Download as ppt, pdf, or txt
You might also like
- Ring Blank Lengths PDFDocument2 pagesRing Blank Lengths PDFSotiris AslanopoulosNo ratings yet
- Ring Blank LengthsDocument2 pagesRing Blank LengthsSotiris Aslanopoulos100% (1)
- BI MCQsDocument20 pagesBI MCQsKim Jhon50% (2)
- Big Data AnalyticsDocument414 pagesBig Data Analyticsud100% (19)
- Te Vas Milonga - Abel FleuryDocument2 pagesTe Vas Milonga - Abel FleuryraulNo ratings yet
- M16A2 TargetDocument1 pageM16A2 Targetdeolexrex100% (6)
- Dbscan: Presented By: Garrett PoppeDocument22 pagesDbscan: Presented By: Garrett PoppeShivani ChandelNo ratings yet
- Clustters AlgorithmDocument20 pagesClustters AlgorithmbhaskarNo ratings yet
- Colic BabyDocument109 pagesColic BabyVivek AryaNo ratings yet
- Cluster Analysis - Approach 1Document28 pagesCluster Analysis - Approach 1Charan NaiduNo ratings yet
- ClusteringDocument61 pagesClusteringRashul ChutaniNo ratings yet
- Clustering Partitioning MethodsDocument20 pagesClustering Partitioning Methods2K19/BMBA/13 RITIKANo ratings yet
- Lect 10 DMDocument36 pagesLect 10 DMSaba TariqNo ratings yet
- DM Lec 14 Clustering-II - KmedoidDocument15 pagesDM Lec 14 Clustering-II - KmedoidJAMEEL AHMADNo ratings yet
- ClusteringDocument45 pagesClusteringsujan.cseruNo ratings yet
- Module5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Document21 pagesModule5 - Outlier - Analysis: Reference: "Data Mining The Text Book", Charu C. Aggarwal, Springer, 2015. (Chapters 8)Rohith RohNo ratings yet
- 4.3 K-MedoidsDocument31 pages4.3 K-MedoidsPynshngainNo ratings yet
- ClusterDocument20 pagesClustersondaravalliNo ratings yet
- CT075!3!2 DTM Topic 10 Cluster AnalysisDocument21 pagesCT075!3!2 DTM Topic 10 Cluster Analysiskishanselvarajah80No ratings yet
- Lecture 13Document45 pagesLecture 13zafar.phdcs82No ratings yet
- Kindergarten Workheet NoDocument1 pageKindergarten Workheet NoAnniemah UsmanNo ratings yet
- Depreciation SchedulesDocument1 pageDepreciation SchedulesMary100% (1)
- 1 SubtractionDocument1 page1 SubtractionNaNa NaNaNo ratings yet
- 8.hierarchical AGNES DIANADocument46 pages8.hierarchical AGNES DIANAShreyas ParajNo ratings yet
- Heap StructureDocument28 pagesHeap Structureritz meshNo ratings yet
- Lecture5 - Clustering (K Means and K Medoids)Document36 pagesLecture5 - Clustering (K Means and K Medoids)Khaledun NaharNo ratings yet
- Lesson 11 - y MX C (From A Graph) 1Document1 pageLesson 11 - y MX C (From A Graph) 1Mohd Farhan AnsariNo ratings yet
- Child Stuttering Severity Chart v2 Dec 2022Document1 pageChild Stuttering Severity Chart v2 Dec 2022Sana AlviNo ratings yet
- Self Esteem Basic SheetDocument1 pageSelf Esteem Basic SheetLoNo ratings yet
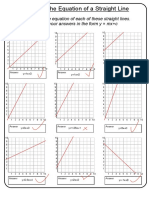
- Finding The Equation of A Straight LineDocument1 pageFinding The Equation of A Straight Linethe tri namNo ratings yet
- Warm Up Exercises by Steve Vai: Standard TuningDocument5 pagesWarm Up Exercises by Steve Vai: Standard TuningPauloRomaoZorbaNo ratings yet
- 2 - More or LessDocument1 page2 - More or LessYuyu Dewi AnggreiniNo ratings yet
- C Major Scale All PositionsDocument2 pagesC Major Scale All PositionsjosebussoNo ratings yet
