Download as pptx, pdf, or txt
You might also like
- Your UNIX: The Ultimate Guide-Solutions To Exercises Solutions To ExercisesDocument1 pageYour UNIX: The Ultimate Guide-Solutions To Exercises Solutions To ExercisesSaroj Kumar RajakNo ratings yet
- Microcontroller MCQ QuizDocument5 pagesMicrocontroller MCQ QuizDeepika SharmaNo ratings yet
- Huawei ICT Competition 2019-2020 Preliminary Examination Outline - PAkDocument5 pagesHuawei ICT Competition 2019-2020 Preliminary Examination Outline - PAkHamad KhanNo ratings yet
- Module - 4 K Means ClusteringDocument20 pagesModule - 4 K Means ClusteringkNo ratings yet
- K Mean ClusteringDocument48 pagesK Mean ClusteringRexline S JNo ratings yet
- K Mean ClusteringDocument36 pagesK Mean ClusteringNavjot WadhwaNo ratings yet
- Subject: Digital Signal Processing (TE321) Practice Problem 2Document1 pageSubject: Digital Signal Processing (TE321) Practice Problem 2russ90No ratings yet
- Quality of Clustering: Clustering (K-Means Algorithm)Document4 pagesQuality of Clustering: Clustering (K-Means Algorithm)Sk Arif AhmedNo ratings yet
- BCSL33 AssignmentDocument14 pagesBCSL33 Assignmentsomeone someoneNo ratings yet
- Algo Tri FusionDocument4 pagesAlgo Tri FusionLionel OueiNo ratings yet
- Suggession of Machine LearningDocument6 pagesSuggession of Machine LearningParthasarathi HazraNo ratings yet
- Introduction To The Finite Element Method (FEM) : Dr. J. DeanDocument12 pagesIntroduction To The Finite Element Method (FEM) : Dr. J. Deanticoncoolz100% (1)
- Data Structures NotesDocument9 pagesData Structures NotesMohammed JeelanNo ratings yet
- K Mean Clustering 1Document26 pagesK Mean Clustering 1Nada AhmedNo ratings yet
- Quartiles (Grouped Data) : Example: SolutionDocument15 pagesQuartiles (Grouped Data) : Example: SolutionJustin Newrey LugasanNo ratings yet
- Owen Astrachan and Dee Ramm November 19, 1996Document11 pagesOwen Astrachan and Dee Ramm November 19, 1996Gobara DhanNo ratings yet
- Topic 4Document32 pagesTopic 4hmood966No ratings yet
- 2 D ElementsDocument160 pages2 D Elementseafz111No ratings yet
- ITE 2702 - CM Moratuwa UniversityDocument5 pagesITE 2702 - CM Moratuwa UniversityDilini Dakshika HerathNo ratings yet
- PROB STAT.4photoDocument11 pagesPROB STAT.4photojames_harrill1994_59No ratings yet
- Upper Bound Lower BoundDocument37 pagesUpper Bound Lower BoundArunabh NagNo ratings yet
- Autocorrelation SDocument25 pagesAutocorrelation SknmitraNo ratings yet
- 16 K Mean Clustring 1 18052023 095249am 08042024 093324amDocument20 pages16 K Mean Clustring 1 18052023 095249am 08042024 093324amMuneeba HussainNo ratings yet
- Excel Numerical IntegrationDocument9 pagesExcel Numerical IntegrationPrasad PantNo ratings yet
- data structures-ArraysDocument15 pagesdata structures-ArraysJesica D'cruzNo ratings yet
- DSA Assignment 1-SolutionsDocument10 pagesDSA Assignment 1-SolutionsChatianya ChaniyaraNo ratings yet
- Model Subiect Ex AmenDocument1 pageModel Subiect Ex AmenStefania BunaciuNo ratings yet
- Practice Sheet 1 - ArrayDocument18 pagesPractice Sheet 1 - Arrayshoeb.islam.hamimNo ratings yet
- Lecture 31Document5 pagesLecture 31arjunNo ratings yet
- Array: Muhammad IrfanDocument12 pagesArray: Muhammad IrfandangermanNo ratings yet
- K Mean ClusteringDocument27 pagesK Mean Clusteringashishamitav123No ratings yet
- You Only Live OnceDocument13 pagesYou Only Live OnceSaket AgarwalNo ratings yet
- K-Means: Step-By-Step ExampleDocument2 pagesK-Means: Step-By-Step ExampleamarpoonamNo ratings yet
- 2D Triangular ElementsarticleDocument19 pages2D Triangular ElementsarticleYasirBashirNo ratings yet
- VmdnhutrcDocument8 pagesVmdnhutrcAditya BajpaiNo ratings yet
