Download as ppt, pdf, or txt
You might also like
- Valve Abbreviations (MSS)Document1 pageValve Abbreviations (MSS)MeanRat100% (1)
- All Caterpillar Tappet ChartDocument1 pageAll Caterpillar Tappet ChartMd Nazrul75% (4)
- Chapter Six 6A ICDocument30 pagesChapter Six 6A ICRobera GetachewNo ratings yet
- Image Compression (Chapter 8) : CS474/674 - Prof. BebisDocument128 pagesImage Compression (Chapter 8) : CS474/674 - Prof. Bebissrc0108No ratings yet
- ImageCompression-UNIT-V-students MaterialDocument88 pagesImageCompression-UNIT-V-students MaterialHarika JangamNo ratings yet
- Unit IVDocument97 pagesUnit IVsarayu2804No ratings yet
- Compression IIDocument51 pagesCompression IIJagadeesh NaniNo ratings yet
- Image CompressionDocument133 pagesImage CompressionDeebika KaliyaperumalNo ratings yet
- Image Compression: CS474/674 - Prof. BebisDocument110 pagesImage Compression: CS474/674 - Prof. BebisYaksha YeshNo ratings yet
- Chapter 8-Image CompressionDocument61 pagesChapter 8-Image CompressionAshish GauravNo ratings yet
- Image CompressionDocument111 pagesImage CompressionKuldeep MankadNo ratings yet
- Why Needed?: Without Compression, These Applications Would Not Be FeasibleDocument11 pagesWhy Needed?: Without Compression, These Applications Would Not Be Feasiblesmile00972No ratings yet
- FALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-IDocument33 pagesFALLSEM2022-23 CSE4019 ETH VL2022230104728 2022-10-19 Reference-Material-ISRISHTI ACHARYYA 20BCE2561No ratings yet
- DIP S8ECE MODULE5 Part1Document49 pagesDIP S8ECE MODULE5 Part1Neeraja JohnNo ratings yet
- DIP Lecture Note - Image CompressionDocument23 pagesDIP Lecture Note - Image Compressiondeeparahul2022No ratings yet
- Dip 4 Unit NotesDocument10 pagesDip 4 Unit NotesMichael MariamNo ratings yet
- 3.multimedia Compression AlgorithmsDocument23 pages3.multimedia Compression Algorithmsaishu sillNo ratings yet
- 10b ImageCompression PDFDocument54 pages10b ImageCompression PDFmanasiNo ratings yet
- Image CompressionDocument107 pagesImage CompressionKiran KumarNo ratings yet
- CHP - 10 - Image Compression - Error Free and Lossy Compression MinDocument20 pagesCHP - 10 - Image Compression - Error Free and Lossy Compression Mindetex59086No ratings yet
- Image Compression (Chapter 8) : CS474/674 - Prof. BebisDocument75 pagesImage Compression (Chapter 8) : CS474/674 - Prof. BebisKoushik SupercalifragilisticNo ratings yet
- Img CompressionDocument15 pagesImg CompressionchinthaladhanalaxmiNo ratings yet
- Chapter - 5 Data CompressionDocument8 pagesChapter - 5 Data CompressionsiddharthaNo ratings yet
- Image CompressionDocument113 pagesImage Compressionmrunal.gaikwadNo ratings yet
- Data CompressionDocument28 pagesData CompressionKimNo ratings yet
- Module 5-ImgDocument14 pagesModule 5-ImgDEVID ROYNo ratings yet
- Image CompressionDocument28 pagesImage Compressionvijay9994No ratings yet
- 13imagecompression 120321055027 Phpapp02Document54 pages13imagecompression 120321055027 Phpapp02Tripathi VinaNo ratings yet
- Chapter08 1Document70 pagesChapter08 1Jangwoo YongNo ratings yet
- What Is The Need For Image Compression?Document38 pagesWhat Is The Need For Image Compression?rajeevrajkumarNo ratings yet
- Chapter 10 CompressionDocument66 pagesChapter 10 CompressionSandhya PandeyNo ratings yet