- Presentación Transporte Parte 3 2022-1Document15 pagesPresentación Transporte Parte 3 2022-1Carlos Felipe AragonNo ratings yet
- Ska-P Cruz Oro y SangreDocument1 pageSka-P Cruz Oro y SangreErick Jair Trujillo RamírezNo ratings yet
- Fallen Down (Reprise) - Undertale, Ukulele.Document6 pagesFallen Down (Reprise) - Undertale, Ukulele.Miguel A. C. C.No ratings yet
- Boiler EquationsDocument155 pagesBoiler Equationspulakjaiswal85No ratings yet
- Lecture 3 - Herirachical MethodsDocument16 pagesLecture 3 - Herirachical MethodsManikandan MNo ratings yet
- Asbuild Drawing Ipal TinondoDocument12 pagesAsbuild Drawing Ipal TinondoVerdy SaputraNo ratings yet
- TimeDocument1 pageTimegarima somaniNo ratings yet
- What Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsDocument77 pagesWhat Is Cluster Analysis?: - Cluster: A Collection of Data ObjectsChristopherNo ratings yet
- ClusteringDocument125 pagesClusteringFariya AfrinNo ratings yet
- Ludwig The Holy BladeDocument3 pagesLudwig The Holy BladeGabriel PortoNo ratings yet
- Wks. 2.2 - Standard Form of Quad EqDocument2 pagesWks. 2.2 - Standard Form of Quad EqSusie GreenNo ratings yet
- Measure The Following Objects:: ExampleDocument5 pagesMeasure The Following Objects:: Examplemomztutelage4182No ratings yet
- Asbuild Drawing Ipal LalolaeDocument12 pagesAsbuild Drawing Ipal LalolaeVerdy SaputraNo ratings yet
- Heavy Metal Guitar School - Lesson For Bands III2Document2 pagesHeavy Metal Guitar School - Lesson For Bands III2David Ramírez B.No ratings yet
- Wasting Love Benato PDFDocument7 pagesWasting Love Benato PDFrafael benatoNo ratings yet
- Caprice No 24 PaganiniDocument17 pagesCaprice No 24 PaganiniPick N ClickNo ratings yet
- Lecture 2 - Clustering MethodsDocument19 pagesLecture 2 - Clustering MethodsManikandan MNo ratings yet
- 2016 CalendarDocument1 page2016 CalendarAsegedech BirhanuNo ratings yet
- EF4E Beg Comm PracEng3Document1 pageEF4E Beg Comm PracEng3Bárbara MontenegroNo ratings yet
- Telling Time 1 Minute Increment 1Document2 pagesTelling Time 1 Minute Increment 1amthedeavilNo ratings yet
- 5 Minutes Increment 1Document2 pages5 Minutes Increment 1ailbhe96No ratings yet
- Weather Chart: LegendsDocument1 pageWeather Chart: LegendsIco MurayagNo ratings yet
- Partitura Warcry - RenacerDocument4 pagesPartitura Warcry - RenacerAntonio SanchezNo ratings yet
- Productivity Planner A3Document1 pageProductivity Planner A3Rohit SharmaNo ratings yet
- C Major ScaleDocument1 pageC Major ScaleTan SamNo ratings yet
- Indian Premier League Auction House 2020Document7 pagesIndian Premier League Auction House 2020kavanshahdiplomathonNo ratings yet
- Caminhos Harmonicos - Do Menor: CM CM G7Document7 pagesCaminhos Harmonicos - Do Menor: CM CM G7Raphael Novos RumosNo ratings yet
- Te Rs A PP: BH - Notes: DWMDocument28 pagesTe Rs A PP: BH - Notes: DWMroham kamalNo ratings yet
- An Application of Cluster Analysis To HIV/AIDS Prevalence in NigeriaDocument42 pagesAn Application of Cluster Analysis To HIV/AIDS Prevalence in NigeriaRaheem K KolaNo ratings yet
- RAJENDRAN - Zack.2019 Insight On Strategic Air TaxiDocument36 pagesRAJENDRAN - Zack.2019 Insight On Strategic Air TaxiRaoniNo ratings yet
