
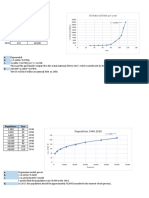
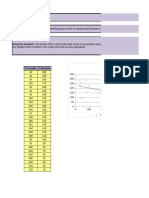
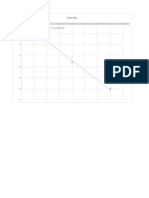
Simple Regression
Simple Regression
You might also like
- AnswerDocument7 pagesAnswerMohd Sharil100% (2)
- Algebra AnswersDocument43 pagesAlgebra AnswersPriya Tripathi79% (19)
- BS en 50600-3-1-2016Document52 pagesBS en 50600-3-1-2016YASNo ratings yet
- Project 5 - Exponential and Logarithmic ProjectDocument7 pagesProject 5 - Exponential and Logarithmic Projectapi-489129243No ratings yet
- Solved - Example 1 Revisit & Example 2 RecordingDocument5 pagesSolved - Example 1 Revisit & Example 2 RecordingMinzaNo ratings yet
- Project 5 PDFDocument3 pagesProject 5 PDFapi-509845050No ratings yet
- DA4675 CFA Level II SmartSheet 2020 PDFDocument10 pagesDA4675 CFA Level II SmartSheet 2020 PDFMabelita Flores100% (3)
- RegressionDocument46 pagesRegressionarpitNo ratings yet
- Session 12Document27 pagesSession 12PRIYADARSHI PANKAJNo ratings yet
- Problem Set 2 SolutionsDocument34 pagesProblem Set 2 SolutionsglavchevanasikNo ratings yet
- PTA TerrrrbaruDocument1 pagePTA TerrrrbaruTHT-BKL UnhasNo ratings yet
- JulianDocument2 pagesJulianALLAN STEVEN ROMERO RODRIGUEZNo ratings yet
- Practice FileDocument22 pagesPractice Fileএ.বি.এস. আশিকNo ratings yet
- Go To:: Volts (V) Current (A) Resistance (R) WorksheetDocument17 pagesGo To:: Volts (V) Current (A) Resistance (R) Worksheetapi-3738054No ratings yet
- Audiogram: DEXTRADocument1 pageAudiogram: DEXTRAAnonymous vxyyUu0MlZNo ratings yet
- CS ForecastingDocument4 pagesCS ForecastingDe Gala ShailynNo ratings yet
- RegressionDocument12 pagesRegressionHarshit RathourNo ratings yet
- Scatter PlotDocument5 pagesScatter Plotvenkat_19No ratings yet
- Exp7,7 1,6Document3 pagesExp7,7 1,6datta_godbole830No ratings yet
- 2.2 Location Breakeven AnalysisDocument3 pages2.2 Location Breakeven Analysisorenchladee100% (1)
- Formato Aplicacion3.0Document18 pagesFormato Aplicacion3.0Nicolas Bohorquez ZamoranoNo ratings yet
- Tangent ModulusDocument7 pagesTangent ModulusNobel AsresuNo ratings yet
- BD20022 OprDocument12 pagesBD20022 OprDeepNo ratings yet
- Linear Law Linear Programming: By: Ting Hie Huong Lee Mee ChingDocument29 pagesLinear Law Linear Programming: By: Ting Hie Huong Lee Mee ChingAnna LeeNo ratings yet
- Chapter 7: Example 4: Cost-Volume AnalysisDocument2 pagesChapter 7: Example 4: Cost-Volume Analysiscovipanama covidNo ratings yet
- Parcial 2 MicroeconomiaDocument4 pagesParcial 2 MicroeconomiaGarcia HeydiNo ratings yet
- Commitment of Traders ReportDocument14 pagesCommitment of Traders ReportZerohedgeNo ratings yet
- DAX FormulaDocument165 pagesDAX Formulaanon_86752300No ratings yet
- 1395-Monthly Fiscal Bulletin 10 - DariDocument15 pages1395-Monthly Fiscal Bulletin 10 - DariMacro Fiscal PerformanceNo ratings yet
- Es 13 (Laboratory No.2)Document3 pagesEs 13 (Laboratory No.2)Rey JagnaNo ratings yet
- Discofuse EditsDocument1 pageDiscofuse Editspmfcyjf9No ratings yet
- Influencelines Lineas de InfluenciaDocument6 pagesInfluencelines Lineas de Influenciakari20sNo ratings yet
- DN027B Led3ww D100 RDDocument1 pageDN027B Led3ww D100 RDHaianh PhamNo ratings yet
- Punto de Equilibrio: UnidadesDocument2 pagesPunto de Equilibrio: UnidadesKevin A. ChavarriaNo ratings yet
