Download as pptx, pdf, or txt
You might also like
- Introduction To The EU-BIC Quality SystemDocument9 pagesIntroduction To The EU-BIC Quality SystemEnes Buladı100% (1)
- Justice in Oral Health CareDocument371 pagesJustice in Oral Health CareSara Maria Menck SangiorgioNo ratings yet
- SamplingDocument30 pagesSamplingShrutiNo ratings yet
- Sampling Process: Prof. (DR.) C.K.DashDocument43 pagesSampling Process: Prof. (DR.) C.K.DashSumit Kumar SharmaNo ratings yet
- Session 5 Sampling DistributionDocument67 pagesSession 5 Sampling Distributiondipen246No ratings yet
- Sampling and EstimationDocument15 pagesSampling and EstimationPRIYADARSHI GOURAVNo ratings yet
- Sampling: Advanced Statistics Masters in Government ManagementDocument16 pagesSampling: Advanced Statistics Masters in Government ManagementIssey Mari TiongcoNo ratings yet
- Sampling and Sampling DistributionDocument22 pagesSampling and Sampling DistributionMr Bhanushali100% (1)
- 02 ABE Review - Sampling TechniquesDocument41 pages02 ABE Review - Sampling TechniquesRio Banan IINo ratings yet
- Sampling Designing and Data SourcesDocument19 pagesSampling Designing and Data SourcesJanaki Ramani LankapothuNo ratings yet
- ACFrOgCLhIGeDgB2WhO2JO48tloZ8E rlj1-F 622LEA08XeUMCxl0syYf7HFFbqBbMYWBnDPgYh9F4QJmNJtvKVKHbz7pxfnqX2P8gOEtOFF 2tSMAPUEito ayTMU5jS3MjFiTn-YJWnV1YMeFDocument31 pagesACFrOgCLhIGeDgB2WhO2JO48tloZ8E rlj1-F 622LEA08XeUMCxl0syYf7HFFbqBbMYWBnDPgYh9F4QJmNJtvKVKHbz7pxfnqX2P8gOEtOFF 2tSMAPUEito ayTMU5jS3MjFiTn-YJWnV1YMeFADARSH CNo ratings yet
- Statistics 2: DR TaherDocument42 pagesStatistics 2: DR TaherHannan AliNo ratings yet
- BIOMETRYDocument37 pagesBIOMETRYAddisu GedamuNo ratings yet
- Introduction 3 - TaggedDocument20 pagesIntroduction 3 - TaggedAakash IyengarNo ratings yet
- Using Statistical InferenceDocument18 pagesUsing Statistical InferenceLANZ PALAPUSNo ratings yet
- 01.sampling Fundamentals-Probability SamplingDocument21 pages01.sampling Fundamentals-Probability SamplingVinodshankar BhatNo ratings yet
- Introduction To Biostatistics: Associate Professor Georgi Iskrov, PHD Department of Social MedicineDocument60 pagesIntroduction To Biostatistics: Associate Professor Georgi Iskrov, PHD Department of Social MedicineKARTHIK SREEKUMARNo ratings yet
- Chapter 4Document34 pagesChapter 4Harsh ThakurNo ratings yet
- SamplingDocument41 pagesSamplingTanmay RajeshNo ratings yet
- Ch6 Sampling and EstimationDocument24 pagesCh6 Sampling and EstimationShafaq NigarNo ratings yet
- SamplingDocument38 pagesSamplingvinod kumarNo ratings yet
- Class - Sampling MethodsDocument18 pagesClass - Sampling MethodsWilbroadNo ratings yet
- Research Methods: Sampling & PopulationDocument48 pagesResearch Methods: Sampling & PopulationAli Imran LodhiNo ratings yet
- Research Methods For Business & Management: Summer Semester - 2020/2021 Module Fourteen SamplingDocument27 pagesResearch Methods For Business & Management: Summer Semester - 2020/2021 Module Fourteen SamplingOmar HadeNo ratings yet
- Chapter 4 SAMPLING PDFDocument18 pagesChapter 4 SAMPLING PDFHabte DebeleNo ratings yet
- Chapter 6-8 Sampling and EstimationDocument48 pagesChapter 6-8 Sampling and EstimationAkashNo ratings yet
- Sample Designs and Sampling ProceduresDocument29 pagesSample Designs and Sampling ProceduressleshiNo ratings yet
- Sampling DesignDocument21 pagesSampling DesignRuchita BiyaniNo ratings yet
- Chapter 10Document16 pagesChapter 10Carmenn LouNo ratings yet
- PSYC 334 Session 9 SlidesDocument56 pagesPSYC 334 Session 9 SlidesFELIX ADDONo ratings yet
- Sampling PPTDocument46 pagesSampling PPTvijendrameena044No ratings yet
- Sampling in Daily LifeDocument45 pagesSampling in Daily LifekittukishoreNo ratings yet
- 2 Tecniche Di Campionamento (English)Document16 pages2 Tecniche Di Campionamento (English)marco sponzielloNo ratings yet