- A Customer Segmentation Approach in Commercial Banks: AIP Conference Proceedings October 2018Document10 pagesA Customer Segmentation Approach in Commercial Banks: AIP Conference Proceedings October 2018anand_kumar115No ratings yet
- Mit Data Science Machine Learning Program BrochureDocument17 pagesMit Data Science Machine Learning Program BrochureSai Aartie SharmaNo ratings yet
- Unsupervised Learning - ClusteringDocument19 pagesUnsupervised Learning - ClusteringSpandan Rout ms17a058No ratings yet
- Machine LearningDocument21 pagesMachine LearningRachit Joshi100% (1)
- ReportDocument24 pagesReportAbhishek palNo ratings yet
- Julia and MLDocument13 pagesJulia and MLaejaz_98No ratings yet
- A Brief Survey On Data Mining For Biological and Environmental Problems.Document46 pagesA Brief Survey On Data Mining For Biological and Environmental Problems.Harikrishnan ShunmugamNo ratings yet
- BDA Lab ManualDocument62 pagesBDA Lab ManualReyansh PerkinNo ratings yet
- What Is Machine LearningDocument9 pagesWhat Is Machine LearningranamzeeshanNo ratings yet
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (1)
- Normalized Clustering Algorithm Based On Mahalanobis DistanceDocument5 pagesNormalized Clustering Algorithm Based On Mahalanobis DistanceInternational Jpurnal Of Technical Research And ApplicationsNo ratings yet
- My Final FileDocument54 pagesMy Final Fileharshit gargNo ratings yet
- Virus-Mnist A Benchmark Malware DatasetDocument6 pagesVirus-Mnist A Benchmark Malware DatasetlarisszaNo ratings yet
- Lesson 6 - Unsupervised LearningDocument63 pagesLesson 6 - Unsupervised LearningOmid khosraviNo ratings yet
- GR 1Document12 pagesGR 1bc500No ratings yet
- K Means TutorialDocument8 pagesK Means TutorialhhhNo ratings yet
- Cluster Analysis ClusteringDocument6 pagesCluster Analysis Clustering17CSE97- VIKASHINI TPNo ratings yet
- Cluster AnalysisDocument77 pagesCluster AnalysisDennis Atygurasiwi KunarsitoNo ratings yet
- 1 s2.0 S1110866515000043 Main PDFDocument11 pages1 s2.0 S1110866515000043 Main PDFJayaprakash JayaramanNo ratings yet
- An Extended K-Means Cluster Head Selection Algorithm For Efficient Energy Consumption in Wireless Sensor NetworksDocument19 pagesAn Extended K-Means Cluster Head Selection Algorithm For Efficient Energy Consumption in Wireless Sensor NetworksAIRCC - IJNSANo ratings yet
- Clustering Techniques in ML: Submitted By: Pooja 16EJICS072Document26 pagesClustering Techniques in ML: Submitted By: Pooja 16EJICS072RITESH JANGIDNo ratings yet
- Spatial Machine Learning: New Opportunities For Regional ScienceDocument43 pagesSpatial Machine Learning: New Opportunities For Regional ScienceivanmrnNo ratings yet
- Lecture Slides For Introduction To Applied Linear Algebra: Vectors, Matrices, and Least SquaresDocument470 pagesLecture Slides For Introduction To Applied Linear Algebra: Vectors, Matrices, and Least SquaresMuhammad SadnoNo ratings yet
- Heart Attack Prediction Full DocumentDocument28 pagesHeart Attack Prediction Full Documentsonaiya software solutionsNo ratings yet
- Improving Arabic Document Clustering Using K-Means Algorithm and Particle Swarm OptimizationDocument7 pagesImproving Arabic Document Clustering Using K-Means Algorithm and Particle Swarm Optimizationوفاء عبد الرحمنNo ratings yet