- Oppenheimer Holdings Inc. Annual Report 2010Document52 pagesOppenheimer Holdings Inc. Annual Report 2010lulupupututuNo ratings yet
- Plantilla-Armadura 3D Analisis Estructural Metodo MatricialDocument49 pagesPlantilla-Armadura 3D Analisis Estructural Metodo MatricialRaul DelgadoNo ratings yet
- PTA TerrrrbaruDocument1 pagePTA TerrrrbaruNadhirah AnandaNo ratings yet
- Photoelectric Effect Sim DataDocument5 pagesPhotoelectric Effect Sim DataVital RogatchNo ratings yet
- GC2Document2 pagesGC2Mohammad Rezza PachruraziNo ratings yet
- Fa Marketing Example AnswerDocument3 pagesFa Marketing Example AnswerShirohigeNo ratings yet
- Testing Spreadsheet Vs LRFD Tables: Truss Tr23 YP 29-Dec Sample ConnectionDocument4 pagesTesting Spreadsheet Vs LRFD Tables: Truss Tr23 YP 29-Dec Sample Connectionvijay10484No ratings yet
- AlgebraanswersDocument44 pagesAlgebraanswersAnkitaNo ratings yet
- TransformacionesDocument7 pagesTransformacionesEduardo Miguel Bula OrtegaNo ratings yet
- Grafik Pipa Besar Pipa Besar: V (Laju Alir)Document2 pagesGrafik Pipa Besar Pipa Besar: V (Laju Alir)Dhyrana ShailaNo ratings yet
- Ex 3 - ABP MPDDocument7 pagesEx 3 - ABP MPDdanielmcaeNo ratings yet
- Product 1 - 1000 2023 10 30Document7 pagesProduct 1 - 1000 2023 10 30fbaprecast2508No ratings yet
- Solved - Example 1 Revisit & Example 2 RecordingDocument5 pagesSolved - Example 1 Revisit & Example 2 RecordingMinzaNo ratings yet
- National Institute of Business ManagementDocument10 pagesNational Institute of Business ManagementSonali RajapakseNo ratings yet
- Select Row Labels in Chart, Double Click, Click On Select DataDocument25 pagesSelect Row Labels in Chart, Double Click, Click On Select DataRushilNo ratings yet
- INTI ATOM Dan RADIOAKTIFDocument9 pagesINTI ATOM Dan RADIOAKTIFBaby BunnyNo ratings yet
- Input Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufDocument2 pagesInput Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufMark Anthony Salazar ArcayanNo ratings yet
- Costo Total: Location A Location B Location CDocument9 pagesCosto Total: Location A Location B Location COmara Díaz HerreraNo ratings yet
- Ex1 Basis 0 enDocument45 pagesEx1 Basis 0 enChristiano AugustoNo ratings yet
- 4Q23 Earnings Release - EngDocument17 pages4Q23 Earnings Release - EngProtik MazumdarNo ratings yet
- Constant Total Mass Constant Net ForceDocument4 pagesConstant Total Mass Constant Net ForceErwin CabangalNo ratings yet
- Savoury SnacksDocument2 pagesSavoury Snacksjyotisagar talukdarNo ratings yet
- Online Quiz Round 2 QuestionsDocument5 pagesOnline Quiz Round 2 Questionsjyotisagar talukdarNo ratings yet
- Market Research ApplicationDocument1 pageMarket Research Applicationjyotisagar talukdarNo ratings yet
- Addressable MapDocument1 pageAddressable Mapjyotisagar talukdarNo ratings yet
- QMDocument87 pagesQMjyotisagar talukdarNo ratings yet
- Scanned With CamscannerDocument7 pagesScanned With Camscannerjyotisagar talukdarNo ratings yet
- Key Managerial Personnel: Blue StarDocument4 pagesKey Managerial Personnel: Blue Starjyotisagar talukdarNo ratings yet
- Make in INDIA: Jyoti Sagar Talukdar P19052Document6 pagesMake in INDIA: Jyoti Sagar Talukdar P19052jyotisagar talukdarNo ratings yet