- What Is The Difference Between 2D and 3DDocument6 pagesWhat Is The Difference Between 2D and 3DAnthony Lawrence50% (2)
- 5 Data Compression IoenotesDocument47 pages5 Data Compression IoenotesNihal SharmaNo ratings yet
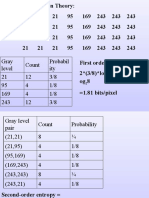
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Document51 pagesGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaNo ratings yet
- Define Psychovisual RedundancyDocument3 pagesDefine Psychovisual RedundancyKhalandar BashaNo ratings yet
- IP Unit 5 NotesDocument97 pagesIP Unit 5 Noteskartik guptaNo ratings yet
- Chapter 3 Multimedia Data CompressionDocument23 pagesChapter 3 Multimedia Data CompressionKalya YbsufkadNo ratings yet
- Entropy: A 00 A 01 A 10 A 11Document22 pagesEntropy: A 00 A 01 A 10 A 11Darshan ShahNo ratings yet
- Image Processing and Compression Techniques: Digitization Includes Sampling of Image and Quantization of Sampled ValuesDocument14 pagesImage Processing and Compression Techniques: Digitization Includes Sampling of Image and Quantization of Sampled ValuesSonali JamwalNo ratings yet
- CompressionDocument66 pagesCompressionSai sarathNo ratings yet
- Analysis and Comparison of Algorithms For Lossless Data CompressionDocument8 pagesAnalysis and Comparison of Algorithms For Lossless Data CompressionRachel AvengerNo ratings yet
- Assignment - Digital CommunicationDocument6 pagesAssignment - Digital CommunicationnetsanetNo ratings yet
- 09 CM0340 Basic Compression AlgorithmsDocument73 pages09 CM0340 Basic Compression AlgorithmsShobhit JainNo ratings yet
- Compression and Decompression TechniquesDocument68 pagesCompression and Decompression TechniquesVarun JainNo ratings yet
- Data CompressionDocument22 pagesData CompressionPrachi TrehanNo ratings yet
- Huffman Coding PaperDocument3 pagesHuffman Coding Paperrohith4991No ratings yet
- 06 Image CompresssionDocument49 pages06 Image CompresssionAnonymous 3j15irkNo ratings yet
- Unit 5 - Data CompressionDocument46 pagesUnit 5 - Data CompressionNezuko KamadoNo ratings yet
- Image CompressionDocument114 pagesImage CompressionDEVID ROYNo ratings yet
- 3 Vol 15 No 1Document6 pages3 Vol 15 No 1alkesh.engNo ratings yet
- Image CompressionDocument50 pagesImage CompressionVipin SinghNo ratings yet
- Difference Between Lossless Compression and Lossy CompressionDocument15 pagesDifference Between Lossless Compression and Lossy CompressionraviNo ratings yet
- Multimedia System: Chapter Eight: Multimedia Data CompressionDocument29 pagesMultimedia System: Chapter Eight: Multimedia Data Compressionsolo IvorNo ratings yet
- Niharika - OkDocument6 pagesNiharika - OkANILNo ratings yet
- Image CompressionDocument126 pagesImage CompressionGeethabaalanNo ratings yet
- Image CompressionDocument5 pagesImage Compressionamt12202No ratings yet
- Compression Using Huffman CodingDocument9 pagesCompression Using Huffman CodingSameer SharmaNo ratings yet
- DIP S8ECE MODULE5 Part2.2Document16 pagesDIP S8ECE MODULE5 Part2.2Neeraja JohnNo ratings yet
- Image Compression: Efficient Techniques for Visual Data OptimizationFrom EverandImage Compression: Efficient Techniques for Visual Data OptimizationNo ratings yet
- Vector Graphics Editor: Empowering Visual Creation with Advanced AlgorithmsFrom EverandVector Graphics Editor: Empowering Visual Creation with Advanced AlgorithmsNo ratings yet
