Download as ppt, pdf, or txt
You might also like
- Pre Order TraversalDocument17 pagesPre Order TraversalJunaid khanNo ratings yet
- Presentation On Plant Disease Identification Using MatlabDocument20 pagesPresentation On Plant Disease Identification Using MatlabSayantan Banerjee100% (1)
- Clustering, A Tool To Analyze Data PointsDocument61 pagesClustering, A Tool To Analyze Data PointssukhvindersNo ratings yet
- Week 04 Lecture MaterialDocument52 pagesWeek 04 Lecture MaterialMeer HassanNo ratings yet
- Lect13A-Cluster Analysis-IDocument38 pagesLect13A-Cluster Analysis-I6537UTKARSH RAGHUVANSHINo ratings yet
- Introduction To Data Science Unsupervised Learning: CS 194 Fall 2015 John CannyDocument54 pagesIntroduction To Data Science Unsupervised Learning: CS 194 Fall 2015 John CannyPedro Jesús García RamosNo ratings yet
- Lecture 12&13Document89 pagesLecture 12&13QUANG ANH B18DCCN034 PHẠMNo ratings yet
- DtreesDocument43 pagesDtreesDuy TNo ratings yet
- K-Nearest Neighbour (KNN)Document14 pagesK-Nearest Neighbour (KNN)Muhammad HaroonNo ratings yet
- L5 TextClassification UpdatedDocument179 pagesL5 TextClassification UpdatedIke S. MaNo ratings yet
- Data Mining CH - 5Document18 pagesData Mining CH - 5Hasset Tiss Abay GenjiNo ratings yet
- Viden Io Data Analytics Clustering KmeansDocument32 pagesViden Io Data Analytics Clustering KmeansRam ChanduNo ratings yet
- What Is Cluster Analysis?Document24 pagesWhat Is Cluster Analysis?rohit7853No ratings yet
- Chapter 5 ClusteringDocument40 pagesChapter 5 ClusteringMohamedsultan AwolNo ratings yet
- Metric-Based Classifiers: Nuno Vasconcelos (Ken Kreutz-Delgado)Document32 pagesMetric-Based Classifiers: Nuno Vasconcelos (Ken Kreutz-Delgado)Manu VegaNo ratings yet
- Lazy Learners Unit 2Document26 pagesLazy Learners Unit 2ManshiNo ratings yet
- What Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDocument51 pagesWhat Is Cluster Analysis?: - Cluster: A Collection of Data Objectspopat vishalNo ratings yet
- Modern Machine Learning in PythonDocument50 pagesModern Machine Learning in PythonMadhukar SinghNo ratings yet
- Lecture 1 Introduction-2Document20 pagesLecture 1 Introduction-2LIU HengxuNo ratings yet
- DM ClusteringDocument51 pagesDM ClusteringAlic McwanNo ratings yet
- Lecture 8-9 - ClusteringDocument43 pagesLecture 8-9 - ClusteringjohndeuterokNo ratings yet
- Accelerated Data Science Introduction To Machine Learning AlgorithmsDocument37 pagesAccelerated Data Science Introduction To Machine Learning AlgorithmssanketjaiswalNo ratings yet
- Slides Courtesy: Ling Chen lchen@L3S.deDocument42 pagesSlides Courtesy: Ling Chen lchen@L3S.defero_sher22No ratings yet
- 9.54 Class 13: Unsupervised LearningDocument54 pages9.54 Class 13: Unsupervised LearningGrantMwakipundaNo ratings yet
- Pattern Recognition 14Document46 pagesPattern Recognition 1416-shivani shaw-csbsNo ratings yet
- 02 - ClusteringDocument43 pages02 - Clusteringعبد الحميد عمرو عبد الحميد فرغلى هلالىNo ratings yet
- 09 ClassificationPCADocument80 pages09 ClassificationPCAShubhendu KarmakarNo ratings yet
- Reducing Computational Cost: - Nearest-Neighbors Has O (N) ComplexityDocument20 pagesReducing Computational Cost: - Nearest-Neighbors Has O (N) ComplexitySid NaikNo ratings yet
- Feature Engineering HandoutDocument33 pagesFeature Engineering HandoutTanoy DewanjeeNo ratings yet
- Data Structures in Java: Session 7 Instructor: Bert HuangDocument19 pagesData Structures in Java: Session 7 Instructor: Bert HuangscribdeerNo ratings yet
- RO47002 - Lecture 2B - ML Formalized - Part2Document8 pagesRO47002 - Lecture 2B - ML Formalized - Part2Haia Al SharifNo ratings yet
- Clustering NGDocument83 pagesClustering NGChaitanya BalaniNo ratings yet