- Session 16,17 and 18Document7 pagesSession 16,17 and 18jyotisagar talukdarNo ratings yet
- Chapter - 8 Professional Education: The Cost RecoveryDocument9 pagesChapter - 8 Professional Education: The Cost RecoveryCorey PageNo ratings yet
- Book 14 PDFDocument242 pagesBook 14 PDFAndres Perez71% (7)
- 600 ngữ pháp chọn lọc luyện thi THPT Quốc GiaDocument32 pages600 ngữ pháp chọn lọc luyện thi THPT Quốc GiaNguyen Chi Cuong100% (1)
- Liberty Secure Travel Plan Details: Cover Sum InsuredDocument1 pageLiberty Secure Travel Plan Details: Cover Sum InsuredMeghaNo ratings yet
- Risk Assessment Techniques (IEC 31010:2019) : Session - 3Document9 pagesRisk Assessment Techniques (IEC 31010:2019) : Session - 3kanchana rameshNo ratings yet
- Song Kiat Chocolate FactoryDocument1 pageSong Kiat Chocolate FactoryKim CuarteroNo ratings yet
- Instrukcja Obsługi TC-6 Felicia - AngielskiDocument24 pagesInstrukcja Obsługi TC-6 Felicia - Angielskiadrianadik100% (2)
- Solved Land in Sonoma California Can Be Used To Either GrowDocument1 pageSolved Land in Sonoma California Can Be Used To Either GrowM Bilal SaleemNo ratings yet
- Experiment No. (6) Study of Dispersion Compensation Schemes: ObjectDocument9 pagesExperiment No. (6) Study of Dispersion Compensation Schemes: ObjectFaez FawwazNo ratings yet
- Napul ResumeDocument2 pagesNapul ResumeNp LbNo ratings yet
- Build RC Rect SectionDocument3 pagesBuild RC Rect SectionOmar NajmNo ratings yet
- 4.-Revised-Tle-As-Css10-Q3-Disk ManagementDocument5 pages4.-Revised-Tle-As-Css10-Q3-Disk ManagementJonald SalinasNo ratings yet
- Robert Walters Salary SurveyDocument5 pagesRobert Walters Salary SurveySyaiful BahriNo ratings yet
- Letter VirajDocument1 pageLetter VirajPratyushAgarwalNo ratings yet
- Raghavendran V Piping Supervisor: ResumeDocument5 pagesRaghavendran V Piping Supervisor: Resumeandi dipayadnyaNo ratings yet
- Fire SafetyDocument31 pagesFire SafetyNaga FireballNo ratings yet
- Clip98 Mathswatch WorkDocument5 pagesClip98 Mathswatch WorkInsertSenseNo ratings yet
- 2 Storey - 4 Classrooms, PUNTAII Elementary School EDITED-2F SANIDocument1 page2 Storey - 4 Classrooms, PUNTAII Elementary School EDITED-2F SANIGin Gineer100% (1)
- FFXV Checklist - HuntsDocument1 pageFFXV Checklist - HuntsarashibirruNo ratings yet
- FDN-218144 Introduction To The Social and Medical Models of DisabilityDocument4 pagesFDN-218144 Introduction To The Social and Medical Models of DisabilityAarya TripathiNo ratings yet
- SLES. ESP - Intervention of Learning Resources K 12 2020Document33 pagesSLES. ESP - Intervention of Learning Resources K 12 2020Catherinei BorilloNo ratings yet
- Avnet TP Sap Arp PL May14Document77 pagesAvnet TP Sap Arp PL May14Kathak DancerNo ratings yet
- 3 - Kamal Sai NelloreDocument3 pages3 - Kamal Sai NelloreDinesh JNo ratings yet
- Comparatives and Superlatives Interactive PracticeDocument5 pagesComparatives and Superlatives Interactive Practiceyenifer sanchezNo ratings yet
- Food ChemistryDocument5 pagesFood ChemistryJames YeohNo ratings yet
- Example Exclusive Patent LicenseDocument13 pagesExample Exclusive Patent LicenseSam Han100% (1)
- Connx October 2008Document2 pagesConnx October 2008ScamsIntrernetNo ratings yet