- Applied Environmental StatisticsDocument35 pagesApplied Environmental StatisticsMawuliNo ratings yet
- AP Stat Ch17Document110 pagesAP Stat Ch17Ryan Robert AbundoNo ratings yet
- Wk7 Sampling DesignDocument31 pagesWk7 Sampling DesignRameish SubarmaniyanNo ratings yet
- Statistical Sampling and Sampling TechniquesDocument13 pagesStatistical Sampling and Sampling Techniquessumit71sharmaNo ratings yet
- Sampling (Method)Document31 pagesSampling (Method)kia.reshuNo ratings yet
- Sampling TechniqueDocument38 pagesSampling TechniqueMohamed SalemNo ratings yet
- Sampling Theory And: Its Various TypesDocument46 pagesSampling Theory And: Its Various TypesAashish KumarNo ratings yet
- Sampling Methods and Technique: by Dr. Prasant SarangiDocument34 pagesSampling Methods and Technique: by Dr. Prasant SarangiRajat GargNo ratings yet
- SamplingDocument41 pagesSamplingShailendra DhakadNo ratings yet
- Operatinalization Measurement SamplingDocument79 pagesOperatinalization Measurement SamplingCharina DailoNo ratings yet
- Lecture 0317Document29 pagesLecture 0317Rahul BasnetNo ratings yet
- 9-1 ASAP Statistics - Sampling-1Document50 pages9-1 ASAP Statistics - Sampling-1George MathewNo ratings yet
- VII - Sampling MethodsDocument49 pagesVII - Sampling MethodsBehar AbdurahemanNo ratings yet
- Samplind@DS SirDocument16 pagesSamplind@DS SirpadmaNo ratings yet
- Data Management Plan Sampling DesignDocument30 pagesData Management Plan Sampling DesignDhruvil GosaliaNo ratings yet
- Unit-Ii Sample and Sampling DesignDocument51 pagesUnit-Ii Sample and Sampling Designtheanuuradha1993gmaiNo ratings yet
- Chapter 4 ResearchDocument32 pagesChapter 4 ResearchAbene321No ratings yet
- Sampling and ItDocument14 pagesSampling and ItNouman ShahidNo ratings yet
- Determining The Sample PlanDocument29 pagesDetermining The Sample PlanBindal HeenaNo ratings yet
- SamplingDocument59 pagesSamplingpooja100% (1)
- Research Methods & MaterialsDocument78 pagesResearch Methods & MaterialsSintayehuNo ratings yet
- Sampling & Sampling DistributionsDocument34 pagesSampling & Sampling DistributionsBhagwat BalotNo ratings yet
- Wk12 13 Describing Sample and Sampling ProcedureDocument36 pagesWk12 13 Describing Sample and Sampling Procedurejulianalexandra59No ratings yet
- 2 Data Collection 1Document38 pages2 Data Collection 1ruthdaniellemana.neustNo ratings yet
- Bag ChiDocument6 pagesBag Chianon_833741989No ratings yet
- Research Methodology: Chapter 11-SamplingDocument28 pagesResearch Methodology: Chapter 11-SamplingSerah JavaidNo ratings yet
- Sampling 1Document26 pagesSampling 1Abhijit AshNo ratings yet
- Population and SampleDocument2 pagesPopulation and SampleSummer DanteNo ratings yet
- An Introduction To EpidemiologyDocument27 pagesAn Introduction To Epidemiologyጀኔራል አሳምነው ፅጌNo ratings yet
- Clinical Features and Investigation of Breast CancerDocument26 pagesClinical Features and Investigation of Breast Cancerጀኔራል አሳምነው ፅጌNo ratings yet
- Breast Cancer: Prevention & Early DetectionDocument54 pagesBreast Cancer: Prevention & Early Detectionጀኔራል አሳምነው ፅጌNo ratings yet
- Interactive Multidisciplinary Web Conferencing: The Use of The Aperio and Polycom PVX SystemsDocument45 pagesInteractive Multidisciplinary Web Conferencing: The Use of The Aperio and Polycom PVX Systemsጀኔራል አሳምነው ፅጌNo ratings yet
- Fundamental of Nursing: Unit Eleven and TwelveDocument45 pagesFundamental of Nursing: Unit Eleven and Twelveጀኔራል አሳምነው ፅጌNo ratings yet
- Urinary Elimination: Ma. Tosca Cybil A. Torres, RN, MANDocument37 pagesUrinary Elimination: Ma. Tosca Cybil A. Torres, RN, MANጀኔራል አሳምነው ፅጌNo ratings yet
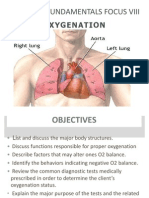
- Oxygenation: Nursing Fundamentals Focus ViiiDocument72 pagesOxygenation: Nursing Fundamentals Focus Viiiጀኔራል አሳምነው ፅጌ100% (1)
- Fundamental of Nursing: Unit Eleven and TwelveDocument45 pagesFundamental of Nursing: Unit Eleven and Twelveጀኔራል አሳምነው ፅጌNo ratings yet