- 20180723161729D4730 - Pert18 - K-Nearest NeighborDocument22 pages20180723161729D4730 - Pert18 - K-Nearest NeighborJihan NabilaNo ratings yet
- CS 343: Artificial Intelligence Machine Learning: Raymond J. MooneyDocument35 pagesCS 343: Artificial Intelligence Machine Learning: Raymond J. MooneyMohanad KadhimNo ratings yet
- Cours2 MLDocument21 pagesCours2 MLlaribiamal24No ratings yet
- Data Mining 1Document56 pagesData Mining 1SidharthNo ratings yet
- GVC-432 Ref: Donald Hearn & M. Pauline Baker ,: Lecture - 4Document36 pagesGVC-432 Ref: Donald Hearn & M. Pauline Baker ,: Lecture - 4Akshat SapraNo ratings yet
- Clustering K-MeansDocument28 pagesClustering K-MeansFaysal AhammedNo ratings yet
- Data Mining Lecture 10B: ClassificationDocument62 pagesData Mining Lecture 10B: ClassificationArul Kumar VenugopalNo ratings yet
- ML Co4 Session 29Document36 pagesML Co4 Session 29Shylandra BhanuNo ratings yet
- Lect 4Document34 pagesLect 4yoursweetseptemberNo ratings yet
- Handwritten Digit Recognition: Jitendra MalikDocument55 pagesHandwritten Digit Recognition: Jitendra MalikSUMIT DATTANo ratings yet
- What Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDocument9 pagesWhat Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsIrum FatimaNo ratings yet
- ClusteringDocument47 pagesClusteringسارة شعيرNo ratings yet
- ML DecisionTreesDocument46 pagesML DecisionTreespranati prasadNo ratings yet
- ESE Handouts 5 Cluster Analysis (Fall 2016)Document17 pagesESE Handouts 5 Cluster Analysis (Fall 2016)sayedNo ratings yet
- ML Unit 3Document83 pagesML Unit 3sanju.25qtNo ratings yet
- Lec 2Document31 pagesLec 2asasdNo ratings yet
- ISC Unit II Topic-6Document29 pagesISC Unit II Topic-6Bipin BhadraNo ratings yet
- KNN and Bias Variance TradeoffDocument21 pagesKNN and Bias Variance Tradeoff21110289No ratings yet
- An Overview of Edward: A Probabilistic Programming System: Dustin Tran Columbia UniversityDocument34 pagesAn Overview of Edward: A Probabilistic Programming System: Dustin Tran Columbia UniversityStanislav SeNo ratings yet
- Discriminative and Generative Methods For Bags of Features: Zebra Non-ZebraDocument40 pagesDiscriminative and Generative Methods For Bags of Features: Zebra Non-ZebraramnbantunNo ratings yet
- Clustering AlgorithmDocument144 pagesClustering AlgorithmSohail AhmadNo ratings yet
- Instance Based LearningDocument20 pagesInstance Based Learningd sandeepNo ratings yet
- Pattern RecognitionDocument52 pagesPattern RecognitionWaseem QassabNo ratings yet
- Decision TreesDocument37 pagesDecision TreesDennis AngelNo ratings yet
- Machine Learning OverviewDocument54 pagesMachine Learning OverviewRamakrishnaRao SoogooriNo ratings yet
- Local Features and Bag of Words ModelsDocument60 pagesLocal Features and Bag of Words ModelsescadoulaNo ratings yet
- Designing and Conducting Ethnographic Research: An IntroductionFrom EverandDesigning and Conducting Ethnographic Research: An IntroductionNo ratings yet
- An Iot Based Smart Energy Management of Hvac SystemDocument9 pagesAn Iot Based Smart Energy Management of Hvac SystemRagini GuptaNo ratings yet
- Code-Based Testing of Extended Finite State Machine Models - PPT - v4Document36 pagesCode-Based Testing of Extended Finite State Machine Models - PPT - v4Ragini GuptaNo ratings yet
- Camera PresentationDocument11 pagesCamera PresentationRagini GuptaNo ratings yet
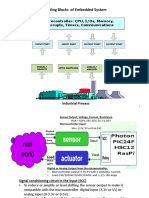
- Basic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsDocument23 pagesBasic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsRagini GuptaNo ratings yet
- 03 Timers Slides PDFDocument69 pages03 Timers Slides PDFRagini GuptaNo ratings yet
- 7-Raspberry Pi Camera Interface-Final PDFDocument27 pages7-Raspberry Pi Camera Interface-Final PDFRagini Gupta100% (1)
- 02 PIC ADC Final PDFDocument68 pages02 PIC ADC Final PDFRagini GuptaNo ratings yet