- Guia de Instalacion MinioDocument18 pagesGuia de Instalacion MinioComercializadora MK ComunicacionesNo ratings yet

























































































Download as pptx, pdf, or txt
You might also like
- AnswerDocument7 pagesAnswerMohd Sharil100% (2)
- Algebra AnswersDocument43 pagesAlgebra AnswersPriya Tripathi79% (19)
- BS en 50600-3-1-2016Document52 pagesBS en 50600-3-1-2016YASNo ratings yet
- Project 5 - Exponential and Logarithmic ProjectDocument7 pagesProject 5 - Exponential and Logarithmic Projectapi-489129243No ratings yet
- Solved - Example 1 Revisit & Example 2 RecordingDocument5 pagesSolved - Example 1 Revisit & Example 2 RecordingMinzaNo ratings yet
- Project 5 PDFDocument3 pagesProject 5 PDFapi-509845050No ratings yet
- DA4675 CFA Level II SmartSheet 2020 PDFDocument10 pagesDA4675 CFA Level II SmartSheet 2020 PDFMabelita Flores100% (3)
- RegressionDocument46 pagesRegressionarpitNo ratings yet
- Session 12Document27 pagesSession 12PRIYADARSHI PANKAJNo ratings yet
- Problem Set 2 SolutionsDocument34 pagesProblem Set 2 SolutionsglavchevanasikNo ratings yet
- PTA TerrrrbaruDocument1 pagePTA TerrrrbaruTHT-BKL UnhasNo ratings yet
- JulianDocument2 pagesJulianALLAN STEVEN ROMERO RODRIGUEZNo ratings yet
- Practice FileDocument22 pagesPractice Fileএ.বি.এস. আশিকNo ratings yet
- Go To:: Volts (V) Current (A) Resistance (R) WorksheetDocument17 pagesGo To:: Volts (V) Current (A) Resistance (R) Worksheetapi-3738054No ratings yet
- Audiogram: DEXTRADocument1 pageAudiogram: DEXTRAAnonymous vxyyUu0MlZNo ratings yet
- CS ForecastingDocument4 pagesCS ForecastingDe Gala ShailynNo ratings yet
- RegressionDocument12 pagesRegressionHarshit RathourNo ratings yet
- Scatter PlotDocument5 pagesScatter Plotvenkat_19No ratings yet
- Exp7,7 1,6Document3 pagesExp7,7 1,6datta_godbole830No ratings yet
- 2.2 Location Breakeven AnalysisDocument3 pages2.2 Location Breakeven Analysisorenchladee100% (1)
- Formato Aplicacion3.0Document18 pagesFormato Aplicacion3.0Nicolas Bohorquez ZamoranoNo ratings yet
- Tangent ModulusDocument7 pagesTangent ModulusNobel AsresuNo ratings yet
- BD20022 OprDocument12 pagesBD20022 OprDeepNo ratings yet
- Linear Law Linear Programming: By: Ting Hie Huong Lee Mee ChingDocument29 pagesLinear Law Linear Programming: By: Ting Hie Huong Lee Mee ChingAnna LeeNo ratings yet
- Chapter 7: Example 4: Cost-Volume AnalysisDocument2 pagesChapter 7: Example 4: Cost-Volume Analysiscovipanama covidNo ratings yet
- Parcial 2 MicroeconomiaDocument4 pagesParcial 2 MicroeconomiaGarcia HeydiNo ratings yet
- Commitment of Traders ReportDocument14 pagesCommitment of Traders ReportZerohedgeNo ratings yet
- DAX FormulaDocument165 pagesDAX Formulaanon_86752300No ratings yet
- 1395-Monthly Fiscal Bulletin 10 - DariDocument15 pages1395-Monthly Fiscal Bulletin 10 - DariMacro Fiscal PerformanceNo ratings yet
- Es 13 (Laboratory No.2)Document3 pagesEs 13 (Laboratory No.2)Rey JagnaNo ratings yet
- Discofuse EditsDocument1 pageDiscofuse Editspmfcyjf9No ratings yet
- Influencelines Lineas de InfluenciaDocument6 pagesInfluencelines Lineas de Influenciakari20sNo ratings yet
- DN027B Led3ww D100 RDDocument1 pageDN027B Led3ww D100 RDHaianh PhamNo ratings yet
- Punto de Equilibrio: UnidadesDocument2 pagesPunto de Equilibrio: UnidadesKevin A. ChavarriaNo ratings yet
