Download as pptx, pdf, or txt
You might also like
- DBMS 2Document33 pagesDBMS 2Karneshwar SannamaniNo ratings yet
- Module II: Relational Database & ER ModelDocument41 pagesModule II: Relational Database & ER ModelIshika SinghalNo ratings yet
- Moving From ER Model To Relational ModelDocument23 pagesMoving From ER Model To Relational ModelrosaliaNo ratings yet
- Presentation3 ER Model GeneralisationDocument91 pagesPresentation3 ER Model GeneralisationSatyam Kumar SinghNo ratings yet
- DBMS FileDocument14 pagesDBMS FilebeastthehoodNo ratings yet
- Database Design: Chapter ThreeDocument51 pagesDatabase Design: Chapter ThreemeryemNo ratings yet
- Chapter 2 Data ModelsDocument75 pagesChapter 2 Data Modelsrisksentinel.objNo ratings yet
- Database Mba NOTESDocument35 pagesDatabase Mba NOTESWasim Ahamad KhanNo ratings yet
- Lesson 2Document7 pagesLesson 2kurtluisllanes2No ratings yet
- L2 Database ModelsDocument43 pagesL2 Database Modelsnjamaa91No ratings yet
- Chapter 3 - RELATIONAL DATA MODEL - Initial - Version1Document113 pagesChapter 3 - RELATIONAL DATA MODEL - Initial - Version12028110No ratings yet
- Database Management System: Arpit MadaanDocument35 pagesDatabase Management System: Arpit MadaanArpit MadaanNo ratings yet
- Unit 1 Data Models EDocument75 pagesUnit 1 Data Models EVijay KrishnaNo ratings yet
- Database Management System: Nishant KumarDocument35 pagesDatabase Management System: Nishant KumarRaj KundraNo ratings yet
- Date Base Management SystemDocument20 pagesDate Base Management SystemSwati PariharNo ratings yet
- DBMS Unit - 2 - Notes PDFDocument20 pagesDBMS Unit - 2 - Notes PDFMITALI MATHUR (RA1911003030169)No ratings yet
- Lab 01Document16 pagesLab 01muhammadsaeedrasheedNo ratings yet
- Chapter 02 DBADocument33 pagesChapter 02 DBAHamza khanNo ratings yet
- Database Management System: Introduction To DBMS Ms. Deepikkaa.SDocument45 pagesDatabase Management System: Introduction To DBMS Ms. Deepikkaa.SMukunth88No ratings yet
- Chapter 2. The Relational Model: ObjectivesDocument37 pagesChapter 2. The Relational Model: ObjectivesEzzaddin SultanNo ratings yet
- Unit 3Document30 pagesUnit 3atharvnawale05No ratings yet
- Dbms Notes 1Document69 pagesDbms Notes 1life hackerNo ratings yet
- Database SystemDocument58 pagesDatabase SystemDr. Hitesh MohapatraNo ratings yet
- Unit 2 DBMS Class 12 Computer ScienceDocument12 pagesUnit 2 DBMS Class 12 Computer Sciencegautamsunischal02No ratings yet
- DBMS-Unit IDocument95 pagesDBMS-Unit IPatkar MumbaiNo ratings yet
- Technical Questions Based On Database Management SystemDocument26 pagesTechnical Questions Based On Database Management SystemShail SinghNo ratings yet
- SQL TutorialDocument207 pagesSQL TutorialMd FasiuddinNo ratings yet
- Final - Chap3 - Relational ModelDocument55 pagesFinal - Chap3 - Relational ModelDevika DakhoreNo ratings yet
- 2 Data ModelsDocument60 pages2 Data Modelsjonnathan mandelaNo ratings yet
- Unit 4: Database Design & DevelopmentDocument122 pagesUnit 4: Database Design & Developmentshabir AhmadNo ratings yet
- DBMSDocument20 pagesDBMSRoman BhattaraiNo ratings yet
- Chapter 7-1Document4 pagesChapter 7-1HgfdgNo ratings yet
- Dbms Introduction 108Document39 pagesDbms Introduction 108lanilyn mongadoNo ratings yet
- InfoMan-Week 8-Relational-Model2021Document26 pagesInfoMan-Week 8-Relational-Model2021Sherwin LimboNo ratings yet
- DB2 - IBM's Relational DBMSDocument167 pagesDB2 - IBM's Relational DBMSvictorynarenNo ratings yet