- Raster Graphics Editor: Transforming Visual Realities: Mastering Raster Graphics Editors in Computer VisionFrom EverandRaster Graphics Editor: Transforming Visual Realities: Mastering Raster Graphics Editors in Computer VisionNo ratings yet
- Color Profile: Exploring Visual Perception and Analysis in Computer VisionFrom EverandColor Profile: Exploring Visual Perception and Analysis in Computer VisionNo ratings yet
- El DWG 016 Grounding LayoutDocument1 pageEl DWG 016 Grounding LayoutSumit TyagiNo ratings yet
- All in OneDocument12 pagesAll in OneX800XLNo ratings yet
- 3614 RS&Document998 pages3614 RS&Francisco CruzNo ratings yet
- Portico Design 1Document5 pagesPortico Design 1Asr FlowerNo ratings yet
- Slack AdjusterDocument2 pagesSlack AdjusterMathappan SNo ratings yet
- Solutions Chapter6 PDFDocument21 pagesSolutions Chapter6 PDFAnonymous LNtXoE9fgu0% (1)
- ETS 0071 Am 1Document17 pagesETS 0071 Am 1AnthonyNo ratings yet
- Eg Unit 5 QPDocument3 pagesEg Unit 5 QPMICHEL RAJ MechNo ratings yet
- Calibration Procedure For An Inertial Measurement Unit Using A 6-Degree-of-Freedom HexapodDocument6 pagesCalibration Procedure For An Inertial Measurement Unit Using A 6-Degree-of-Freedom HexapodfitomenaNo ratings yet
- SDM630MV CT Modbus Manual - GoodMeasure StoreDocument21 pagesSDM630MV CT Modbus Manual - GoodMeasure StoreKunanon JaitrongNo ratings yet
- Rectangular Break Line: 1. Purpose and DescriptionDocument5 pagesRectangular Break Line: 1. Purpose and DescriptionNico InfanteNo ratings yet
- GROWELS 101Document22 pagesGROWELS 101Ayush SawantNo ratings yet
- Natural Gas Homework2Document42 pagesNatural Gas Homework2Khanz KhanNo ratings yet
- (cm3) (MM) (MM) (KG) (°C) : Compressor ApplicationDocument3 pages(cm3) (MM) (MM) (KG) (°C) : Compressor ApplicationAmira Ben AmaraNo ratings yet
- Manual Usuario QTDDocument114 pagesManual Usuario QTDBrandy Nelson Zavaleta RodriguezNo ratings yet
- 9500-30 20180101 PartsSpecsDocument131 pages9500-30 20180101 PartsSpecsLê Phan Đồng HưngNo ratings yet
- Assignment #2 SolutionDocument9 pagesAssignment #2 SolutionSaqib IrshadNo ratings yet
- Borland C++ Version 4.0 Users Guide Oct93 PDFDocument462 pagesBorland C++ Version 4.0 Users Guide Oct93 PDFgustavoutpzaNo ratings yet
- HS2Document5 pagesHS2rock_musicNo ratings yet
- Industries in ChakanDocument3 pagesIndustries in ChakanMayu SKNo ratings yet
- Lab 4 WindTunnel Cylinder HandoutDocument7 pagesLab 4 WindTunnel Cylinder HandoutSteelcoverNo ratings yet
- Cma CGM Containers: Choosing The Right Equipment To Ship Your CargoDocument9 pagesCma CGM Containers: Choosing The Right Equipment To Ship Your CargoAmitrajeet kumarNo ratings yet
- ServiceNow Geneva Release Notes 8-30-2016Document5 pagesServiceNow Geneva Release Notes 8-30-2016Abhishek MishraNo ratings yet
- ENGLISHDocument13 pagesENGLISHpierocarnelociNo ratings yet
- 3.4 - Burning in A KilnDocument4 pages3.4 - Burning in A KilnIrshad Hussain100% (1)
- Lightning Protection Using Lfa-M-MyDocument16 pagesLightning Protection Using Lfa-M-MySusmita Panda71% (7)
- RAYCHEM - EPKT Terminations: Termination Systems For Polymeric and MIND Paper Insulated Cables From 7.2kV Up To 36kVDocument1 pageRAYCHEM - EPKT Terminations: Termination Systems For Polymeric and MIND Paper Insulated Cables From 7.2kV Up To 36kVStephen BridgesNo ratings yet
- Aiptek CamcorderDocument36 pagesAiptek CamcorderIsaac Musiwa BandaNo ratings yet