- FSM Testing 1Document45 pagesFSM Testing 1Ragini GuptaNo ratings yet
- AR-Raspberry Pi Slides CompleteDocument21 pagesAR-Raspberry Pi Slides CompleteRagini GuptaNo ratings yet
- Running Head: Are Cell Phones Modern-Day Drugs Amoung Students? 1Document13 pagesRunning Head: Are Cell Phones Modern-Day Drugs Amoung Students? 1Ragini GuptaNo ratings yet
- Running Head: Cell Phones Drugs Amoung Students 1Document12 pagesRunning Head: Cell Phones Drugs Amoung Students 1Ragini GuptaNo ratings yet
- Solution 1 - DFADocument5 pagesSolution 1 - DFARagini GuptaNo ratings yet
- DSP Lab Manual Final FinalDocument89 pagesDSP Lab Manual Final FinalTaskeen JunaidNo ratings yet
- RTV 4 ManualDocument128 pagesRTV 4 ManualkloudNo ratings yet
- 15.053 Tuesday, May 1: Branch and BoundDocument73 pages15.053 Tuesday, May 1: Branch and BoundEhsan SpencerNo ratings yet
- Trapezoidal Rule of IntegrationDocument16 pagesTrapezoidal Rule of Integrationpara sa projectNo ratings yet
- Yule-Walker Equations: Practical Time Series Analysis Thistleton and SadigovDocument12 pagesYule-Walker Equations: Practical Time Series Analysis Thistleton and Sadigovsirj0_hnNo ratings yet
- Interconnection of LTI Systems: Transmittance. The Transmittance Relates The Incoming and Outgoing Signals As IndicatedDocument16 pagesInterconnection of LTI Systems: Transmittance. The Transmittance Relates The Incoming and Outgoing Signals As IndicatedJohn David Meer RamosNo ratings yet
- Discrete Mathematics: TreesDocument60 pagesDiscrete Mathematics: TreesAiman AfzamNo ratings yet
- Sieve of Atkin: AlgorithmDocument4 pagesSieve of Atkin: AlgorithmNick DimNo ratings yet
- Multi Modal Hate Speech Detection Using Machine LearningDocument5 pagesMulti Modal Hate Speech Detection Using Machine LearningDejene Dagime100% (1)
- DSP HandoutsDocument11 pagesDSP HandoutsG A E SATISH KUMARNo ratings yet
- Ps1 Solution (VERY IMP)Document6 pagesPs1 Solution (VERY IMP)Omega ManNo ratings yet
- Chapter 2 Linear Signal ModelsDocument40 pagesChapter 2 Linear Signal ModelsSisayNo ratings yet
- Examples: Using Matlab For Solutions: Transfer It To The Partial Fraction Form)Document34 pagesExamples: Using Matlab For Solutions: Transfer It To The Partial Fraction Form)Adel ElnabawiNo ratings yet
- Greedy Layerwise LearningDocument39 pagesGreedy Layerwise LearningPRATIK GANGAPURWALANo ratings yet
- Matlab DSPDocument0 pagesMatlab DSPNaim Maktumbi NesaragiNo ratings yet
- SRM VALLIAMMAI 1924103-Machine-LearningDocument10 pagesSRM VALLIAMMAI 1924103-Machine-LearningDr. Jayanthi V.S.100% (1)
- Ch.11 Graphs: Data Structures: A Pseudocode Approach With CDocument65 pagesCh.11 Graphs: Data Structures: A Pseudocode Approach With CAjayaHSNo ratings yet
- Advanced Algorithms - Cse-CsDocument2 pagesAdvanced Algorithms - Cse-Csaarthi devNo ratings yet
- Floyd Warshall AlgorithmDocument19 pagesFloyd Warshall AlgorithmSamaksh JhalaniNo ratings yet
- Adaptive Delta ModulationDocument15 pagesAdaptive Delta ModulationVinita DahiyaNo ratings yet
- String Programming Interview QuestionDocument9 pagesString Programming Interview QuestionRajiv NayanNo ratings yet
- SS 1 (Autosaved)Document14 pagesSS 1 (Autosaved)SenthilNo ratings yet
- ACT6100 A2020 Sup 12Document37 pagesACT6100 A2020 Sup 12lebesguesNo ratings yet
- Channel Estimation - MATLAB & Simulink PDFDocument8 pagesChannel Estimation - MATLAB & Simulink PDFMukesh KumarNo ratings yet
- SyllabusDocument3 pagesSyllabusKARTHISREE SNo ratings yet
- Adc and Dac Lec 2 (1st)Document10 pagesAdc and Dac Lec 2 (1st)Pahala SamosirNo ratings yet
- Image Quality AssessmentDocument35 pagesImage Quality AssessmentMichel Alves Dos Santos100% (1)
- Machine Learning Book PDFDocument260 pagesMachine Learning Book PDFShowkat RashidNo ratings yet