- STAT 624 Computing Tools For Data Science: Module 1: Relational DatabasesDocument32 pagesSTAT 624 Computing Tools For Data Science: Module 1: Relational DatabasesManuel Alberto Pérez P.No ratings yet
- Ucse253l Dbms Module 1Document11 pagesUcse253l Dbms Module 1Senthil PrakashNo ratings yet
- U4 Database Management System (DBMS)Document31 pagesU4 Database Management System (DBMS)Arun MishraNo ratings yet
- Dbms Complete NotesDocument781 pagesDbms Complete NotesSreejaNo ratings yet
- Unit 9 Fundamentals of DatabaseDocument28 pagesUnit 9 Fundamentals of Databasevc78it10No ratings yet
- ch-1 - Introduction To DbmsDocument38 pagesch-1 - Introduction To DbmsRahul SharmaNo ratings yet
- Unit I - DBMSDocument12 pagesUnit I - DBMSrajamaheshNo ratings yet
- Types of DatabasesDocument35 pagesTypes of DatabasesrosaliaNo ratings yet
- BICTE Dbms SolDocument7 pagesBICTE Dbms SolSamjhana LamaNo ratings yet
- SQL Material PDFDocument55 pagesSQL Material PDFKhalid Mohammed100% (1)
- DCICT 2 DatabasesDocument26 pagesDCICT 2 DatabasesyoweemagamboNo ratings yet
- Dbms Pyq Solution 2019Document13 pagesDbms Pyq Solution 2019swetaNo ratings yet
- Oracle 9i NotesDocument88 pagesOracle 9i NotesswamymerguNo ratings yet
- DBMS BasicsDocument25 pagesDBMS BasicsNikita ParidaNo ratings yet
- Unit 1 Understanding Database SystemDocument110 pagesUnit 1 Understanding Database SystemAsmatullah KhanNo ratings yet
- Module3 DbmsDocument192 pagesModule3 DbmsVaidehi VermaNo ratings yet
- Oracle 9i NotesDocument76 pagesOracle 9i NotesNaveen100% (3)
- 1.architecture of DBMSDocument25 pages1.architecture of DBMSAyush Pratap SinghNo ratings yet
- Data Base Management SystemDocument180 pagesData Base Management SystemRajam100% (1)
- DBMS 2nd SemesterDocument74 pagesDBMS 2nd SemesterTanverul Islam MukulNo ratings yet
- Databases 2Document30 pagesDatabases 2Shahzeb BashirNo ratings yet
- DBMS NotesDocument180 pagesDBMS NotesRajamNo ratings yet
- DBMS Module-1Document36 pagesDBMS Module-1Krittika HegdeNo ratings yet
- “Mastering Relational Databases: From Fundamentals to Advanced Concepts”: GoodMan, #1From Everand“Mastering Relational Databases: From Fundamentals to Advanced Concepts”: GoodMan, #1No ratings yet
- SQL Programming & Database Management For Absolute Beginners: SQL Server, Structured Query Language Fundamentals: "Learn - By Doing" Approach And Master SQLFrom EverandSQL Programming & Database Management For Absolute Beginners: SQL Server, Structured Query Language Fundamentals: "Learn - By Doing" Approach And Master SQLNo ratings yet
- Functional Dependency: Hassan KhanDocument16 pagesFunctional Dependency: Hassan KhanHassan KhanNo ratings yet
- Relational Model Concept: Hassan KhanDocument29 pagesRelational Model Concept: Hassan KhanHassan KhanNo ratings yet
- LECTURE 6 (Integrity Constraints)Document11 pagesLECTURE 6 (Integrity Constraints)Hassan KhanNo ratings yet
- Join Operations: Hassan KhanDocument14 pagesJoin Operations: Hassan KhanHassan KhanNo ratings yet
- Da Tabase Management System: Hassan KhanDocument11 pagesDa Tabase Management System: Hassan KhanHassan KhanNo ratings yet
- 3 5 - Features 2 01042020 122302amDocument19 pages3 5 - Features 2 01042020 122302amHassan KhanNo ratings yet
- Da Tabase Management System: Hassan KhanDocument11 pagesDa Tabase Management System: Hassan KhanHassan KhanNo ratings yet
- Assignment # 1 Pattern Recognition: Hassan Khan 02-243182-016 057597Document4 pagesAssignment # 1 Pattern Recognition: Hassan Khan 02-243182-016 057597Hassan KhanNo ratings yet