- Oppenheimer Holdings Inc. Annual Report 2010Document52 pagesOppenheimer Holdings Inc. Annual Report 2010lulupupututuNo ratings yet
- Plantilla-Armadura 3D Analisis Estructural Metodo MatricialDocument49 pagesPlantilla-Armadura 3D Analisis Estructural Metodo MatricialRaul DelgadoNo ratings yet
- PTA TerrrrbaruDocument1 pagePTA TerrrrbaruNadhirah AnandaNo ratings yet
- Photoelectric Effect Sim DataDocument5 pagesPhotoelectric Effect Sim DataVital RogatchNo ratings yet
- GC2Document2 pagesGC2Mohammad Rezza PachruraziNo ratings yet
- Fa Marketing Example AnswerDocument3 pagesFa Marketing Example AnswerShirohigeNo ratings yet
- Testing Spreadsheet Vs LRFD Tables: Truss Tr23 YP 29-Dec Sample ConnectionDocument4 pagesTesting Spreadsheet Vs LRFD Tables: Truss Tr23 YP 29-Dec Sample Connectionvijay10484No ratings yet
- AlgebraanswersDocument44 pagesAlgebraanswersAnkitaNo ratings yet
- TransformacionesDocument7 pagesTransformacionesEduardo Miguel Bula OrtegaNo ratings yet
- Grafik Pipa Besar Pipa Besar: V (Laju Alir)Document2 pagesGrafik Pipa Besar Pipa Besar: V (Laju Alir)Dhyrana ShailaNo ratings yet
- Ex 3 - ABP MPDDocument7 pagesEx 3 - ABP MPDdanielmcaeNo ratings yet
- Product 1 - 1000 2023 10 30Document7 pagesProduct 1 - 1000 2023 10 30fbaprecast2508No ratings yet
- Solved - Example 1 Revisit & Example 2 RecordingDocument5 pagesSolved - Example 1 Revisit & Example 2 RecordingMinzaNo ratings yet
- National Institute of Business ManagementDocument10 pagesNational Institute of Business ManagementSonali RajapakseNo ratings yet
- Select Row Labels in Chart, Double Click, Click On Select DataDocument25 pagesSelect Row Labels in Chart, Double Click, Click On Select DataRushilNo ratings yet
- INTI ATOM Dan RADIOAKTIFDocument9 pagesINTI ATOM Dan RADIOAKTIFBaby BunnyNo ratings yet
- Input Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufDocument2 pagesInput Voltage 50 Vrms Resistor 20 Ohms Capacitor 35ufMark Anthony Salazar ArcayanNo ratings yet
- Costo Total: Location A Location B Location CDocument9 pagesCosto Total: Location A Location B Location COmara Díaz HerreraNo ratings yet
- Ex1 Basis 0 enDocument45 pagesEx1 Basis 0 enChristiano AugustoNo ratings yet
- 4Q23 Earnings Release - EngDocument17 pages4Q23 Earnings Release - EngProtik MazumdarNo ratings yet
- Constant Total Mass Constant Net ForceDocument4 pagesConstant Total Mass Constant Net ForceErwin CabangalNo ratings yet
- Savoury SnacksDocument2 pagesSavoury Snacksjyotisagar talukdarNo ratings yet
- Online Quiz Round 2 QuestionsDocument5 pagesOnline Quiz Round 2 Questionsjyotisagar talukdarNo ratings yet
- Market Research ApplicationDocument1 pageMarket Research Applicationjyotisagar talukdarNo ratings yet
- Addressable MapDocument1 pageAddressable Mapjyotisagar talukdarNo ratings yet
- QMDocument87 pagesQMjyotisagar talukdarNo ratings yet
- Scanned With CamscannerDocument7 pagesScanned With Camscannerjyotisagar talukdarNo ratings yet
- Key Managerial Personnel: Blue StarDocument4 pagesKey Managerial Personnel: Blue Starjyotisagar talukdarNo ratings yet
- Make in INDIA: Jyoti Sagar Talukdar P19052Document6 pagesMake in INDIA: Jyoti Sagar Talukdar P19052jyotisagar talukdarNo ratings yet
- Session 16,17 and 18Document7 pagesSession 16,17 and 18jyotisagar talukdarNo ratings yet