- Impact of Social Media On Self-Esteem: European Scientific Journal August 2017Document14 pagesImpact of Social Media On Self-Esteem: European Scientific Journal August 2017fairylandNo ratings yet
- Term Paper On Managerial PsychologyDocument7 pagesTerm Paper On Managerial Psychologyc5q1thnj100% (1)
- Multiple Linear Regression Part-3: Lectures 24Document7 pagesMultiple Linear Regression Part-3: Lectures 24Aniket SujayNo ratings yet
- Business Statistics 2023-25Document4 pagesBusiness Statistics 2023-25akshaymatey007No ratings yet
- BH Log ProcedureDocument9 pagesBH Log ProcedureMohammed Zuber InamdarNo ratings yet
- How To Read A Quantitative) Journal ArticleDocument6 pagesHow To Read A Quantitative) Journal ArticleNguyen Trung KienNo ratings yet
- RSPO Notification of Proposed New Planting - PT SSSDocument39 pagesRSPO Notification of Proposed New Planting - PT SSSaccunkNo ratings yet
- Social Work Research Methods-II SWH236Document10 pagesSocial Work Research Methods-II SWH236HARSHA V 2037912No ratings yet
- The Influence of Tax and Financial Literacy With Business Management of Micro Enterprises in Barangay DologonDocument120 pagesThe Influence of Tax and Financial Literacy With Business Management of Micro Enterprises in Barangay Dologonf.rickallen.balandraNo ratings yet
- Diagnostics in R CommanderDocument2 pagesDiagnostics in R Commanderroy royNo ratings yet
- Academic Motivation and Self-Regulated Learning in Predicting Academic Achievement of Letran FreshmenDocument14 pagesAcademic Motivation and Self-Regulated Learning in Predicting Academic Achievement of Letran FreshmenRovie SazNo ratings yet
- Math562TB 06F PDFDocument701 pagesMath562TB 06F PDFalcava219151No ratings yet
- Durbin Watson TestDocument6 pagesDurbin Watson TestTrung VũNo ratings yet
- Aa 9Document50 pagesAa 9mrizalpahleviNo ratings yet
- The Correlation Between Introvert-Extrovert Personality and Satisfactory of Using Telemedicine ServiceDocument5 pagesThe Correlation Between Introvert-Extrovert Personality and Satisfactory of Using Telemedicine ServiceIJAR JOURNALNo ratings yet
- Strategic Planning 1195238439599640 2Document42 pagesStrategic Planning 1195238439599640 2earl58100% (5)
- Noelle Neumann 1974Document9 pagesNoelle Neumann 1974Nicolas FerreiraNo ratings yet
- Statistical Model ValidationDocument3 pagesStatistical Model ValidationRicardo AqpNo ratings yet
- Tribhuvan University Faculty of Management Office of The Dean 2011Document2 pagesTribhuvan University Faculty of Management Office of The Dean 2011mamannish7902No ratings yet
- The Site Location Plan ShouldDocument2 pagesThe Site Location Plan ShouldalyaninazNo ratings yet
- Wangel, J. Exploring Social Structure and Agency in Backcasting StudiesDocument11 pagesWangel, J. Exploring Social Structure and Agency in Backcasting StudiesBtc CryptoNo ratings yet
- Carl Friedrich Gauss - Life and AccomplishmentsDocument8 pagesCarl Friedrich Gauss - Life and AccomplishmentsempezardcNo ratings yet
- Underutilized Tool of Project Management Emotional IntelligenceDocument7 pagesUnderutilized Tool of Project Management Emotional IntelligencehumandudecNo ratings yet
- Statistics: Introduction: Prepared byDocument30 pagesStatistics: Introduction: Prepared bySam VeraNo ratings yet
- Bertrand Loison - An Innovative Data StrategyDocument35 pagesBertrand Loison - An Innovative Data StrategyAmit JainNo ratings yet
- Freshwater Fish Fauna in Watersheds of MT Makiling PDFDocument12 pagesFreshwater Fish Fauna in Watersheds of MT Makiling PDFBob UrbandubNo ratings yet
- Readability of Igbo Language Textbook in Use in Nigerian Secondary SchoolsDocument6 pagesReadability of Igbo Language Textbook in Use in Nigerian Secondary SchoolsJohn ChideraNo ratings yet
- Conventional Views of ReliabilityDocument43 pagesConventional Views of ReliabilityCART11No ratings yet