- Prak. Section 2 Transforming From Conceptual Model To Physical ModelDocument7 pagesPrak. Section 2 Transforming From Conceptual Model To Physical ModelOkaNo ratings yet
- Database Management Systems - (Contents)Document12 pagesDatabase Management Systems - (Contents)cherrynessmorenoNo ratings yet
- 6 Relational Database DesignDocument9 pages6 Relational Database DesignAmrit BabuNo ratings yet
- Ism FDocument128 pagesIsm FAmit GuptaNo ratings yet
- Sample Table - Worker: Perform Following SQL QueriesDocument2 pagesSample Table - Worker: Perform Following SQL QueriesNeeraj SharmaNo ratings yet
- Employees SQLDocument3 pagesEmployees SQLSweety ChaddhaNo ratings yet
- DBS Assignment QuestionDocument6 pagesDBS Assignment Questionyongqi.gifNo ratings yet
- Assignment # 2 Database Management System: National University of Modern LanguagesDocument5 pagesAssignment # 2 Database Management System: National University of Modern LanguagesSyed Jarar Ali BukhariNo ratings yet
- Ch14 Databases Connection in JavaDocument62 pagesCh14 Databases Connection in JavashatrozlmNo ratings yet
- Structured Query LanguageDocument2 pagesStructured Query LanguageNimisha SaraswatNo ratings yet
- Yelp DatasetDocument9 pagesYelp DatasetToiletterNo ratings yet
- DataTable and Its Methods inDocument5 pagesDataTable and Its Methods initprabhu.automationNo ratings yet
- Oracle SQL NotesDocument3 pagesOracle SQL NotesgadhireddyNo ratings yet
- Phase 1 Individual Project Assignment #1 Sheku SesayDocument7 pagesPhase 1 Individual Project Assignment #1 Sheku SesayAlve RaimondNo ratings yet
- Student Guide Volume 2 Advanced SQLDocument36 pagesStudent Guide Volume 2 Advanced SQLapi-3748459No ratings yet
- Database: Fatima Jinnah Women University, RawalpindiDocument5 pagesDatabase: Fatima Jinnah Women University, RawalpindiAttia HumairaNo ratings yet
- Topic 7 An Introduction To SQLDocument52 pagesTopic 7 An Introduction To SQLflower boomNo ratings yet
- 3 - Database - RelationshipDocument19 pages3 - Database - RelationshipphannarithNo ratings yet
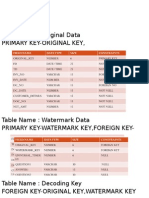
- Table Name: Original Data Primary Key-Original Key, Foreign Key-Invoice No, DC - NoDocument4 pagesTable Name: Original Data Primary Key-Original Key, Foreign Key-Invoice No, DC - Noanand_gsoft3603No ratings yet
- Ho Chi Minh City University of Transport: Exercises Database Systems - 2021 /nvdieuDocument7 pagesHo Chi Minh City University of Transport: Exercises Database Systems - 2021 /nvdieuHiếu ĐoànNo ratings yet
- Constraints in OracleDocument16 pagesConstraints in OraclePrasanthi KolliNo ratings yet
- SQL Lab 1: ObjectiveDocument8 pagesSQL Lab 1: Objectivepramod198965No ratings yet
- Course - Database Management Systems (DBMS) : Course Instructor Dr. K. Subrahmanyam Department of CSE, KLUDocument92 pagesCourse - Database Management Systems (DBMS) : Course Instructor Dr. K. Subrahmanyam Department of CSE, KLUAvinash AllaNo ratings yet
- Javeria Ismail (20) Database MCQsDocument3 pagesJaveria Ismail (20) Database MCQsMehwish ShabbirNo ratings yet
- Chapter 6: The Relational Algebra and Relational Calculus: Answers To Selected ExercisesDocument4 pagesChapter 6: The Relational Algebra and Relational Calculus: Answers To Selected Exercisessaumya tiwariNo ratings yet
- HSC ICT Sheet Chapter 06Document10 pagesHSC ICT Sheet Chapter 06Khalad Khan67% (3)
- Brief History of The Relational ModelDocument5 pagesBrief History of The Relational ModelSaleem KhanNo ratings yet
- DBMS MicroDocument13 pagesDBMS Microgajjelanavya879No ratings yet
- Chapter 3 SQLDocument59 pagesChapter 3 SQLdinaras bekeleNo ratings yet