- Chapter - 8 Professional Education: The Cost RecoveryDocument9 pagesChapter - 8 Professional Education: The Cost RecoveryCorey PageNo ratings yet
- Book 14 PDFDocument242 pagesBook 14 PDFAndres Perez71% (7)
- 600 ngữ pháp chọn lọc luyện thi THPT Quốc GiaDocument32 pages600 ngữ pháp chọn lọc luyện thi THPT Quốc GiaNguyen Chi Cuong100% (1)
- Liberty Secure Travel Plan Details: Cover Sum InsuredDocument1 pageLiberty Secure Travel Plan Details: Cover Sum InsuredMeghaNo ratings yet
- Risk Assessment Techniques (IEC 31010:2019) : Session - 3Document9 pagesRisk Assessment Techniques (IEC 31010:2019) : Session - 3kanchana rameshNo ratings yet
- Song Kiat Chocolate FactoryDocument1 pageSong Kiat Chocolate FactoryKim CuarteroNo ratings yet
- Instrukcja Obsługi TC-6 Felicia - AngielskiDocument24 pagesInstrukcja Obsługi TC-6 Felicia - Angielskiadrianadik100% (2)
- Solved Land in Sonoma California Can Be Used To Either GrowDocument1 pageSolved Land in Sonoma California Can Be Used To Either GrowM Bilal SaleemNo ratings yet
- Experiment No. (6) Study of Dispersion Compensation Schemes: ObjectDocument9 pagesExperiment No. (6) Study of Dispersion Compensation Schemes: ObjectFaez FawwazNo ratings yet
- Napul ResumeDocument2 pagesNapul ResumeNp LbNo ratings yet
- Build RC Rect SectionDocument3 pagesBuild RC Rect SectionOmar NajmNo ratings yet
- 4.-Revised-Tle-As-Css10-Q3-Disk ManagementDocument5 pages4.-Revised-Tle-As-Css10-Q3-Disk ManagementJonald SalinasNo ratings yet
- Robert Walters Salary SurveyDocument5 pagesRobert Walters Salary SurveySyaiful BahriNo ratings yet
- Letter VirajDocument1 pageLetter VirajPratyushAgarwalNo ratings yet
- Raghavendran V Piping Supervisor: ResumeDocument5 pagesRaghavendran V Piping Supervisor: Resumeandi dipayadnyaNo ratings yet
- Fire SafetyDocument31 pagesFire SafetyNaga FireballNo ratings yet
- Clip98 Mathswatch WorkDocument5 pagesClip98 Mathswatch WorkInsertSenseNo ratings yet
- 2 Storey - 4 Classrooms, PUNTAII Elementary School EDITED-2F SANIDocument1 page2 Storey - 4 Classrooms, PUNTAII Elementary School EDITED-2F SANIGin Gineer100% (1)
- FFXV Checklist - HuntsDocument1 pageFFXV Checklist - HuntsarashibirruNo ratings yet
- FDN-218144 Introduction To The Social and Medical Models of DisabilityDocument4 pagesFDN-218144 Introduction To The Social and Medical Models of DisabilityAarya TripathiNo ratings yet
- SLES. ESP - Intervention of Learning Resources K 12 2020Document33 pagesSLES. ESP - Intervention of Learning Resources K 12 2020Catherinei BorilloNo ratings yet
- Avnet TP Sap Arp PL May14Document77 pagesAvnet TP Sap Arp PL May14Kathak DancerNo ratings yet
- 3 - Kamal Sai NelloreDocument3 pages3 - Kamal Sai NelloreDinesh JNo ratings yet
- Comparatives and Superlatives Interactive PracticeDocument5 pagesComparatives and Superlatives Interactive Practiceyenifer sanchezNo ratings yet
- Food ChemistryDocument5 pagesFood ChemistryJames YeohNo ratings yet
- Example Exclusive Patent LicenseDocument13 pagesExample Exclusive Patent LicenseSam Han100% (1)
- Connx October 2008Document2 pagesConnx October 2008ScamsIntrernetNo ratings yet
- Guia de Instalacion MinioDocument18 pagesGuia de Instalacion MinioComercializadora MK ComunicacionesNo ratings yet