- Truminds Software Solutions Previously Asked QuestionsDocument5 pagesTruminds Software Solutions Previously Asked QuestionsPhani BollaNo ratings yet
- DSANotesDocument30 pagesDSANotesShivangi AgrawalNo ratings yet
- MIS 637 Assignment 5 Sai SandeepDocument2 pagesMIS 637 Assignment 5 Sai SandeepJitin DammuNo ratings yet
- Exam1 s16 SolDocument10 pagesExam1 s16 SolVũ Quốc NgọcNo ratings yet
- CHAPTER-04 (Searching&sorting) 1Document32 pagesCHAPTER-04 (Searching&sorting) 1xx69dd69xxNo ratings yet
- Chapter 3 (Part 1) : The Fundamentals: Algorithms, The Integers & MatricesDocument46 pagesChapter 3 (Part 1) : The Fundamentals: Algorithms, The Integers & MatricesNurain AliNo ratings yet
- Key P1Document3 pagesKey P1James RobertNo ratings yet
- Experiment 8 Hydrogen SpectrumDocument4 pagesExperiment 8 Hydrogen SpectrumNadillia SahputraNo ratings yet
- 4540 Sample ReportDocument20 pages4540 Sample ReportalmodhafarNo ratings yet
- CORE - 14: Algorithm Design Techniques (Unit - 2)Document14 pagesCORE - 14: Algorithm Design Techniques (Unit - 2)Priyaranjan SorenNo ratings yet
- Average Case Analysis of Binary SearchDocument3 pagesAverage Case Analysis of Binary SearchkumaresanNo ratings yet
- Imran Rasool Bbe-1586Document9 pagesImran Rasool Bbe-1586M shahzaibNo ratings yet
- Medium Level Array PracticeDocument6 pagesMedium Level Array Practice131 70VIJAY JADHAVNo ratings yet
- Binary SearchDocument5 pagesBinary SearchUniversal CollegeNo ratings yet
- Lab 26Document1 pageLab 26RubickNo ratings yet
- Unit 5 - Sorting and HashingDocument47 pagesUnit 5 - Sorting and HashingIlesh ShahNo ratings yet
- Multidimensional ArraysDocument9 pagesMultidimensional Arraysnitish-bhardwaj-9810No ratings yet
- Prob 1Document4 pagesProb 1Ngọc Huyền NguyễnNo ratings yet
- "K Nearest and Furthest Points in M-Dimensional SpaceDocument3 pages"K Nearest and Furthest Points in M-Dimensional SpaceYeshwanth KumarNo ratings yet
- Ecient Neighbor Searching in Nonlinear Time Series AnalysisDocument20 pagesEcient Neighbor Searching in Nonlinear Time Series AnalysisСињор КнежевићNo ratings yet
- ANN Extraction RulesDocument5 pagesANN Extraction RulesjehadyamNo ratings yet
- Excel FFTDocument5 pagesExcel FFTCarlos AlasNo ratings yet
- MC0080 Analysis and Design of AlgorithmsDocument15 pagesMC0080 Analysis and Design of AlgorithmsGaurav Singh JantwalNo ratings yet
- Data Structures Using C++ RakeshDocument7 pagesData Structures Using C++ RakeshRakesh KumarNo ratings yet
- K Mean Clustering 1Document12 pagesK Mean Clustering 1HykaVirtasari100% (1)
- Department of Industrial & Systems Engineering and Center For Optimization and Combina-Torics, University of Florida, Gainesville, FL 32611, USADocument11 pagesDepartment of Industrial & Systems Engineering and Center For Optimization and Combina-Torics, University of Florida, Gainesville, FL 32611, USAAdityaSharmaNo ratings yet
- Matrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")From EverandMatrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Rating: 3 out of 5 stars3/5 (4)
- Practical Finite Element Modeling in Earth Science using MatlabFrom EverandPractical Finite Element Modeling in Earth Science using MatlabNo ratings yet
- Matrix OLS NYU NotesDocument14 pagesMatrix OLS NYU NotesAnonymous 2g4jKo5a7vNo ratings yet
- ProbablityDocument5 pagesProbablityAshirbad NayakNo ratings yet
- How To Read CSV File in Anaconda NavigatorDocument1 pageHow To Read CSV File in Anaconda NavigatorAshirbad NayakNo ratings yet
- Regarding IBM Analytics Courses in CourseraDocument1 pageRegarding IBM Analytics Courses in CourseraAshirbad NayakNo ratings yet
- TCS QuestionsDocument15 pagesTCS QuestionsAshirbad NayakNo ratings yet
