pagesThe Test On CS: Open Followed by Fork 3mark Fork Followed by Exec Read Followed by Fork ForkmichaelgodfatherNo ratings yet
- Tutorial LTE SimDocument6 pagesTutorial LTE SimgowdamandaviNo ratings yet
- Mid TDocument7 pagesMid TBSK KEITHNo ratings yet
- How To Develop An Operating System UsingDocument14 pagesHow To Develop An Operating System UsingSarkarsoft SarkarNo ratings yet
- Team MembersDocument11 pagesTeam Memberssamrawit MekbibNo ratings yet
- Course: Parallel Processing Lab #2 - Multithreads and OpenmpDocument14 pagesCourse: Parallel Processing Lab #2 - Multithreads and OpenmpLong NhậtNo ratings yet
- Pgi Cuda TutorialDocument58 pagesPgi Cuda TutorialMaziar IraniNo ratings yet
- Rahul Kushwah 0901io201051 Design & Analysis of Algorithm Pratical FileDocument47 pagesRahul Kushwah 0901io201051 Design & Analysis of Algorithm Pratical FileRAHUL KUSHWAH0% (1)
- Multi Threading in JavaDocument63 pagesMulti Threading in JavaKISHOREMUTCHARLANo ratings yet
- OS Lab Record - 19Document58 pagesOS Lab Record - 19Rajeshkannan VasinathanNo ratings yet
- 0S Labs Inclass Guide - HK221Document18 pages0S Labs Inclass Guide - HK221khai.trinhdinhNo ratings yet
- 0S Labs Inclass Guide - HK221Document18 pages0S Labs Inclass Guide - HK221changNo ratings yet
- File KernelDocument189 pagesFile KerneltegalexNo ratings yet
- Dreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9From EverandDreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9No ratings yet
- Iti Final Marksheet VerificationDocument1 pageIti Final Marksheet Verificationsurajnic62No ratings yet
- Computer Science Undergraduate Thesis IdeasDocument6 pagesComputer Science Undergraduate Thesis Ideasnicolegetherscharleston100% (2)
- Analysis of Students' Performances in Senior SecondDocument118 pagesAnalysis of Students' Performances in Senior SecondDanielNo ratings yet
- Exercises Assembly Language 1Document3 pagesExercises Assembly Language 1Phạm Tiến AnhNo ratings yet
- UGF9091 - Persky-OOW 2014 PBCS Hyperion Planning in The Cloud PDFDocument44 pagesUGF9091 - Persky-OOW 2014 PBCS Hyperion Planning in The Cloud PDFRaouhi El MehdiNo ratings yet
- Department of Education: Republic of The PhilippinesDocument17 pagesDepartment of Education: Republic of The PhilippinesGodfrey Dela Cruz RutaquioNo ratings yet
- It Help Desk Resume ExamplesDocument8 pagesIt Help Desk Resume Examplesf5b2q8e3100% (2)
- Food Pro 9 Week 1Document37 pagesFood Pro 9 Week 1Quee NnieNo ratings yet
- Understanding Culture, Society and Politics: Code: UCSP11/12DCS-Ic-6Document10 pagesUnderstanding Culture, Society and Politics: Code: UCSP11/12DCS-Ic-6Michael ArdizoneNo ratings yet
- CCI Interviewing StrategiesDocument3 pagesCCI Interviewing StrategiesPsicología GALNo ratings yet
- Strama Paper FormatDocument16 pagesStrama Paper FormatAlma MatterNo ratings yet
- Testing QuestionsDocument4 pagesTesting QuestionsvijaythiruveedhulaNo ratings yet
- p.041 ACC Erection ProcedureDocument131 pagesp.041 ACC Erection ProcedureDelil OzanNo ratings yet
- Assign 3 Hse E-PortfolioDocument13 pagesAssign 3 Hse E-Portfolioapi-281898491No ratings yet
- Physics Lab 1Document12 pagesPhysics Lab 1Zihad Bin RahimNo ratings yet
- Art Final Lesson Plan OriginalDocument18 pagesArt Final Lesson Plan Originalapi-657223769No ratings yet
- Project Child LabourDocument19 pagesProject Child LabourMiroNo ratings yet
- QEA-Quality Engineer With Selenium and Java-Student-HandbookDocument42 pagesQEA-Quality Engineer With Selenium and Java-Student-HandbookLokesh VuddagiriNo ratings yet
- Mangtas JD - QADocument2 pagesMangtas JD - QAMd. Mehedi HasanNo ratings yet
- NGFW OutlineDocument6 pagesNGFW OutlineMuhammad HamzaNo ratings yet
- Esl 115 A1 First Day Handout Fall 2015Document4 pagesEsl 115 A1 First Day Handout Fall 2015api-285624898No ratings yet
- 1.1 The Student Will Interpret Information Presented in Picture Timelines To ShowDocument3 pages1.1 The Student Will Interpret Information Presented in Picture Timelines To ShowTeta IdaNo ratings yet
- Recreation Aide Cover LetterDocument7 pagesRecreation Aide Cover Letterc2ykzhz4100% (1)
- Lucban ES NCM 2022Document2 pagesLucban ES NCM 2022Ritchelle PerochoNo ratings yet
- University of Maryland, College ParkDocument9 pagesUniversity of Maryland, College Parkapi-549887775No ratings yet
- English Direct Instruction Lesson Plan Template-3Document3 pagesEnglish Direct Instruction Lesson Plan Template-3api-282737826No ratings yet
- TKT Clil Part 2 Activity Types PDFDocument8 pagesTKT Clil Part 2 Activity Types PDFRachel Maria Ribeiro100% (2)
- Division Memorandum No. 354 S. 2021Document6 pagesDivision Memorandum No. 354 S. 2021janette riveraNo ratings yet
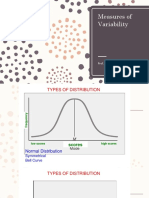
- Measures of Variability: Prof. Michelle M. Mag-IsaDocument46 pagesMeasures of Variability: Prof. Michelle M. Mag-IsaMichelle MalabananNo ratings yet