- Interview AnswersDocument5 pagesInterview AnswersAshirbad NayakNo ratings yet
- Java & C++ InterviewDocument12 pagesJava & C++ InterviewAshirbad NayakNo ratings yet
- Satya Sourav Nayak - XIMBDocument2 pagesSatya Sourav Nayak - XIMBAshirbad NayakNo ratings yet
- Annada Shankar SahooDocument3 pagesAnnada Shankar SahooAshirbad NayakNo ratings yet
- Recruitment of Junior Management Trainee (Electrical) On Contractual BasisDocument10 pagesRecruitment of Junior Management Trainee (Electrical) On Contractual BasisAshirbad NayakNo ratings yet
- Recruitment of Management Trainees Through Computer Based Test CBT - 2022Document12 pagesRecruitment of Management Trainees Through Computer Based Test CBT - 2022Ashirbad NayakNo ratings yet
- SCA Assign 2Document5 pagesSCA Assign 2Ashirbad NayakNo ratings yet
- The MBA OathDocument1 pageThe MBA OathAshirbad NayakNo ratings yet
- Dishonesty in SportsDocument8 pagesDishonesty in SportsAshirbad NayakNo ratings yet
- cbhf2 NaDocument8 pagescbhf2 NaStefan CorjucNo ratings yet
- Aspen Plus Urea Synthesis Loop ModelDocument19 pagesAspen Plus Urea Synthesis Loop ModelMagdy SalehNo ratings yet
- PracticeProbs (5 - 27 - 07) - CMOS Analog ICs PDFDocument70 pagesPracticeProbs (5 - 27 - 07) - CMOS Analog ICs PDFmyluvahanNo ratings yet
- E-Terragridcom DIP Brochure GBDocument4 pagesE-Terragridcom DIP Brochure GBNeelakandan MasilamaniNo ratings yet
- Tank Design APIDocument63 pagesTank Design APIBSK entertainmentNo ratings yet
- (Komonov EtAL) Geochem Methods of ProspectingDocument412 pages(Komonov EtAL) Geochem Methods of Prospectingjavicol70No ratings yet
- Hyundai Molded / Cast Resin TransformerDocument16 pagesHyundai Molded / Cast Resin TransformerbadbenzationNo ratings yet
- Protective DevicesDocument23 pagesProtective DevicesRumana AliNo ratings yet
- Centrifugal Chiller - Fundamentals - Energy-ModelsDocument30 pagesCentrifugal Chiller - Fundamentals - Energy-ModelsPrashant100% (1)
- SN 1 Jul 2013 NTNU Wind Turbine Drivtrain CeSOSDocument8 pagesSN 1 Jul 2013 NTNU Wind Turbine Drivtrain CeSOSanteoprivatoNo ratings yet
- Os NotesDocument17 pagesOs NotesAshish KadamNo ratings yet
- UL - FM UF-MD-HC DESIGN - MANUAL - HFC-227 - Rv05Document54 pagesUL - FM UF-MD-HC DESIGN - MANUAL - HFC-227 - Rv05Ahmed ElbarbaryNo ratings yet
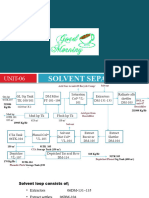
- Solvent Separation UNIT-06 - GOODDocument17 pagesSolvent Separation UNIT-06 - GOODAamir HasanNo ratings yet
- Commscope 6 PDFDocument2 pagesCommscope 6 PDFVũ VũNo ratings yet
- Bubba OscillatorDocument7 pagesBubba OscillatorUmairRashidNo ratings yet
- V Rep2Document37 pagesV Rep2ANANo ratings yet
- X21101 - ENGINEERING MATHEMATICS I Model QP 12.04.22Document3 pagesX21101 - ENGINEERING MATHEMATICS I Model QP 12.04.22Krishna PrasadNo ratings yet
- Multi-Junction Solar CellDocument18 pagesMulti-Junction Solar CellMukesh Jindal100% (1)
- CT S&P-Avr13-THGT-SélectionDocument78 pagesCT S&P-Avr13-THGT-Sélectionkasztakatika100% (1)
- Math (F4) - Straight Line 5.1Document33 pagesMath (F4) - Straight Line 5.1Roszelan MajidNo ratings yet
- YaccDocument12 pagesYaccGopi KomanduriNo ratings yet
- 4. VLF Hipot Tester-User Manual(按键款)Document9 pages4. VLF Hipot Tester-User Manual(按键款)Mạnh Nguyễn VănNo ratings yet
- CH 11 Lecture SlidesDocument44 pagesCH 11 Lecture SlidesUyên Trần NhưNo ratings yet
- Energies 11 00252 v3Document28 pagesEnergies 11 00252 v3caoap3847No ratings yet
- Personalized Movie Hybrid Recommendation Model Based On GRUDocument4 pagesPersonalized Movie Hybrid Recommendation Model Based On GRUMritunjay JhaNo ratings yet
- Remote-Field Testing (RFT)Document3 pagesRemote-Field Testing (RFT)shahgardezNo ratings yet
- PublicDocument10 pagesPublicGovardhan DigumurthiNo ratings yet